一种基于SLIC超像素和自动阈值分割的农作物图像病虫害区域提取方法与流程
本发明涉及基于图像处理的农作物病虫害检测领域,具体涉及一种基于slic超像素和自动阈值分割的农作物图像病虫害区域提取方法。
背景技术:
中国是一个农业大国,在国民经济发展中占据着十分重要地位的农业生产中,农作物病虫害的预防和治理十分重要。在病虫害的防治工作中,首要并且最主要面对的问题是如何在农作物的生长过程中,对危害农作物的病虫进行正确的识别并在正确的识别的基础上,对病虫所造成的危害做出准确的分析,因此,需要对农作物病虫害区域进行提取,以便进行后续的识别工作。目前,检测农作物的病虫害一般是通过人工检查、测量、统计计算等步骤确定。农业技术人员或专家面临着大量的重复工作。同时传统的人工方法存在病害面积不方便计算,人工统计害虫数量时容易引起害虫逃逸等难以解决的问题,这些问题给农业科研工作者带来了工作上的极大不便。本发明利用图像处理技术,能够有效提取出农作物病虫害区域,使检测工作更具效率性,准确性和实用性。
技术实现要素:
本发明的目的在于克服由于人工检测统计方法测量效率低、误差大、重复工作等缺点,以及在检测过程中由于人为因素带来的局限,进而提供了一种基于slic超像素和自动阈值分割的农作物病虫害区域提取方法。
为了解决背景技术所存在的问题,本发明采用以下解决方案:
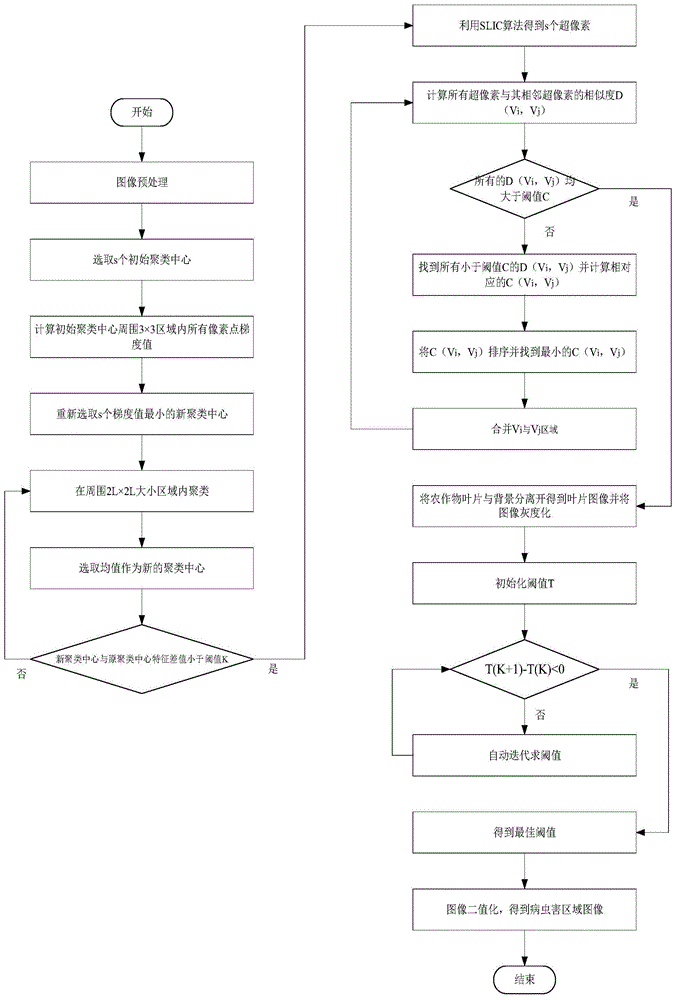
一种基于slic超像素和自动阈值分割的农作物病虫害区域提取算法,它包括以下步骤:
步骤一:图像预处理:将收集到的农作物病虫害图像数据进行中值滤波处理,防止噪声干扰。
步骤二:确定初始聚类中心s0[s1,s2,...ss]:根据原始图像等距离l的选取s个聚类中心,记原始图像像素点个数为n,根据
步骤三:进行聚类:在初始聚类中心s0[s1,s2,...ss]周围2l×2l区域内进行聚类,聚类准则取决于像素点与聚类中心的亮度差与距离,当像素点与聚类中心亮度差和距离小于阈值δ时,将该像素点归为该聚类中心一类,否则归入不同类。得到s个区域记为v1[v1,v2,...vs],计算这s个区域内各像素点与聚类中心距离和亮度差的均值,选取与聚类中心的距离和亮度差最接近均值的像素点s个作为新的聚类中心,记为s1[s1,s2,...ss]。
步骤四:判断最佳聚类中心:当满足条件:sn+1[s1,s2,...ss]中的聚类中心与sn[s1,s2,...ss]中的聚类中心距离和亮度差小于阈值τ时,说明sn+1[s1,s2,...ss]为最佳聚类中心,vn+1[v1,v2,...vs]为最佳超像素分割区域;否则回到步骤三重新进行聚类,直到满足条件停止聚类。
步骤五:计算相似度d(vi,vj):得到图像的最佳超像素分割后,需要计算相邻区域的相似程度来判断合并的可能性,计算方法为直方图相交法,需要计算图片的rgb分量与hsv分量。
步骤六:判断最佳合并区域:根据vi与vj区域的相似度d(vi,vj)来计算合并vi与vj区域的代价c(vi,vj),找到最小的c(vi,vj)合并vi与vj区域,当满足条件:所有的d(vi,vj)均大于阈值c时,停止合并,进入步骤七。否则重新计算新合并的区域与其他区域的相似度,重复步骤六。
步骤七:得到农作物叶片图像:根据前六步提取出农作物叶片部位的图像,并将图像灰度化,将背景像素值赋值为0(黑色)。
步骤八:自动迭代求阈值:要求最多迭代m次,则建立阈值数组ti(i=1,…,m),确定初始阈值t1。用t1分割图像,遍历图像的像素点,如果该点像素值大于t1,则将该点划分为病虫害区;如果该点像素值小于t1,则将该点划分为健康区。分别求出病虫害区和健康区的平均像素值u1和u2,新的阈值
