一种基于多层时序滤波的目标跟踪方法与流程
本发明涉及计算机视觉,人工智能,模式识别与智能系统技术领域。
背景技术:
视觉目标跟踪是计算机视觉领域的重要研究课题,其主要任务是获取目标连续的位置、外观和运动等信息,进而为进一步的语义层分析(如行为识别、场景理解等)提供基础。目标跟踪研究被广泛应用于智能监控、人机交互、自动控制系统等领域,具有很强的实用价值。目前,目标跟踪方法主要包括经典目标跟踪方法和深度学习目标跟踪方法。
经典的目标跟踪方法主要分为生成式方法(generativemethods)和判别式方法(discriminativemethods)两类。生成式方法假设目标可以通过某种生成过程或者模型进行表达,如主成分分析(pca),稀疏编码(sparsecoding)等,然后将跟踪问题视为在感兴趣的区域中寻找最可能的候选项。这些方法旨在设计一种利于鲁棒目标跟踪的图像表示方法。不同于生成式方法,判别式方法将跟踪视为一个分类或者一种连续的对象检测问题,其任务是将目标从图像背景中分辨出来。这类方法同时利用目标和背景信息,是目前主要研究的一类方法。判别式方法通常包含两个主要的步骤,第一步是通过选择能够辨别目标和背景的视觉特征训练得到一个分类器及其决策规则,第二步是在跟踪过程中将该分类器用于对视场内的每一个位置进行评价并确定最有可能的目标位置。随后将目标框移动到该位置并重复这样的过程,进而实现跟踪,该框架被用于设计出各种形式的跟踪算法。总体来看,经典跟踪方法的主要优势在于运行速度和对辅助数据较少的依赖,同时它们也需要在跟踪的准确性与实时性之间做出权衡。
深度学习(deeplearning)是近年来机器学习研究的热点,由于其强大的特征表达能力和不断发展的数据集和硬件支持,深度学习已在许多方面取得了惊人的成功,例如语音识别、图像识别、目标检测、视频分类等。深度学习目标跟踪研究发展也十分迅速,但由于目标跟踪中先验知识的缺乏和实时性的要求,使得需要大量训练数据和参数计算为基础的深度学习技术在这方面难以得到充分的施展,具有很大的探索空间。从目前的研究成果来看,深度学习跟踪方法主要应用了自编码器网络和卷积神经网络,其研究主要有两种思路,一种是对网络进行迁移学习再进行在线微调,另一种是改造深度网络的结构以适应跟踪的要求。自编码器网络(ae)是典型的非监督深度学习网络,因其特征学习能力和抗噪声性能被首先应用到目标跟踪中。综合来看,自编码器网络比较直观且体量适中,是一种优秀的非监督深度学习模型,在跟踪中最先得以应用并取得了较好的效果。与自编码器网络不同,卷积神经网络(cnn)是一种监督型的前馈神经网络,它包含多个循环交替进行的卷积、非线性变换和降采样操作,在模式识别特别是计算机视觉任务中体现出非常强大的性能。总体来看,深度学习相比于经典方法具有更强大的特征表达能力,其跟踪方法中有关训练集的选取,网络的选择与结构的改进,算法的实时性,以及应用循环神经网络等方面仍需要进一步的研究。
技术实现要素:
本发明的目的是提供一种基于多层时序滤波的目标跟踪方法,它能有效地解决跟踪目标消失后重新出现时的再定位和跟踪目标的技术问题。
本发明的目的是通过以下技术方案来实现的:
1、一种基于多层时序滤波的目标跟踪方法,包括如下步骤:
步骤一、目标选取
从初始图像中选择并确定要跟踪的目标对象,提取其目标图像块;目标选取过程通过运动目标检测方法自动提取,或者通过人机交互方法手动指定;
步骤二、多层时序滤波网络构建
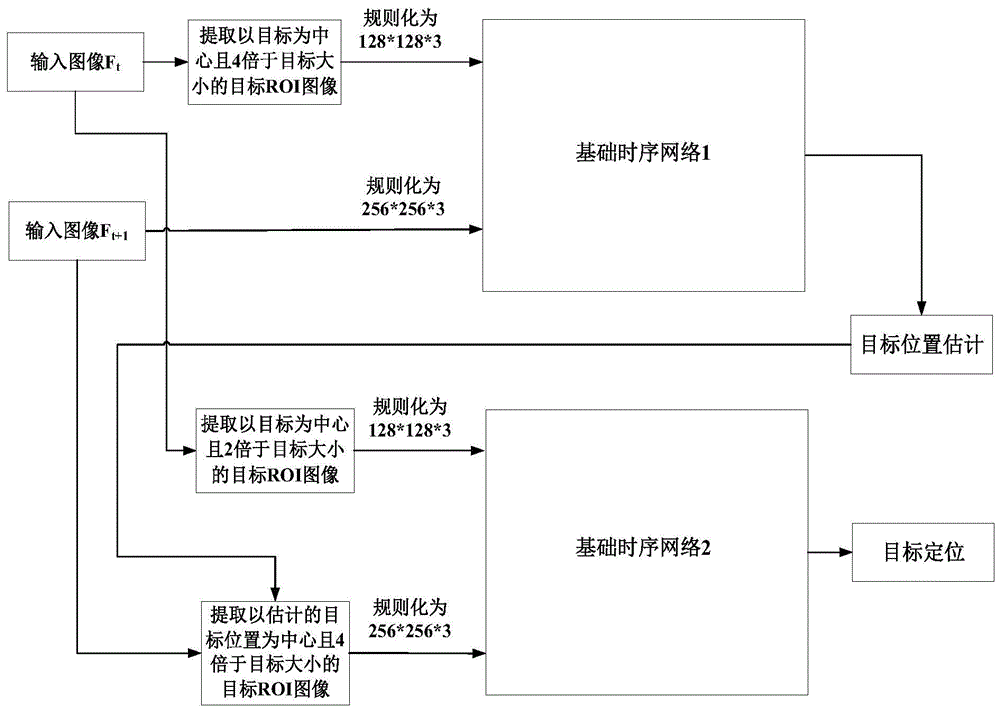
