一种基于FPGA平台的深度学习模型加速方法与流程
本发明涉及一种基于fpga平台的深度学习模型加速方法。
背景技术:
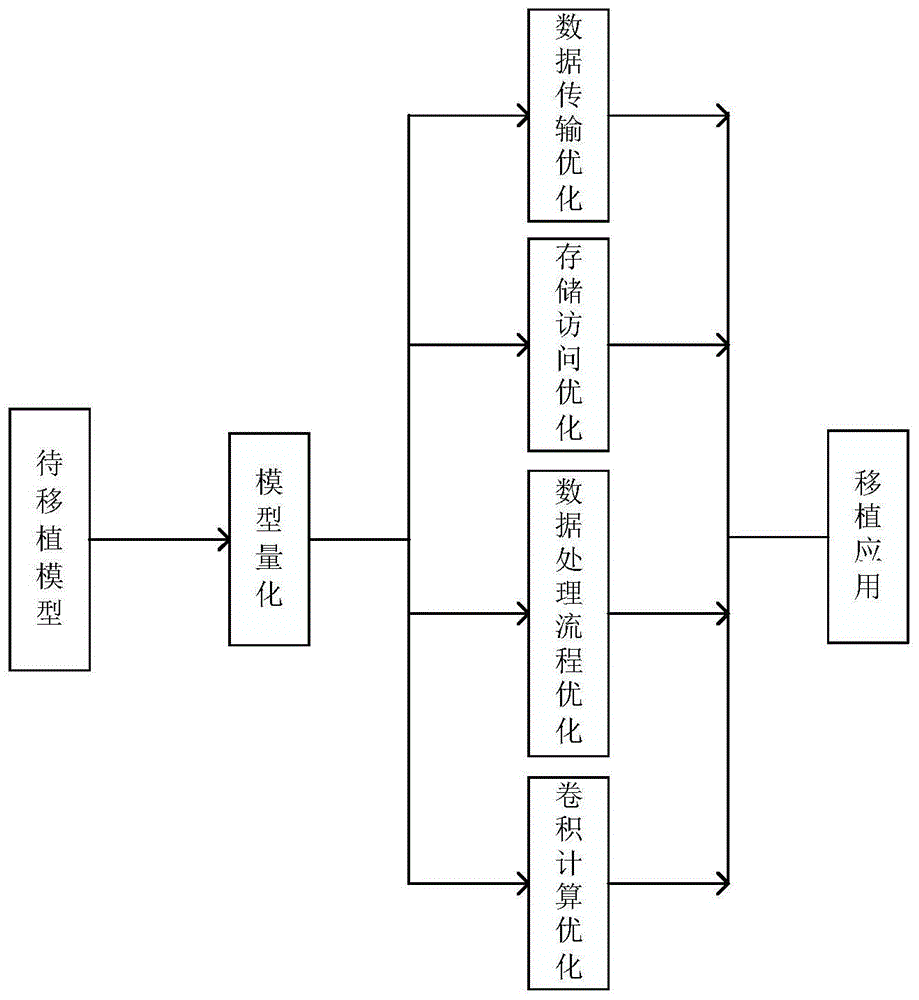
:近年来,深度学习算法持续火热,在图像处理、自然语言处理等传统领域深度学习都取得了巨大的成功,一大批优秀可靠的算法不断涌现。虽然目前大量应用卷积神经网络的算法在图像识别大赛上大放异彩,但是其庞大的参数量需要强大的算力来支撑,而在实际应用场景下计算平台通常不具备足够的计算资源。因此针对这一问题,学界和工程应用领域都提出了不同的解决方案。其中,对模型进行压缩和使用硬件平台进行加速是主流研究方向。当下的硬件计算平台主要有有cpu,gpu,fpga以及asic芯片,由于fpga相对cpu和gpu有更好的功耗比,相比asic研发周期短且更新迭代更灵活,实验opencl能够很快实现深度学习算法迭代。此外,使用rtl语言编写的代码,能够用于芯片前端设计,以及其具备的大量的dsp计算资源和用于深度学习算法的并行计算能力。fpga受到了众多研究人员和工程师的青睐。随着基于fpga的深度学习算法加速研究的不断深入,基于fpga平台的深度学习算法加速遇到了一些挑战,其中一个主要问题是:计算吞吐量不能很好的匹配内存带宽。由于深度学习算法通常是在gpu/cpu端训练而成,所以为了使得基于fpga的加速器能够获得较高的性能,需要在设计前对算法模型进行适当的优化,使得算法本身能够适用于fpga硬件本身。但是基于fpga的算法移植也存在一定的缺陷和挑战性。研究人员发现即使基于相同的fpga器件在移植相同算法模型时,由于采用不同的优化方案,性能相差多达90%。因此,寻求一种性能稳定、加速效果优秀的移植和优化方法是所有研究人员共同追求的目标。技术实现要素:针对上述存在的问题或不足,为了解决fpga平台计算资源或内存带宽没有有效利用造成的移植后算法加速效果不佳的问题,本发明通过对原模型参数进行量化,并从数据传输、数据存储访问、数据处理流程和卷积计算四个方面针对目标硬件进行优化,将其移植到fpga平台上实现硬件加速。大幅提高了原模型的推理速度,实现了系统吞吐量的成本增加,并且精确度不会有太大的损失。本发明的技术方案是:一种基于fpga平台的深度学习模型加速方法,包括以下步骤:步骤1:采用流式架构设计深度学习模型加速的硬件架构,将fpga硬件划分为不同的硬件块,每个硬件块对应执行一个卷积层,将所有硬件块连接起来形成流水处理。步骤2:对要移植的目标模型参数选择合适的量化位数进行量化。由于fpga片上存储、计算资源的限制,需要对模型进行适当的优化,降低庞大的参数量对系统带宽和计算能力的要求。步骤3:通过hls高级综合工具进行配置,实现深度学习模型的加速,包括:步骤31、对数据的传输进行配置。通过将量化后的模型参数尽可能存储于片上内存,并且在数据传输量不变的情况下,利用片上闲置的计算资源,尽可能地提高对数据的复用。并且在缓存部分使用双缓存,通过“乒乓”操作来提高片上内存的使用效率。这部分的优化可以提高内存数据的访问速度,进而达到模型加速的效果。步骤32:对数据的存储访问进行配置。一是对于必须写入全局内存的数据采用“聚合访问模式”来进行访问。二是在hls指令同时访问多个片上内存系统时,控制编译系统聚合的内存系统小于5个。