步骤九:得到最终农作物叶片病虫害区域:遍历叶片图像中的每一个像素点,如果该点的像素值大于t,则将该点划分为病虫害区,将其像素值赋值为255(白色);如果该点的像素值小于t,则将该点划分为叶片健康区,将其像素值赋值为128(灰色)。可以得到最终结果:背景(黑色),农作物叶片(灰色),农作物病虫害区域(白色)。
进一步地,在基于slic的超像素分割过程中,
等距离l选取s个聚类中心后,需要求s个中心周围3×3区域内所有像素点的梯度值,记图像上任一点的坐标为(i,j),则可以利用中值差分来求取像素点梯度值,如式(1)所示:
(i,j)代表像素点的坐标,dx与dy分别代表该像素点在x水平方向与y垂直方向上的梯度值;
上式中i(i,j)表示该点的像素亮度值,通过计算选取其中梯度值最小的像素点作为新的初始聚类中心,以防止把边界点或者奇异点设置为聚类中心;
然后在聚类中心周围2l×2l区域内进行聚类,聚类准则基于像素点与聚类中心的距离和亮度差,如下公式(2)所示:
x代表相应点的坐标值,i代表相应点的亮度值;sm代表聚类中心点,表示的是第m个聚类中心;
上式中表示当像素点与聚类中心的距离与亮度差小于阈值δx、δi时,可将该像素点归类为该聚类中心一类,得到s个划分好的区域,根据公式(3):
δx代表距离上的阈值,当点(i,j)与聚类中心点的距离小于δx时,停止这一次迭代;同理,δi代表亮度上的阈值;这两个值与原图像的尺寸和亮度特征相关,是根据实际情况来选择的,两者之间没有明确的关系;
计算出均值得到新的聚类中心s1[s1,s2,...ss]来代替原始聚类中心,最后进行判断条件是否满足公式(4):
x(sn+1[s1,s2,...ss])-x(sn[s1,s2,...ss])<τx(4)
i(sn+1[s1,s2,...ss])-i(sn[s1,s2,...ss])<τi
当满足上述条件时,即可以得到最佳的聚类中心sn+1[s1,s2,...ss]和最佳的s个超像素区域vn+1[v1,v2,...vs],否则,重新进行聚类直到满足上述条件。
进一步地,可在进行聚类的迭代过程中,设置一个迭代次数最大值,当迭代次数大于这个最大值时,停止聚类。
进一步地,在基于直方图相交的区域合并过程中,在利用上述步骤得到s个超像素区域后,合并叶片区域的超像素;使用直方图相交法计算区域vi与vj的相似度,公式如下所示:
上式中,h(k)代表相应区域的亮度直方图,d(vi,vj)表示区域vi与vj的相似度,相似度还可以分解为对应rgb与hsv通道的分量,如公式(6)所示:
上式中系数ω1+ω2+ω3+ω4+ω5+ω6=1,分别代表hsv和rgb通道的分量,当满足条件:所有的d(vi,vj)均大于阈值c时,说明此时所有的超像素都无法合并,可以进行下一步计算;否则,计算合并区域vi与vj的代价,公式如下:
上式中s(vi,vj)为区域vi与vj的面积和,α与β为固定值系数;在所有的代价中,选取代价最小的两区域进行合并;合并后,新区域与其他相邻区域重复计算相似度,直到满足所有相似度大于阈值c时,退出循环。
进一步地,在基于自动阈值分割的农作物病虫害区域提取过程中,迭代的次数根据农作物病虫害区域提取精度来确定的(如果迭代的次数增加,这样二值化后的图像就越精细,农作物病虫害区域提取就越准确)。
基于slic的超像素分割,用于提取农作物叶片的边缘信息,能够较为完整的保留边缘纹理与特征;基于直方图相交的超像素合并,用于合并农作物叶片的整体图像,将其与背景分隔开;基于自动阈值分割的农作物病虫害区域提取,用于提取叶片上的病虫害区域,并进行下一步的检测与识别。
本发明对比现有技术,有如下有益效果:
传统的农作物病虫害检测方法由于人工因素,导致检测精度较低。本发明克服了人工检测统计方法测量效率低,误差大,重复工作等缺点,以及在检测过程中由于人为因素带来的局限,提供了一种基于slic超像素和自动阈值分割的农作物病虫害区域提取算法,大大减少了不必要的人力劳动,保证了准确性,实用性和效率性。