所述多层时序滤波网络包括并列的两个基础时序网络,记为基础时序网络1和基础时序网络2,它们具有相同的网络结构;
所述基础时序网络采用vgg-16网络的block3-conv1层和block4-conv3层作为空间特征提取部分,采用lstm网络作为时间特征提取部分;基础时序网络的输入为两个包含目标的关注区域图像,即两个目标roi图像,第一个目标roi图像规则化为128*128*3像素大小,第二个目标roi图像规则化为256*256*3像素大小;在基础时序网络中,第一个目标roi图像和第二个目标roi图像经vgg-16网络正向处理后分别输出block3-conv1层和block4-conv3层的节点值,将这两层节点值分别作为lstm网络的输入,经lstm网络正向处理后输出两个对应的隐含层节点值,将这两个隐含层节点值分别通过1*1*256像素的卷积后获得两个对应的时间特征值;将第一个目标roi图像对应的第一个时间特征值与第二个目标roi图像对应的第一个时间特征值进行卷积,获得响应图l;将第一个目标roi图像对应的第二个时间特征值与第二个目标roi图像对应的第二个时间特征值进行卷积,获得响应图h;将响应图h规则化为33*33像素大小后与响应图l合并,输出目标响应图r;输入基础时序网络1的第一和第二目标roi图像分别为,当前帧图像ft中以目标为中心且4倍于目标大小提取的目标roi图像和下一帧图像ft+1;输入基础时序网络2的第一和第二目标roi图像分别为,当前帧图像ft中以目标为中心且2倍于目标大小提取的目标roi图像和下一帧图像ft+1中以根据基础时序网络1输出的目标响应图r估计的目标位置为中心且4倍于目标大小提取的目标roi图像;
步骤三、多层时序滤波网络训练
这里采用imagenet视频数据集对多层时序滤波网络进行训练,即对基础时序网络1和基础时序网络2分别采用imagenet视频数据集进行训练;训练方法采用adam优化方法,即深度神经网络训练方法;训练完成后,所述多层时序滤波网络具备目标定位能力;
步骤四、图像输入
在实时处理情况下,提取通过摄像头采集并保存在存储区的视频图像,作为要进行跟踪的输入图像;在离线处理情况下,将已采集的视频文件分解为多个帧组成的图像序列,按照时间顺序,逐个提取帧图像作为输入图像;如果输入图像为空,则整个流程中止;
步骤五、目标位置估计
通过基础时序网络1对目标位置进行初步的估计;如果是第一次跟踪,则将步骤一中的初始图像作为ft,将当前输入的帧图像作为ft+1,如果不是第一次跟踪,则将上一帧图像作为ft,将当前输入的帧图像作为ft+1,然后将ft中以目标为中心且4倍于目标大小提取的第一目标roi图像和将ft+1直接作为第二目标roi图像输入基础时序网络1,经基础时序网络1正向处理后输出得到其对应的目标响应图;将该目标响应图中最大值所对应的位置作为目标的滤波位置,然后将该位置按照33*33像素到ft+1图像大小的比例关系变换为其对应在ft+1中的位置,并将该位置作为估计的目标位置;
步骤六、目标定位
通过基础时序网络2对目标进行准确的定位;如果是第一次跟踪,则将步骤一中的初始图像作为ft,将当前输入的帧图像作为ft+1,如果不是第一次跟踪,则将上一帧图像作为ft,将当前输入的帧图像作为ft+1,然后将ft中以目标为中心且2倍于目标大小提取的第一目标roi图像和ft+1中以步骤五中所述的估计的目标位置为中心且4倍于目标大小提取的第二目标roi图像输入基础时序网络2,经基础时序网络2正向处理后输出得到其对应的目标响应图;将该目标响应图中最大值所对应的位置作为目标的滤波位置,然后将该位置按照33*33像素到ft+1图像大小的比例关系变换为其对应在ft+1中的位置,并将该位置作为当前定位的目标位置,目标定位完成;跳转到步骤四。
