一种基于多目标关联深度推理的图像问答方法与流程
本发明涉及一种针对图像问答(Visual Question Answering)任 务的深度神经网络结构,尤其涉及一种对图像-问答的数据进行统一 建模,寻找图像内各实体特征和相对应空间位置几何特征之间的相 互作用关系,通过对它们之间的位置关系建模,达到适应性调整注 意力权重的方法。
背景技术:
图像问答是一项交叉计算机视觉和自然语言处理的新兴任务。 该任务旨在通过给定一个与图像相关的问题,让机器能自动回答相 应的答案。和另一计算机视觉和自然语言处理的交叉任务——图像 描述相比,需要机器能够通过理解图像和问题并推理得到正确的结 果,因此图像问答任务无疑更为复杂。如“她的眼镜是什么颜色?” 这样的句子包含了丰富的语义信息。机器为了回答这一问题,首先 需要在图像中定位到女性眼部所在的区域,然后根据“颜色”这一 关键词进行回答。再如“胡须是由什么制作的?”这一问题,机器需 要无法直接找到胡须所在位置,但是可以根据人脸的位置估计到胡 须应该在的区域并对该区域进行关注。然后根据关键词“制作”回 答这一问题。
随着深度学习在近年来的迅速发展,使用深度卷积神经网络 (Convolutional Neural Networks,CNN)或深度循环神经网络 (Recurrent Neural Networks,RNN)进行端到端(end-to-end)地建 模成为目前计算机视觉和自然语言处理领域的主流研究方向。在图 像问答算法的研究过程中,引入端到端建模的思想,同时对图像使 用适当的网络结构进行端到端建模,让计算机根据输入的问题和图 像自动回答是一个值得深入探索的研究问题。
多年来,在计算机视觉领域中已经充分认识到上下文信息或对 象之间的关联关系有助于模型的增强。但是大多数使用该信息的方 法都在深度学习的普及之前。目前的深度学习时代,利用对象之间 的关系信息,特别是图像问答领域并没有取得重大进展,大多数方 法仍然专注于分别对实体施加关注。由于图像内物体具有二维空间 位置和尺度/纵横比等变化,而图像问答模型需要依赖实体间的相互 关系对问题进行推理。因此物体的位置信息也即一般意义上的几何 特征在图像问答模型中起着复杂且重要的作用。
在实际应用方面,图像问答算法具有广泛的应用场景。随着可 穿戴智能硬件(如Google glasses和微软的HoloLens)以及增强现 实技术的快速发展,在不久的将来,基于视觉感知的图像内容自动 问答系统可能会成为人机交互的一种重要方式。在这项技术可以帮 助我们,尤其是那些有视觉障碍的残疾人更好地感知和理解世界
综上所述,基于端到端建模的图像问答算法是一个值得深入研 究的方向,本课题拟从该任务中几个关键的难点问题切入,解决目 前方法存在的问题,并最终形成一套完整的图像问答系统。
由于自然场景下的图像内容复杂,主体多样;基于自然语言的 描述自由度高,这使得图像内容描述面临巨大的挑战。具体而言, 主要存在如下两方面的难点:
(1)如何对图像-问题的跨媒体数据进行有效地特征提取:特征 提取问题是跨媒体表达研究方向中一个经典且基础的问题,常用的 方法有方向梯度直方图(Histogram of Oriented Gradient,HOG)、局 部二值模式(Local Binary Pattern,LBP)、Haar特征等图像处理特 征提取方法。此外,基于深度学习理论的ResNet、GoogLeNet、 Faster-RCNN模型所提取的特征在很多领域,如图像细粒度分类、 自然语言处理、推荐系统中均发挥了优异的效果。因此,在跨媒体 数据特征提取时选择合适的策略,在保证计算的高效性地同时,提 高特征的表达能力是一个值得深入研究的方向。