本发明采用了如下三种算法:基于slic的超像素分割算法,基于直方图相交的超像素合并算法和基于自动阈值分割的病虫害区域提取算法。slic算法是simplelineariterativecluster的简称,该算法用来生成超像素(superpixel)。三部分算法的主要功能如下:基于slic的超像素分割算法用于提取农作物叶片的边缘信息,能够较为完整的保留边缘纹理与特征;基于直方图相交的超像素合并算法用于合并农作物叶片的整体图像,将其与背景分隔开;基于自动阈值分割的病虫害区域提取算法用于提取叶片上的病虫害区域,以便进行下一步的检测与识别等。
本发明通过对上传图像信息进行图像预处理,然后根据slic超像素分割算法将图像分割为若干超像素区域,从而提取病虫害叶片的边缘信息;以分割为超像素的图片为基础,通过直方图相交法合并超像素区域,从而将农作物叶片从背景干扰中提取出来。最后通过对叶片进行像素点遍历,利用叶片图像中正常区域与病虫害区域图像纹理相差较大的原理,设置自动阈值迭代将病虫害区域与健康区域分割开,具有较高的提取精度和效率,并避免重复工作。
附图说明
下面结合附图和实例对本发明进一步说明。
图1是本发明的基于slic超像素和自动阈值分割的农作物病虫害区域提取算法流程图。
图2是基于slic的超像素分割算法流程图。
图3是基于直方图相交的区域合并算法流程图。
图4是基于自动阈值分割的农作物病虫害区域提取算法流程图。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步描述:
图1是本发明的基于slic超像素和自动阈值分割的农作物病虫害区域提取算法流程图。它包括以下步骤:
步骤一:图像预处理:将收集到的农作物病虫害图像数据进行中值滤波处理,防止噪声干扰。
步骤二:确定初始聚类中心s0[s1,s2,...ss]:根据原始图像等距离l的选取s个聚类中心,记原始图像像素点个数为n,根据
步骤三:进行聚类:在初始聚类中心s0[s1,s2,...ss]周围2l×2l区域内进行聚类,聚类准则取决于像素点与聚类中心的亮度差与距离,当像素点与聚类中心亮度差和距离小于阈值δ时,将该像素点归为该聚类中心一类,否则归入不同类。得到s个区域记为v1[v1,v2,...vs],计算这s个区域内各像素点与聚类中心距离和亮度差的均值,选取与聚类中心的距离和亮度差最接近均值的像素点s个作为新的聚类中心,记为s1[s1,s2,...ss]。
步骤四:判断最佳聚类中心:当满足条件:sn+1[s1,s2,...ss]中的聚类中心与sn[s1,s2,...ss]中的聚类中心距离和亮度差小于阈值τ时,说明sn+1[s1,s2,...ss]为最佳聚类中心,vn+1[v1,v2,...vs]为最佳超像素分割区域;否则回到步骤三重新进行聚类,直到满足条件停止聚类。
步骤五:计算相似度d(vi,vj):得到图像的最佳超像素分割后,需要计算相邻区域的相似程度来判断合并的可能性,计算方法为直方图相交法,需要计算图片的rgb分量与hsv分量。
步骤六:判断最佳合并区域:根据vi与vj区域的相似度d(vi,vj)来计算合并vi与vj区域的代价c(vi,vj),找到最小的c(vi,vj)合并vi与vj区域,当满足条件:所有的d(vi,vj)均大于阈值c时,停止合并,进入步骤七。否则重新计算新合并的区域与其他区域的相似度,重复步骤六。
步骤七:得到农作物叶片图像:根据前六步提取出农作物叶片部位的图像,并将图像灰度化,将背景像素值赋值为0(黑色)。
