一种基于服务数据的数据仓库创建方法及数据仓库与流程
本发明涉及大数据技术领域,具体涉及一种基于服务数据的数据仓库创建方法及数据仓库。
背景技术:
随着计算机存储能力的提升和复杂算法的发展,近年来网络数据量成指数级增长,科学数据处理、商业智能数据分析等具有海量数据需求的应用变得越来越普遍,传统的oracle(mysql)+sql技术架构已不能满足大数据处理要求,对于数据仓库的搭建,业界比较常用的是分布式+etl的方式,但是基于服务的分布式+etl数据仓库技术却一直没有比较好的解决方案。
技术实现要素:
针对上述现有技术中的缺陷,本发明提供一种基于服务数据的数据仓库创建方法及数据仓库,架构上分为数据采集、数据存储、数据分析、数据服务等,可对多数据源进行整合、对数据进行建模加工,并设置有统一的数据标准,为基于服务数据的数据仓库创建提供良好的解决方案。
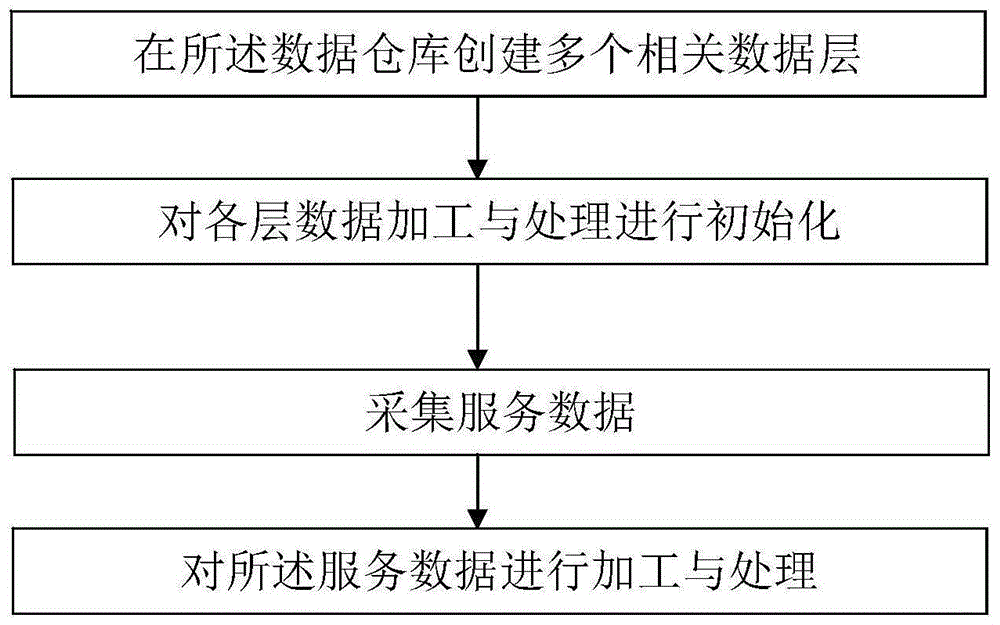
本发明具体为:一种基于服务数据的数据仓库创建方法,其特征在于,包括:
在所述数据仓库创建多个相关数据层;
基于预设算法,对各层数据加工与处理进行初始化;
采集服务数据;
基于上述初始化,对所述服务数据进行加工与处理。
其中,所述在所述数据仓库创建多个相关数据层,包括:
创建数据存储层、数据仓库层。
其中,所述在所述数据仓库创建多个相关数据层还包括:
以所述数据仓库层为基础创建主题层、汇总层、应用层。
其中,所述采集服务数据具体包括:
采集业务系统中的服务数据,将采集的服务数据存储在所述数据存储层中。
其中,所述基于上述初始化,对所述服务数据进行加工与处理具体包括:
按照数据仓库层数据加工与处理的要求,对所述数据存储层中存储的数据进行加工与处理。
其中,所述方法还包括:
将处理后的数据存放在所述数据仓库层中。
其中,所述数据采集具体包括:
采用flume+kafka+storm组合架构进行数据采集,实现对海量数据的实时处理。
其中,所述数据加工与处理包括:
对内部数据和外部数据、结构化数据和非结构化数据进行采集;
对脏数据和无效数据进行清洗;
对非结构化数据进行结构化加工;
在结构化数据的基础上进行建模和数据挖掘。
其中,按照数据仓库层数据加工与处理的要求,对所述数据存储层中存储的数据进行加工与处理,具体包括:
根据所述数据处理流程,结合所述主题层、汇总层、应用层的数据加工与处理要求,对所述数据存储层中存储的数据进行有选择的提取,将单一的数据信息转换成体系信息,将点信息数据转换成面信息数据;
所述将加工与处理后的数据存放在所述数据仓库层中,具体包括:
将加工与处理后的数据相应地存放在所述主题层、汇总层、应用层中。
其中,根据所述数据处理流程,按照数据仓库层数据加工与处理的要求,对所述数据存储层中存储的数据进行加工与处理后,所述方法还包括:
所述主题层将本层存放的数据按照各宏观业务分析领域分别进行归类、分析,并将各分析结果进行关联。
第二方面,本发明还提出了一种基于服务数据的数据仓库,适用于上述的基于服务数据的数据仓库创建方法,其特征在于,包括:
数据存储层、数据仓库层、主题层、汇总层、应用层;
所述数据存储层用于保存业务系统的服务数据;
所述数据仓库层用于承载所述主题层、汇总层、应用层的数据;
所述主题层用于将所述服务数据进行综合、归类和分析;
所述汇总层用于支撑固定分析需求,提高数据查询性能;
所述应用层用于为前端应用的展现提供数据。
其中,所述数据存储层保存的服务数据,是采用flume+kafka+storm组合架构在所述业务系统中进行数据采集得到的。
其中,所述主题层包括至少一个主题表,各主题表分别对应不同的宏观业务分析领域及相关分析算法,用于对所述服务数据进行分领域分析。
其中,所述汇总层具体用于:
聚合原子粒度事实表及维度表,用于支撑固定分析需求;生成高粒度表,用于提高数据查询性能。
其中,所述数据仓库建立在hadoop分布式系统上,所述数据仓库层还用于:
承载数据算法模型,建立数据分析模型立方体;
所述数据算法模型包括数据挖掘模型、分布式计算引擎、高性能机器学习算法库、即席查询功能。