(2)如何依赖图像中实体间的相互关系对问题进行推理:图像 问答算法的输入为图像和问题,图像可能拥有多个目标实体。算法 既要抽取图像中各目标实体的特征,对图像各个目标进行正确地理 解,同时还要利用目标特征的几何特征和视觉特征推理出个目标之 间的联系。因此,如何让算法自动学习到图像各目标间的联系,形 成更为准确地跨媒体表达特征,是图像问答算法中的难点问题,同 时也是影响算法结果性能的至关重要的环节。
技术实现要素:
本发明提供了一种基于多目标关联深度推理的图像问答方法。 一种针对图像问答(Visual Question Answering)任务的深度神经网 络架构,本发明主要包含两点:1、采用表达能力更强并带有几何信 息的图像特征。2、利用图像中的目标特征对图像中各目标之间的关 系进行推理。
本发明解决其技术问题所采用的的技术方案包括如下步骤:
步骤(1)、数据预处理,对图像和文本数据提取特征
首先是对图像预处理:
使用Faster-RCNN深度神经网络结构检测图像中包含的目标实 体。对图像提取视觉特征V以及图像中包含各目标尺寸、坐标信息 的几何特征G。
对文本数据进行预处理:
统计给定的问题文本的句子长度根据统计信息设置问题文本的 最大长度。构建问题文本词汇字典,将问题的词语替换为描述词汇 字典中的索引值,然后经过LSTM,从而将问题文本转化为向量q。
步骤(2)、基于候选框几何特征增强的注意力模块
其结构如图2所示,对于输入的三个特征候选框位置的几何特 征G、视觉特征V和注意力权重向量m。
首先对注意力权重向量m进行顺序编码,将其根据权值大小顺 序转化为向量后,映射到高维度与同样映射到高维度的视觉特征V 相加,其输出经过层归一化(LayerNormalization)处理得到VA。
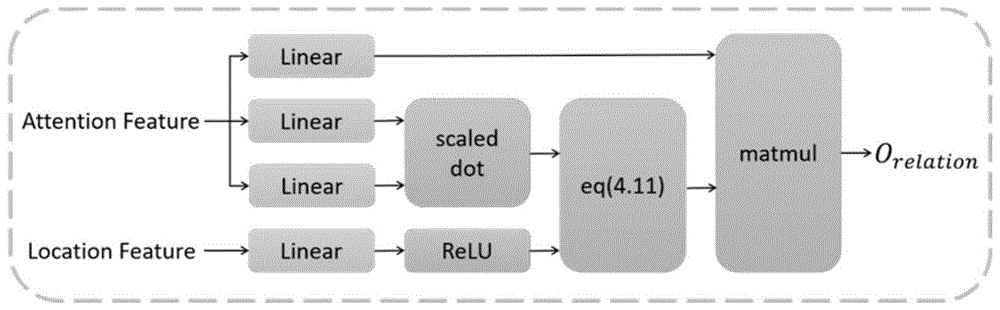
然后将几何特征G通过线性层映射后经过激活函数ReLU得到 GR。将VA和GR输入候选框关系组件(RelationModule)进行推理得 到Orelation,如图1所示。将Orelation经过线性层和sigmoid函数与原始 的注意力权重向量m相乘得到新的注意力向量
步骤(3)、构建深度神经网络
其结构如图3所示,首先将问题文本中根据词汇字典转换为索 引值向量。然后将该向量经过高维映射传入长短期记忆网络(Long Short Term Memory,LSTM),将其输出的向量q和使用Faster R-CNN 获得的视觉特征V通过哈达玛积(Hadamard product)的方式融合, 并通过注意力模块得到各实体特征的注意力权重m。将注意力权重 m、视觉特征V以及几何特征G输入基于候选框几何特征增强的适 应性注意力模块(Adaptive Attention Module,AAM),利用视觉特 征和候选框位置的几何特征进行推理,对注意力权重进行重排序, 得到新的注意力向量将注意力向量与视觉特征V乘积融合后 做加权平均得到新的视觉特征将视觉特征与问题文本向量q通 过哈达玛积融合经过softmax函数产生概率,并将此概率输出作为 网络的输出预测值。
步骤(4)、模型训练
根据产生的预测值同该图像的实际描述的差异,并利用反向传 播算法对步骤(3)中神经网络的模型参数进行训练,直至整个网络模 型收敛。
步骤(1)具体实现如下:
1-1.对图像i进行特征提取,使用现有的深度神经网络 Faster-RCNN提取特征,提取的特征包括图像中包含的k个目标的视 觉特征V和几何特征G,其中V={v1,v2,...,vk},G={g1,g2,...,gk},k∈[10,100]且单个目标的视觉向量为单个目标的几何特征为 gi={x,y,w,h},其中其中x,y,w,h为几何特征的位置参数, 分别表示图像中实体所在候选框的横坐标、纵坐标以及宽度和高度;
1-2.对于给定的问题文本,首先统计数据集中问题文本中不同 的词,并将其记录在字典中。根据单词字典将单词列表中的词语转 化成索引值,从而将问题文本转化成固定长度的索引向量,其具体公 式如下:
其中是单词wk在字典中的索引值,l表示问题文本的长度。