步骤八:自动迭代求阈值:要求最多迭代m次,则建立阈值数组ti(i=1,…,m),确定初始阈值t1。用t1分割图像,遍历图像的像素点,如果该点像素值大于t1,则将该点划分为病虫害区;如果该点像素值小于t1,则将该点划分为健康区。分别求出病虫害区和健康区的平均像素值u1和u2,新的阈值
步骤九:得到最终农作物叶片病虫害区域:遍历叶片图像中的每一个像素点,如果该点的像素值大于t,则将该点划分为病虫害区,将其像素值赋值为255(白色);如果该点的像素值小于t,则将该点划分为叶片健康区,将其像素值赋值为128(灰色)。可以得到最终结果:背景(黑色),农作物叶片(灰色),农作物病虫害区域(白色)。
其中,步骤一到步骤四属于基于slic的超像素分割算法流程,步骤五到步骤七属于基于直方图相交的区域合并算法流程,步骤八与九是基于自动阈值分割的农作物病虫害区域提取算法流程。
如图2,是基于slic的超像素分割算法流程图:首先对图像进行预处理工作:通过中值滤波去除噪声的干扰;然后确定初始聚类中心:等距离l选取s个聚类中心后,需要求s个中心周围3×3区域内所有像素点的梯度值,记图像上任一点的坐标为(i,j),则可以利用中值差分来求取像素点梯度值,如下公式一所示:
上式中i(i,j)表示这个点的像素亮度值,通过计算选取其中梯度值最小的像素点作为新的初始聚类中心,这一步的目的是为了防止把边界点或者奇异点设置为聚类中心。然后在聚类中心周围2l×2l区域内进行聚类,聚类准则基于像素点与聚类中心的距离和亮度差,如下公式二所示:
上式中表示当像素点与聚类中心的距离与亮度差小于阈值时,可以将该像素点归类为该聚类中心一类,得到s个划分好的区域,根据公式三:
计算出均值得到新的聚类中心s1[s1,s2,...ss]来代替原始聚类中心,最后进行判断,当条件满足如下公式四:
当满足上述条件时,即可以得到最佳的聚类中心sn+1[s1,s2,...ss]和最佳的s个超像素区域vn+1[v1,v2,...vs],否则,重新进行聚类直到满足上述条件。
在进行聚类的迭代过程中,可以设置一个迭代次数最大值,当迭代次数大于这个最大值时,停止聚类。
如图3,是基于直方图相交的区域合并算法流程图:在利用上述方法得到s个超像素区域后,最主要的问题在于如何合并叶片区域的超像素。这里使用直方图相交法计算区域vi与vj的相似度,公式如下所示:
上式中,h(k)代表相应区域的亮度直方图,d(vi,vj)表示区域vi与vj的相似度,相似度还可以分解为对应rgb与hsv通道的分量,如公式六所示:
上式中系数ω1+ω2+ω3+ω4+ω5+ω6=1,分别代表hsv和rgb通道的分量,当满足条件:所有的d(vi,vj)均大于阈值c时,说明此时所有的超像素都无法合并,可以进行下一步计算。否则,计算合并区域vi与vj的代价,公式如下:
上式中s(vi,vj)为区域vi与vj的面积和,α与β为固定值系数。在所有的代价中,选取代价最小的两区域进行合并。合并后,新区域与其他相邻区域重复计算相似度,直到满足所有相似度大于阈值c时,退出循环。
如图4,是基于自动阈值分割的农作物病虫害区域提取算法流程图:利用上述方法已经将农作物叶片图像与背景分割开,并且将图像灰度化,将背景赋值为0(黑色),然后进行自动迭代求得阈值:要求迭代m次,则建立阈值数组ti(i=1,…,m),确定初始阈值t1。用t1分割图像,遍历叶片图像的像素点,如果该点像素值大于t1,则将该点划分为病虫害区;如果该点像素值小于t1,则将该点划分为健康区。分别求出病虫害区和健康区的平均像素值u1和u2,新的阈值
进一步的,在自动分割阈值的过程中,如果迭代的次数m增加,这样二值化后的图像就越精细,农作物病虫害区域提取就越准确;理论上在一定范围内,迭代次数m越大,提取的精度越高。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!