从而使得fpga片上本地内存性能最优。步骤33:对数据处理流程进行配置。在使用综合工具时指定#pragmapipe指令来进行流水线复制,形成多流水处理。通常情况下,可以在多个工作组中共同执行同一个内核程序。步骤34:对卷积计算进行配置。主要操作有三步分:一是对原有循环进行循环平铺,使其更适合流式架构。二是对完全独立的循环层进行循环展开,充分利用片上的计算资源。三是将循环流水切割成几个小块,将切割后的小块并行执行。步骤4:进行移植和应用。将综合后的二进制模型文件部署到fpga平台上进行推断应用。本发明的有益效果为:为克服当前深度学习模型性能优异但难以在资源受限场景下大规模部署的技术难题提供了一种可行的技术方案。本发明采用fpga平台实现深度学习模型,不仅在计算资源上可以匹敌高性能gpu,而且由于可编程硬件的高度并发性可以大大提高系统吞吐量,实际数据处理速度和功耗表现都远优于gpu和cpu平台的表现。附图说明图1为深度学习网络的fpga移植和优化流程图;图2为本发明实施例深度学习网络加速系统软硬件协同架构框图;图3为本发明实施例中采用穷举法得到的roofline模型图;图4为vgg-16原模型的部分推理测试结果图;图5为本发明实施例中vgg-16模型移植优化后的部分推理测试结果图。具体实施方式下面结合附图和实施例对本发明作进一步详细的说明。实施例本例中的fpga平台是指集成了查找表(ltu)、触发器(ff)、数字处理单元(dsp)、存储单元ram及锁相环pll,并采用axi总线进行片上片下的数据传输的系统。本实施例对vgg-16模型进行移植加速优化。附图1为本实施例的深度学习算法的fpga移植和优化方法流程图,依照附图1的处理流程对vgg-16模型进行移植和优化。步骤如下:a、按照如图2所示硬件架构完成硬件设计,按照目标深度学习模型卷积层的结构完成fpga硬件资源的划分。b、对原vgg-16模型进行定点量化,本实施例将原vgg-16模型的32bit浮点型参数量化为8bit定点型参数。c、在使用hls综合工具进行综合时对数据传输过程进行优化。d、在使用hls综合工具进行综合时对存储访问过程进行优化。e、依据roofline模型和穷举法,寻找出本实施例所采用平台2.4gb/s带宽对应的的最佳展开因子,如图2所示,最佳展开因子在c点。f、在使用hls综合工具进行综合时对数据处理过程进行优化。g、在使用hls综合工具进行综合时对卷积计算过程进行优化。h、将量化后的vgg-16模型移植至目标平台上运行,对测试图片进行推理验证。在imagenet数据集上进行测试,测试结果显示,fpga片上资源得到了有效地利用,具体利用情况如表1。并且本发明实施例在top-5精确度上达到了90.53%,甚至略高于原模型。表1fpga片上资源利用情况resoursedspbramlutffused22401024186251205704available25201824274080548160utilization88.9%56.1%68%37.5%本发明实施例也对网络上随机选取的210张图片进行了测试,测试结果显示精确度达到了68%,也高于原模型的65%,部分测试结果展示如附图4附图5。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1