步骤(2)所述的基于候选框几何特征增强的适应性注意力模块 深度推理网络,具体如下:
2-1.首先将输入的注意力权重向量m进行处理。将m中的各目 标注意力权重m{m1,m2,...,mk}的值排序的序号pos进行编码, 其具体公式如下:
其中i∈[0,1,...,d/2],pos∈[1,2,...,k],得到基于注意力权 重m的矩阵
2-2.将矩阵PE和视觉特征V分别经过不同的线性层后相加, 其输出经过层归一化处理得到VA,其具体公式如下:
VA=Layer Norm(WPEPET+WVVT) (公式3)
其中
2-3.对几何特征G进行关联计算,将其经过线性层得到GR, 其具体公式如下:
GR=WGΩ(G)T (公式4)
其中,m,n∈[1,2,...,k]GE使用公式(2)编码,
2-4.将VA和GR输入关联模块进行推理得到Orelation,具体公式如 下:
Orelation=softmax(log(GR)+VR)·(WOVA+bO) (公式7)
其中
2-5.将Orelation经过全连接层后,再经过sigmoid函数与原始的 注意力权重m相乘得到新的注意力向量具体公式如下:
其中
步骤(3)所述的构建深度神经网络,具体如下:
3-1.将问题文本向量q与视觉特征V经过全连接层的线性变换 映射至公共空间然后使用哈达玛积融合,Ffusion表示公共空间上的融 合特征。Wr和Wq分别表示将视觉特征V和当前状态信息q进行线性 变换的对应全连接层参数,符号表示两矩阵采用哈达玛乘积。Wm表 示将融合特征降维并产生注意力权重分布的全连接层参数,初始注意力权重向量m,j表示 当前计算第j个区域注意力权重。具体公式如下:
m=softmax(WmFfusion+bm) (公式10)
3-2.根据步骤(2)将m、V以及G输入基于候选框几何特征增 强的适应性注意力模块,利用V以及G的特征进行推理,对m进行 重排序,得到新的注意力特征
3-3.通过与V的特征乘积后做加权平均得到的视觉特征向量 具体公式如下:
步骤(4)所述的训练模型,具体如下:
VQA-v2.0数据集中的问答对由多人回答,因此同一个问题可能 有不同的正确回答。先前的图像问答模型将最高票数视为唯一正确 回答,并对其进行独热编码(one-hot encoding)。因为正确回答 具有多元性,故对同一问题的全部回答进行投票,按照票数确定该 正确答案在全部正确答案中的权重。并且使用Kullback-Leibler divergence损失函数,若N表示回答词汇表的长度。Predict表示 预测值分布,GT表示真实值。则定义如所示:
本发明有益效果如下:
本发明涉及一种对图像-描述的数据进行统一建模,在图像中各目标 特征上进行推理,对各目标的注意力机制重排序从而更精确地对图像 进行描述的方法。本发明首次引入图像中隐含的几何特征并对其结构 化,使其与图像内实体特征进行协同推理,在于现有的视觉问答技术 结合后能有效提高视觉问答模型的准确率。
本发明参数量较小,轻量且高效,有利于更高效的分布式训练, 有利于部署于内存受限的特定硬件。
附图说明
图1:候选框关系组件(Relation Module)
图2:基于候选框几何特征增强的适应性注意力模块
图3:基于候选框几何特征增强的适应性注意力模块的图像问 答神经网络架构
具体实施方式
下面对本发明的详细参数做进一步具体说明。
如图1所示,本发明提供一种针对图像问答(Visual Question Answering)的深度神经网络框架。
步骤(1)所述的数据预处理及对图像和文本进行特征抽取,具 体如下:
1-1.对于图像数据的特征提取,我们使用MS-COCO数据集作 为训练和测试数据,并且利用现有的Faster-RCNN模型抽取其视觉 特征。具体的,我们把图像数据输入到Faster-RCNN网络中,利用 Faster-RCNN模型检测图像中10~100个目标并框出,对每个目标的 图像提取2048维视觉特征V,并记录每个图标的框的坐标及大小 {x,y,w,h}作为该目标的几何特征G,其中V={v1,v2,...,vk}, G={g1,g2,...,gk},k∈[10,100]。
