面向多源信息的混合文本话题发现方法与流程
本发明涉及话题发现领域,特别涉及一种面向多源信息的混合文本话题发现方法。
背景技术:
随着信息技术的广泛应用和网络空间的蓬勃发展,网络空间安全问题已成为社会热点。其中,利用话题发现技术掌握民意的走向,对于网络空间安全的治理起着至关重要的作用。有时舆情监管者需要进行热门话题检测的信息源可能来自多种类别,比如一个文本集中既有新闻网站的信息,也有网络社区和社交媒体的信息。由于文本集混杂着不同信息源的文本,所以文本的长度之间有很大的差异性。对这类文本进行多源文本集合的话题检测时,由于新闻网站类信息源的信息和其余两类信息源的信息特点差异较大,就造成了文本向量特征不均匀的现象。面向多源信息的混合文本由于其信息源的多样性,导致文本特征不均匀。近年来的研究中,对于特征分布均匀的文本进行话题聚类的研究较多,而文本向量特征不均匀的问题一直是聚类算法的一个难题。若使用现有的针对特征均匀文本的话题聚类方法,来对特征分布不均匀的文本进行话题聚类,则聚类结果容易被篇幅较长的某个文本所主导话题,短文本的特征将被长文本的特征所稀释,最终话题聚类的结果具有很大的不稳定性。所以使用单独的某个聚类方法来进行文本向量特征不均匀的文本信息话题检测,准确度会很低。
话题检测及追踪(Topic Detection and Tracking,TDT)的概念最早由美国国防高级研究计划局(Defense Advanced Research Projects Agency,DARPA)提出,目标是能在没有人工干预的情况下自动判断新闻数据流的主题。自此之后,该领域进行了多次大规模评测,为信息识别、采集和组织等相关技术提供了新的技术支持。目前,国内外关于文本的话题检测研究已经取得了一定的进展,这些话题检测方法主要分为两类,一类是针对新闻网站信息源信息文本的话题检测研究,另一类是针对网络社区和社交媒体信息源中的用户原创内容(User Generated Content,UGC)的话题检测研究。
针对新闻网站信息源信息的话题检测,在国际上,宾夕法尼亚州立大学的三人于2010年提出一种用于寻找更好的初始种子的改进K-Means算法的聚类算法,用于进行新闻信息的话题检测。基于此算法的新闻信息聚类结果较传统的K-Means算法而言,具有更高的准确度和稳定性。在国内,李琮,袁方,刘宇等人于2016年提出了一种基于LDA模型的中文新闻话题检测方法,该方法能快速有效的实现新闻聚类。
针对网络社区和社交媒体信息源信息的话题检测,在国际上,南加利福尼亚大学的Vivek Kumar Rangarajan Sridhar于2015年提出了一种基于高斯混合模型(Gaussian Mixture Model,GMM)的针对短文本的无监督主题模型,并且通过实验,证明了该模型在进行短文本聚类时要优于LDA模型。在国内,黄健翀、邓玫玲等人于2017年提出了一种基于LSTM自动编码机的短文本聚类方法,该方法更着重于匹配整体的文档结构,得到的聚类结果句子间的结构相似度较高。
上述研究工作对热门话题检测都有着巨大的贡献,但是还存在着很多不足。主要体现在,上述研究工作都是针对文本特征均匀的数据进行热门话题检测,但是对于多信息源文本的热门话题检测,存在着很大的局限性。主要表现在以下几个方面:需要预先设定聚类结果簇的数目,并且聚类结果的好坏与预先设定的值有很大的关系;多信息源的文本特征不均匀,聚类效果不理想;处理海量数据时的效率较低。
技术实现要素:
本发明要解决的技术问题是提供一种面向多源信息的混合文本话题发现方法,该方法基于狄利克雷多项式混合模型(Dirichlet Multinomial Mixture model,DMM)的多源文本聚类方法。通过考虑不同数据源文本数据的特征差异,基于TextRank算法进行多源文本数据的特征融合,并利用DMM模型处理特征融合后文本的稀疏和高维度的问题。实验结果表明,该方法显著提高了多源文本聚类的效果,有效地解决了多源文本的特征不均匀问题与特征融合后文本特征的高维、稀疏问题。对网络空间安全的治理提供了决策支持,对社会的稳定发展做出了贡献。