与现有技术相比的优点和效果:
该方法首先构建一个多层时序滤波网络,该网络由两个具有相同结构的基础时序网络构成。第一个基础时序网络实现对目标的初步定位,即目标位置估计,第二个基础时序网络实现对目标的准确定位,进而实现跟踪任务。整个网络通过使用imagenet的视频数据集完成训练,而跟踪时网络无需在线学习。本发明方法利用深度卷积神经网络结合循环神经网络学习丰富的时空特征,有利于提高目标跟踪的鲁棒性,同时采用滤波方法使得深度神经网络在跟踪过程中无需在线学习,弥补了深度学习方法在进行目标跟踪时实时性不足的问题,可实现实时的目标跟踪。此外,深度神经网络不同层的特征所表达的信息有所不同,越往高层,其特征越趋于包含抽象语义信息,越往低层,其特征越趋于包含图像的局部细节信息,本发明合理使用了网络的不同层特征,因此更有利于对目标的表达和辨识,进而提高目标定位和跟踪的准确性。由于采用了两个阶段由粗到细的目标定位方式,即首先从整个图像范围确定目标所在区域,再缩小搜索范围进一步定位目标位置,使得本发明方法一方面具备一定的恢复跟踪能力,即当目标消失后重新出现时可以重新定位和跟踪目标,另一方面可以更加准确的确定目标所在的位置。
附图说明
图1为本发明多层时序滤波网络结构图
图2为本发明基础时序网络结构图
图3为本发明的流程图
具体实施方式
实施例:
本发明的方法可用于目标跟踪的各种场合,如智能视频分析,自动人机交互,交通视频监控,无人车辆驾驶,生物群体分析,以及流体表面测速等。下面根据附图对本发明做进一步描述:
如图1和图2所示:所述基础时序网络采用vgg-16网络的block3-conv1层和block4-conv3层作为空间特征提取部分,采用lstm网络作为时间特征提取部分;基础时序网络的输入为两个包含目标的关注区域图像,即两个目标roi图像,第一个目标roi图像规则化为128*128*3像素大小,第二个目标roi图像规则化为256*256*3像素大小;在基础时序网络中,第一个目标roi图像和第二个目标roi图像经vgg-16网络正向处理后分别输出它们对应的block3-conv1层和block4-conv3层的节点值。第一个目标roi图像对应的block3-conv1层和block4-conv3层的节点值分别为32*32*256像素大小和16*16*512像素大小,第二个目标roi图像对应的block3-conv1层和block4-conv3层的节点值分别为64*64*256像素大小和32*32*512像素大小。将block3-conv1层和block4-conv3层两层的节点值分别作为lstm网络的输入,经lstm网络正向处理后输出两个对应的隐含层节点值,将这两个隐含层节点值分别通过1*1*256像素的卷积后获得两个对应的时间特征值;将第一个目标roi图像对应的第一个时间特征值与第二个目标roi图像对应的第一个时间特征值进行卷积,获得响应图l,其大小为33*33像素大小;将第一个目标roi图像对应的第二个时间特征值与第二个目标roi图像对应的第二个时间特征值进行卷积,获得响应图h,其大小为17*17像素大小;将响应图h规则化为33*33像素大小后与响应图l合并,输出目标响应图r;输入基础时序网络1的第一和第二目标roi图像分别为,图像ft中以目标为中心且4倍于目标大小提取