1-2.对于问题文本,首先统计数据集中问题文本中不同的词, 并将文本总出现的所有词将词频高于5的9847个单词记录在字典中。
1-3.对每个问题句子只取前16个单词,若问题句子不满16个 单词则补充空字符。利用每个单词在1-2中生成单词字典中的索引 值替代该单词,完成字符串从数值之间的转化,从而每个问题转化 成16个单词索引向量。
步骤(2)基于候选框几何特征增强的适应性注意力模块 (Adaptive Attention Module,AAM)模型对图像的目标特征V和几 何特征G之间进行学习并关联从而对输入的原始注意力信息m进行 重排序,具体如下:
2-1.首先将输入的注意力权重向量m进行处理,将m中的各目标 注意信息{m1,m2,...,mk}的值排序的序号pos进行编码,得到基于注 意力信息m的矩阵
2-2.将PE映射到128维与同样映射到128维的V相加,其输出 经过层归一化处理得到大小为100x128的矩阵VA。
2-3.对特征G进行关联计算并通过公式(2)编码得到100x100x64维的矩阵,将该矩阵的最后一维映射为单一值后经过激 活函数ReLU得到100x100维的矩阵GR。
2-4.将VA和GR输入关联(Relation)模块进行推理,首先将VA中 各目标的特征映射至128维,之后将目标特征相互点乘得到100x100 的矩阵VR。根据VR与GR联合计算得到100x100的矩阵并与VA中的每 个目标取加权平均得到100x128的矩阵Orelation。
2-5.将Orelation经过全连接层后,进过sigmoid与原始的m相乘得 到新的100维的
步骤(3)所述的构建深度神经网络,具体如下:
3-1.对于问题文本特征,这里的文本输入是步骤(1)产生的16 维索引值向量,我们使用word embedding技术将每个单词索引转换 成对应的词向量,这里我们使用的词向量大小为1024。因此每个问 题文本变成大小为16x1024的矩阵。并将输入的视觉特征补零为 100x2048的矩阵,再经过线性层映射为100x1024的矩阵,之后我 们将每个时刻的单词向量作为LSTM的输入,其中LSTM是一种循 环神经网络结构,我们将其输出设为1024维的向量q。
3-2.我们对LSTM的输出向量q输入注意力模块得到初步的100 维注意力特征m,至此,图像关注点信息提取(Attention)操作完 成。
3-3.根据步骤(2)将m、V以及G输入基于候选框几何特征增 强的适应性注意力模块(Adaptive Attention Module,AAM)模型, 利用V以及G的特征进行推理,对m进行重排序,得到新的100维 的注意力特征至此,对图像中目标间的关联推理并对关注点 (attention)进行重排序的操作完成。
3-4.通过100维向量与100x1024维的特征V做加权平均得 到1024维的带注意力的视觉特征
3-5.我们将上述生成的重排序后的带注意力信息的视觉特征与LSTM的输出向量q进行融合,并依次经过FC层和softmax操作, 其中FC是神经网络全连接操作,最终输出单词的9487维预测向量, 其中该输出中每一个元素表示预测该元素索引对应的答案是给定问 题的答案的概率值。
步骤(4)所述的训练模型,具体如下:
对于步骤(3)产生的预测9487维向量,我们将其与该问题的 正确答案做比较,通过我们定义的损失函数计算得出预测值与实际 正确值之间的差异从而形成损失值,并根据该损失值利用BP算法 调整整个网络的参数值,从而使得该网络产生的预测同实际值之间 的差距逐渐缩小,直到网络收敛。
- 还没有人留言评论。精彩留言会获得点赞!