所述数据仓库从架构层次上分为数据采集、数据存储、数据分析、数据服务;数据采集负责从业务系统(各业务子系统)中汇集信息数据,系统支持kafka、storm、flume及传统的etl采集工具;数据存储提供hdfs、hbase等相结合的存储模式,支持海量数据的分布式存储;数据分析支持传统的olap分析,支持基于spark常规机器学习算法以及基于python的机器学习、数据分析和数据可视化等。
本发明的有益效果体现在:
本发明得到的数据仓库从架构上分为数据采集、数据存储、数据分析、数据服务等,可对多数据源进行整合、对数据进行建模加工,并设置有统一的数据标准,为基于服务数据的数据仓库创建提供良好的解决方案。在数据采集是采用flume+kafka+storm的组合架构,采用flume和etl工具作为kafka的producer,采用storm作为kafka的consumer,strom可实现对海量数据的实时处理。数据仓库建立在hadoop分布式系统之上,可提供多种丰富的算法模型,充分满足业务需求。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍。在所有附图中,类似的元件或部分一般由类似的附图标记标识。附图中,各元件或部分并不一定按照实际的比例绘制。
图1为本发明某一实施例一种基于服务数据的数据仓库创建方法流程图;
图2为本发明另一实施例一种基于服务数据的数据仓库创建方法流程图;
图3为本发明实施例一种基于服务数据的数据仓库结构图;
图4为本发明实施例一种基于服务数据的数据仓库架构图。
具体实施方式
下面将结合附图对本发明技术方案的实施例进行详细的描述。以下实施例仅用于更加清楚地说明本发明的技术方案,因此只作为示例,而不能以此来限制本发明的保护范围。
需要注意的是,除非另有说明,本申请使用的技术术语或者科学术语应当为本发明所属领域技术人员所理解的通常意义。
如图1所示,为本发明某一实施例一种基于服务数据的数据仓库创建方法,其包括:
在所述数据仓库创建多个相关数据层;
基于预设算法,对各层数据加工与处理进行初始化;
采集服务数据;
基于上述初始化,对所述服务数据进行加工与处理。
其中,所述在所述数据仓库创建多个相关数据层,包括:
创建数据存储层、数据仓库层。
其中,所述在所述数据仓库创建多个相关数据层还包括:
以所述数据仓库层为基础创建主题层、汇总层、应用层。
其中,所述采集服务数据具体包括:
采集业务系统中的服务数据,将采集的服务数据存储在所述数据存储层中。
其中,所述基于上述初始化,对所述服务数据进行加工与处理具体包括:
按照数据仓库层数据加工与处理的要求,对所述数据存储层中存储的数据进行加工与处理。
其中,所述方法还包括:
将处理后的数据存放在所述数据仓库层中。
如图2所示,为本发明一种基于服务数据的数据仓库创建方法实施例,包括:
s11:创建数据存储层、数据仓库层,在所述数据仓库层之上创建主题层、汇总层、应用层;
s12:建立数据处理流程,通过预设算法实现各层数据加工与处理的标准化、规范化;所述预设算法,是在汇集数据资源所需的标准规范信息后制定的,旨在于建立数据标准型数据仓库;
s13:对业务系统中的服务数据进行数据采集,将采集的数据存储在所述数据存储层中;
s14:根据所述数据处理流程,按照数据仓库层数据加工与处理的要求,对所述数据存储层中存储的数据进行加工与处理;
s15:将加工与处理后的数据存放在所述数据仓库层中。
优选地,所述数据采集具体包括:
采用flume+kafka+storm组合架构进行数据采集,实现对海量数据的实时处理。
所述数据采集分为实时数据采集和定时数据采集,实时数据采集主要通过streamsets配置数据源组件kafka等方式实现,定时数据采集主要通过sqoop等采集工具配合etl流程实现;采用flume和etl工具作为kafka的producer,采用storm作为kafka的consumer,strom可实现对海量数据的实时处理;采集的数据存储于数据存储层,在数据仓库层各层次间数据转换提取加载。