的目标roi图像和图像ft+1,如果是第一次跟踪,则将步骤一中的初始图像作为ft,将当前输入的帧图像作为ft+1,如果不是第一次跟踪,则将上一帧图像作为ft,将当前输入的帧图像作为ft+1;输入基础时序网络2的第一和第二目标roi图像分别为,图像ft中以目标为中心且2倍于目标大小提取的目标roi图像和图像ft+1中以根据基础时序网络1输出的目标响应图r估计的目标位置为中心且4倍于目标大小提取的目标roi图像,如果是第一次跟踪,则将步骤一中的初始图像作为ft,将当前输入的帧图像作为ft+1,如果不是第一次跟踪,则将上一帧图像作为ft,将当前输入的帧图像作为ft+1;
以智能视频分析为例:智能视频分析包含许多重要的自动分析任务,如行为分析,异常报警,视频压缩等,而这些工作的基础则是能够进行稳定的目标跟踪。可以采用本发明提出的跟踪方法实现,具体来说,首先构建一个多层时序滤波网络,如图1所示,它由两个具有相同结构的基础时序网络构成,然后使用imagenet的视频数据集对该网络进行训练,使其具备目标定位能力。跟踪时,通过基础时序网络1对目标位置进行初步的估计,如果是第一次跟踪,则将步骤一中的初始图像作为ft,将当前输入的帧图像作为ft+1,如果不是第一次跟踪,则将上一帧图像作为ft,将当前输入的帧图像作为ft+1,然后将ft中以目标为中心且4倍于目标大小提取的第一目标roi图像和将ft+1直接作为第二目标roi图像输入基础时序网络1,经基础时序网络1正向处理后输出得到其对应的目标响应图。将该目标响应图中最大值所对应的位置作为目标的滤波位置,然后将该位置按照33*33像素到ft+1图像大小的比例关系变换为其对应在ft+1中的位置,并将该位置作为估计的目标位置。接着,通过基础时序网络2对目标进行准确的定位,如果是第一次跟踪,则将步骤一中的初始图像作为ft,将当前输入的帧图像作为ft+1,如果不是第一次跟踪,则将上一帧图像作为ft,将当前输入的帧图像作为ft+1,然后将ft中以目标为中心且2倍于目标大小提取的第一目标roi图像和ft+1中以步骤五中所述的估计的目标位置为中心且4倍于目标大小提取的第二目标roi图像输入基础时序网络2,经基础时序网络2正向处理后输出得到其对应的目标响应图;将该目标响应图中最大值所对应的位置作为目标的滤波位置,然后将该位置按照33*33像素到ft+1图像大小的比例关系变换为其对应在ft+1中的位置,并将该位置作为当前定位的目标位置,完成目标定位,进而实现跟踪。本发明方法利用深度卷积神经网络结合循环神经网络学习丰富的时空特征,有利于提高目标跟踪的鲁棒性,同时采用滤波方法使得深度神经网络在跟踪过程中无需在线学习,弥补了深度学习方法在进行目标跟踪时实时性不足的问题,可实现实时的目标跟踪。此外,深度神经网络不同层的特征所表达的信息有所不同,越往高层,其特征越趋于包含抽象语义信息,越往低层,其特征越趋于包含图像的局部细节信息,本发明合理使用了网络的不同层特征,因此更有利于对目标的表达和辨识,进而提高目标定位和跟踪的准确性。由于采用了两个阶段由粗到细的目标定位方式,即首先从整个图像范围确定目标所在区域,再缩小搜索范围进一步定位目标位置,使得本发明方法一方面具备一定的恢复跟踪能力,即当目标消失后重新出现时可以重新定位和跟踪目标,另一方面可以更加准确的确定目标所在的位置。
本发明方法可通过任何计算机程序设计语言(如c语言)编程实现,基于本方法的跟踪系统软件可在任何pc或者嵌入式系统中实现实时目标跟踪应用。
- 还没有人留言评论。精彩留言会获得点赞!