一种新闻话题跟踪方法与流程
本发明属于文本信息处理技术领域,具体涉及一种新闻话题跟踪方法。
背景技术:
在话题跟踪任务中,规定只给少量的报道用作训练话题模型,数据的不足导致构造的话题模型很难完整表达话题。在现有的话题跟踪技术中,有很多基于静态话题模型的算法。静态话题模型,顾名思义即静态的模型,它的设计思路一般是给出极少与新闻报道话题相关的训练报道,在进行关键词提取之后将报道转换为模型,然后对测试语料进行相同的预处理,得到相应的模型,最后根据待测模型与训练模型的相似度,来判断该模型是否与训练模型相关,即判断话题是否为旧话题。
根据描述可知,静态话题模型是固化的,只跟最开始的训练语料相关,但随着时间的推移,事情可能会呈现新的进展,从而出现话题漂移的情况,即话题出现了新的突发事件,或者有了更新的进展,但是传统的静态话题模型并不能及时地更改模型,从而导致对话题后续的跟踪造成较大的偏差,原因在于,静态模型只于初始语料相关,例如“4.25尼泊尔地震”这一话题的最初报道均集中对事件“4月25日尼泊尔发生7.7级左右地震震源深度11公里”进行了播报,这就导致了静态模型所抽取的关键词基本都围绕着种子事件。而随着后续的报道中,例如“中国62人救援队驰援尼泊尔,曾参与汶川地震搜救”,从地震这一关注点,转移到了震后搜救这一事件上,而静态模型只针对了地震这一事件,并不再进行任何更新和修正,进而会错误的将该报道视为新话题,或者归类为其他已知话题,因此随着报道的逐渐增加,静态模型在辨别相关报道方面的能力是逐步下降的。虽然增加更多的特征能够更好的提升效果。但是,增加特征的同时,会造成冗余信息和噪声的增加,使得在判定不相关报道时,增加误判的概率。所以,静态模型的构建的关键在于构建后,话题模型是否能够在话题后期仍能够有很好的话题分辨能力。
现有技术中的knn算法是基于实例的分类算法,它不需要复杂的计算,也不需要对语料的先验知识来训练模型,只需要通过获得离测试点最近的k个近邻样本点通过投票来决定测试点的归属,knn算法依赖极少数的样本点来判断测试点的归属,若数据存在样本点分布不均衡的情况,比例大的某类样本点的存在会导致误检率的增加。而且,随着新闻数据的增多,话题漂移产生的影响也是knn无法有效解决的问题。
在现有的话题跟踪技术中,基于静态话题模型的话题跟踪方法,未融入自适应的更新机制,导致系统不能实时更新,不能很好地解决话题漂移的问题。
技术实现要素:
针对上述现有技术中存在的问题,本发明的目的在于提供一种可避免出现上述技术缺陷的新闻话题跟踪方法。
为了实现上述发明目的,本发明提供的技术方案如下:
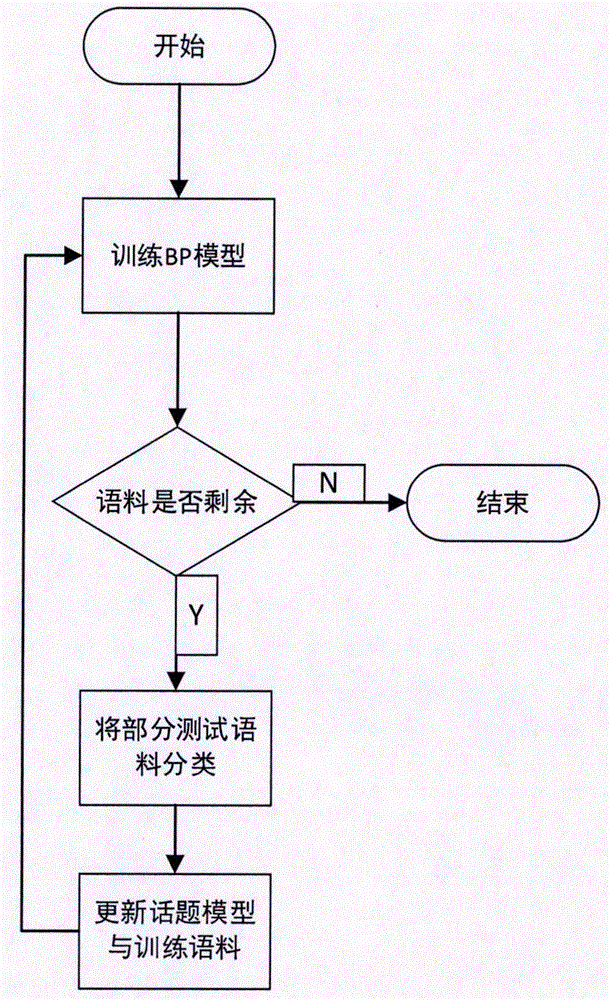
一种新闻话题跟踪方法,将动态话题模型与bp神经网络相结合,先将时间-事件空间模型根据实际需要改变相应权值,再通过bp神经网络训练完成样本与结果的映射关系,并且通过将测试语料分为多份,动态地训练话题模型,不断更新模型中的关键词和它的权重,再重新训练神经网络,接着进行新的分类,完成事件跟踪。
进一步地,bp神经网络由三层结构构成,分别为输入层、隐层、输出层;输入层采用时间-事件关联模型中的关键词集。
进一步地,确定隐层的节点个数的公式为:
其中,input为输入层节点个数,output为输出层节点个数,α为范围在[1,10]之间的常数。
进一步地,bp神经网络中涉及的变量定义如下:
输入向量:x={x1,x2,...,xn};
隐层输入向量:hi={hi1,hi2,...,hip};
隐层输出向量:ho={ho1,ho2,...hop};
输出层输入向量:yi={yi1,yi2,...,yim};
输出层输出向量:yo={yo1,yo2,...,yom};
期望输出向量:do={d1,d2,...,dm};
输入层与中间层的连接权值:wih;
隐层与输出层的连接权值:who;
隐层各神经元的阈值:bh;
输出层各神经元的阈值:bo;
样本数据个数:k:1,2,...,l;
误差函数:
进一步地,bp神经网络算法流程如下:
(1)网络初始化,给各个连接权值均赋一个区间在值(-1,1)的随机数,给定最大学习次数m;
(2)选择某个输入样本及对应的期望输出作为一条训练数据;
(3)计算隐含层各神经元的输入和输出;
(4)根据最终计算出的输出值与样本数据的期望值进行对比,计算出相应的误差;
(5)不断地根据计算相应的偏导数,来修正各个层之间相互连接的权值;
(6)当学习次数大于设定的最大次数,则结束算法;否则,继续选取新的学习样本及对应的期望输出,返回第(3)步,继续对模型进行学习训练。
进一步地,在动态话题模型中引入自适应的更新策略,即基于动态话题模型的自适应的更新策略,包括:
将测试语料分为多个部分,每部分内容、数量不同,数量呈递增状态,格式为:
k={k1,k2,k3,...,kn};
k为整个测试语料集合,k1表示第一部分测试语料,总共分为n个部分;每份语料通过分类模型分类后,统计该分类结果,将分类后的每类进行关键词统计,重新统计出该类的关键词集;将该类中的文本关键词集与该类的话题关键词集进行比较,根据文本关键词集与该类的新闻关键词集的相同程度来对文本进行排序;若文本的相同程度不同,则相同程度越高,排序位置越前;若文本的相同程度相同,则按时间顺序进行排序,距离初始时间越远的排序位置越靠前;将排序前80%的文本作为新的神经网络训练语料,对神经网络进行训练,构建新的话题模型,完成分类模型的自适应更新;将更新后的分类模型继续对后续语料进行分类,直到最后分类完成。
进一步地,关键词集的统计方法为:将每类的文本的关键词集合并,并统计出现次数,将出现次数最高的前十位作为该类新的话题关键词集。
本发明提供的新闻话题跟踪方法,在动态话题模型中引入自适应的更新策略,将动态话题模型与bp神经网络相结合,先将时间-事件空间模型根据实际需要改变相应权值,再通过bp神经网络训练完成样本与结果的映射关系,并且通过将测试语料分为多份,动态的训练话题模型,不断更新模型中的关键词和它的权重,再重新训练神经网络,接着进行新的分类,完成事件跟踪,通过不断地更新话题模型解决了事件跟踪过程中出现的话题偏移造成的正确率下降的问题,能够达到较好的话题跟踪效果,可以很好地满足实际应用的需要。
附图说明
图1为本发明的流程图;
图2为bp神经网络结构图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施例对本发明做进一步说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