优选地,所述数据加工与处理包括:
对内部数据和外部数据、结构化数据和非结构化数据进行采集;
对脏数据和无效数据进行清洗;
对非结构化数据进行结构化加工;
在结构化数据的基础上进行建模和数据挖掘。
优选地,根据所述数据处理流程,按照数据仓库层数据加工与处理的要求,对所述数据存储层中存储的数据进行加工与处理,具体包括:
根据所述数据处理流程,结合所述主题层、汇总层、应用层的数据加工与处理要求,对所述数据存储层中存储的数据进行有选择的提取,将单一的数据信息转换成体系信息,将点信息数据转换成面信息数据;
所述将加工与处理后的数据存放在所述数据仓库层中,具体包括:
将加工与处理后的数据相应地存放在所述主题层、汇总层、应用层中。
优选地,根据所述数据处理流程,按照数据仓库层数据加工与处理的要求,对所述数据存储层中存储的数据进行加工与处理后,还包括:
所述主题层将本层存放的数据按照各宏观业务分析领域分别进行归类、分析,并将各分析结果进行关联。
如图3所示,为本发明一种基于服务数据的数据仓库实施例,适用于上述基于服务数据的数据仓库创建方法,包括:
数据存储层21、数据仓库层22、主题层23、汇总层24、应用层25;
所述数据存储层21用于保存业务系统的服务数据;
所述数据仓库层22用于承载所述主题层23、汇总层24、应用层25的数据;
所述主题层23用于将所述服务数据进行综合、归类和分析;
所述汇总层24用于支撑固定分析需求,提高数据查询性能;
所述应用层25用于为前端应用的展现提供数据。
优选地,所述数据存储层21保存的服务数据,是采用flume+kafka+storm组合架构在所述业务系统中进行数据采集得到的。
所述数据采集分为实时数据采集和定时数据采集,实时数据采集主要通过streamsets配置数据源组件kafka等方式实现,定时数据采集主要通过sqoop等采集工具配合etl流程实现;采用flume和etl工具作为kafka的producer,采用storm作为kafka的consumer,strom可实现对海量数据的实时处理;采集的数据存储于数据存储层,在数据仓库层各层次间数据转换提取加载。
优选地,所述主题层23包括至少一个主题表,各主题表分别对应不同的宏观业务分析领域及相关分析算法,用于对所述服务数据进行分领域分析。
所述主题表可以包括用户主题表、服务商主题表、订单主题表、收入主题表、流量主题表等。
优选地,所述汇总层24具体用于:
聚合原子粒度事实表及维度表,用于支撑固定分析需求;生成高粒度表,用于提高数据查询性能。
优选地,所述数据仓库建立在hadoop分布式系统上,所述数据仓库层22还用于:
承载数据算法模型,建立数据分析模型立方体;
所述数据算法模型包括数据挖掘模型、分布式计算引擎、高性能机器学习算法库、即席查询功能。
所述数据仓库从架构层次上分为数据采集、数据存储、数据分析、数据服务;数据采集负责从业务系统(各业务子系统)中汇集信息数据,系统支持kafka、storm、flume及传统的etl采集工具;数据存储提供hdfs、hbase等相结合的存储模式,支持海量数据的分布式存储;数据分析支持传统的olap分析,支持基于spark常规机器学习算法以及基于python的机器学习、数据分析和数据可视化等。相应地,本发明给出一种基于服务数据的数据仓库架构图,如图4所示。
本发明得到的数据仓库从架构上分为数据采集、数据存储、数据分析、数据服务等,可对多数据源进行整合、对数据进行建模加工,并设置有统一的数据标准,为基于服务数据的数据仓库创建提供良好的解决方案。在数据采集是采用flume+kafka+storm的组合架构,采用flume和etl工具作为kafka的producer,采用storm作为kafka的consumer,strom可实现对海量数据的实时处理。数据仓库建立在hadoop分布式系统之上,可提供多种丰富的算法模型,充分满足业务需求。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 还没有人留言评论。精彩留言会获得点赞!