一种新闻话题跟踪方法,将动态话题模型与bp神经网络相结合,先将时间-事件空间模型根据实际需要改变相应权值,再通过bp神经网络训练完成样本与结果的映射关系,并且通过将测试语料分为多份,动态地训练话题模型,不断更新模型中的关键词和它的权重,再重新训练神经网络,接着进行新的分类,完成事件跟踪。参考图1所示。
bp神经网络在训练过程中,会根据输出层实际的输出值与期望输出值的误差反向反馈给上一层,计算出该层的误差后再反馈到上一层,这样一层层的反馈,调整相应的权重,经过对训练语料的不断学习最终得到训练完成的模型。如图2所示,bp神经网络由三层结构构成,分别为输入层、隐层、输出层。
输入层采用时间-事件关联模型中的关键词集。隐层的节点个数不像输入层和输出层是固定的,而节点的个数对神经网络的性能是有影响的,通过一个经验公式来确定隐层的节点个数,公式如下:
其中,input为输入层节点个数,output为输出层节点个数,α为范围在[1,10]之间的常数。
bp神经网络中涉及的变量定义如下:
输入向量:x={x1,x2,...,xn};
隐层输入向量:hi={hi1,hi2,...,hip};
隐层输出向量:ho={ho1,ho2,...hop};
输出层输入向量:yi=-{yi1,yi2,...,yim};
输出层输出向量:yo={yo1,yo2,...,yom};
期望输出向量:do={d1,d2,...,dm};
输入层与中间层的连接权值:wih;
隐层与输出层的连接权值:who;
隐层各神经元的阈值:bh;
输出层各神经元的阈值:bo;
样本数据个数:k:1,2,...,l;
误差函数:
bp神经网络算法流程如下:
(1)网络初始化,给各个连接权值均赋一个区间在值(-1,1)的随机数,给定最大学习次数m。
(2)选择某个输入样本及对应的期望输出作为一条训练数据。
(3)计算隐含层各神经元的输入和输出。
(4)根据最终计算出的输出值与样本数据的期望值进行对比,计算出相应的误差。
(5)不断地根据计算相应的偏导数,来修正各个层之间相互连接的权值。
(6)当学习次数大于设定的最大次数,则结束算法。否则,继续选取新的学习样本及对应的期望输出,返回第(3)步,继续对模型进行学习训练。
bp神经网络有以下优点:
(1)非线性映射能力。它能够通过自主的学习并不断修正自身结果的过程来完成输入与输出层的非线性映射,只要提供足够多的样本,那么它一定能完成相应映射。
(2)泛化能力。即使对于网络从未见过的样本,根据训练得到的模型仍然能够完成映射,这种能力称为泛化能力。
(3)容错能力。对孤立点不敏感,若有个别样本点错误或者有较大误差,模型也不会因为个别的样本点发生较大的改变,也就是说对网络最后构建的映射关系的影响不大。
相对于静态话题模型,动态话题模型随着话题的报道逐步增加,会对特征和权值进行更新,使得话题模型能够跟随话题的关注点的漂移而改变,因为基于话题跟踪训练所提供的训练语料只有几篇,并不能很好的完成对话题进行后续的跟踪,所以需要对话题模型进行动态的调整,根据上述问题,本发明提出了在动态话题模型中引入自适应的更新策略,即基于动态话题模型的自适应的更新策略,话题模型可通过自学习,不断完善自身模型,有助于提高相关报道的判定,有效区别不相关报道,提高系统性能。
基于动态话题模型的自适应的更新策略包括以下步骤:
bp神经网络模型构建成功后,将基于动态话题模型进行自适应更新,将测试语料分为多个部分,每部分内容、数量不同,数量呈递增状态,格式如下:
k={k1,k2,k3,...,kn};
k为整个测试语料集合,k1表示第一部分测试语料,总共分为n个部分进行操作。每份语料通过分类模型分类后,统计该分类结果,将分类后的每类进行关键词统计,重新统计出该类的关键词集。统计方法为将每类的文本的关键词集合并,并统计出现次数,将出现次数最高的前十位作为该类新的话题关键词集。将该类中的文本关键词集与该类的话题关键词集进行比较,根据文本关键词集与该类的新闻关键词集的相同程度来对文本进行排序,比如,某文本关键词集中的关键词与该类新的话题关键词集中的关键词有5个相同关键词,则该文本与该类的相同程度为5。若文本的相同程度不同,则相同程度越高,排序位置越前。若文本的相同程度相同,则按时间顺序进行排序,距离初始时间越远的排序位置越靠前。将排序前80%的文本作为新的神经网络训练语料,对神经网络进行训练,构建新的话题模型,完成分类模型的自适应更新。将更新后的分类模型继续对后续语料进行分类,直到最后分类完成。
基于动态话题模型的bp神经网络分类,bp神经网络泛化能力较好,而且根据分类结果能够动态的调整bp神经网络,实时更新学习模型,解决了因为话题漂移而存在的事件分类错误问题。
为了验证本发明方法的优点,将本发明方法与knn算法进行对比实验:话题追踪任务规定,构建话题模型时,仅仅提供极少量新闻报道,因此训练语料选取5个新闻报道热门话题并各给出6条正例报道(该话题相关报道)和4条反例报道(该话题不相关报道)供建立模型,五个话题分别是:“反法西斯70周年”、“尼泊尔地震”、“东方之星沉船”、“伊朗核问题”、“伊斯兰国”。并选取2000条多个话题组成的新闻报道作为测试语料。正反例比例为4∶1。
本实施例选取knn作为对比方法,其中knn算法是基于实例的分类算法,它不需要复杂的计算,也不需要对语料的先验知识来训练模型,只需要通过获得离测试点最近的k个近邻样本点通过投票来决定测试点的归属,本次knn的对比实验采取k个近邻样本点中个数最多的类簇来确定测试点的类簇归属。
经过实验结果对比,在语料数量相同时,本发明方法的误检率和漏检率大大低于knn算法的误检率和漏检率,从而验证了本方法的优势。
本发明提供的新闻话题跟踪方法,在动态话题模型中引入自适应的更新策略,将动态话题模型与bp神经网络相结合,先将时间-事件空间模型根据实际需要改变相应权值,再通过bp神经网络训练完成样本与结果的映射关系,并且通过将测试语料分为多份,动态的训练话题模型,不断更新模型中的关键词和它的权重,再重新训练神经网络,接着进行新的分类,完成事件跟踪,通过不断地更新话题模型解决了事件跟踪过程中出现的话题偏移造成的正确率下降的问题,能够达到较好的话题跟踪效果,可以很好地满足实际应用的需要。
以上所述实施例仅表达了本发明的实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!