为了解决上述技术问题,本发明提供一种面向多源信息的混合文本话题发现方法,具体包括以下步骤:
步骤一、对原始数据进行特征融合,得到特征均匀的结果集D;
步骤二、对步骤一中得到特征均匀的结果集D,基于狄利克雷多项式混合模型的聚类方法进行聚类。
所述步骤一中,对原始数据进行特征融合,具体包括以下子步骤:
步骤1.1定义长文本和短文本;
步骤1.2对每一个长文本,基于TextRank算法对长文本进行摘要提取;
步骤1.3对短文本,基于哈工大同义词词林来对短文本进行同义词拓展。
所述步骤二中,具体包括以下子步骤:
2.1初始化,对每一个簇z,初始化mz,nz,nz(w)计数为0,其中mz簇z中所有文档的总数目,nz代表在簇z中所有文档内所有词语的个数,nz(w)表示词语w在簇z中出现的总次数,设置α、β、K的值;
2.2对于结果集D中每一篇文档d,随机为所有文档d初始化一个簇,对于加入的簇,每加入一个文档,将mz的计数加1,将nz的计数加Nd,Nd文档d中所有词语的个数,对每一个单词,nz(w)的计数加Nd(w),Nd(w)为文档d中,词语w的个数;
2.3每篇文档d的重新分配,依次对于每一个簇中的每一篇文档d重新分配,且通过坍塌吉布斯采样算法进行重新分配,通过坍塌吉布斯采样算法,得到概率分布;
2.4根据所求得的概率分布,最终每个文本被分配给一个特定的簇,即每个文本属于一个话题,那么第z个簇中w词语出现的概率为:
其中nz(w)表示词语w在簇z中出现的总次数;φz(w)可以理解为词语w对于簇z的重要程度,根据φz(w)的次序可以得到每个簇的代表词。
所述步骤1.2,具体包括以下子步骤:
1.2.a)预处理,将长文本内容按标点符号分割成句子,形成句子集V,对每个句子进行分词、去除停用词操作;
1.2.b)句子间相似度计算,基于句子间的相似度,构建边集E,通过句子集V和边集E构建出图G,G=(V,E);每个句子Si可以表示为Ni个词语的集合,即
给定两个句子Si,Sj采用如下公式计算两个句子间的相似度wij:
公式中,分子的意义是同时出现在两个句子中的词语的个数,|Si|表示句子Si中词语的个数,|Sj|表示句子Sj中词语的个数;
如果两个句子之间的相似度大于某个设定的阈值,就可以认定这两个句子语义关联并将它们在图G中连接起来,wij作为边的权值;
1.2.c)基于该句子对相邻句子的贡献程度对句子重要程度计算;根据TextRank算法的计算公式,句子的权重WS(Vi)可以迭代表示为:
其中,d是阻尼系数,Vi表示句子集中的句子,In(Vi)代表在图G中指向句子Vi的所有句子的集合,Out(Vj)代表在图G中句子Vj指向的所有句子的集合,wij代表由句子Si和Sj所连接的边的权值,wjk代表由句子Sj和Sk所连接的边的权值;根据上述公式,迭代传播计算各个句子节点的权值;
1.2.d)选取候选摘要句:对1.2.c)中的句子权值进行倒序排序,选取权值最高的前N个句子作为候选摘要句。
1.2.e)形成摘要,根据设置的字数或句子数要求,从候选摘要句中选择句子组成摘要;输入的长文本经过上述过程后,输出为该长文本的摘要,即得到文档d,其中文档d属于结果集D。
所述步骤1.3,具体包括以下子步骤:
1.3.a)预处理,得到Nd个词语的集合D,即
1.3.b)名词同义词拓展,对经过预处理后的文档d中的每个名词Wk∈Noun,利用TYCCL进行检索,并把所有词语wl∈synonym(wk)加入到文档d中;
1.3.c)输入结果:最终输出一个经过同义词扩展后的文档d,其中文档d属于结果集D。
所述步骤2.3,具体包括以下子步骤:
2.3.a)将文档d从当前簇中移除,而后将mz的计数减1,将nz的计数减Nd,Nd文档d中所有词语的个数,对每一个单词,nz(w)的计数减Nd(w),Nd(w)为文档d中,词语w的个数;
2.3.b)通过坍塌吉布斯采样算法,计算
p(zd=k|z-d,D,α,β)∝p(zd=k|z-d,α)p(d|zd=k,z-d,-d,β)
z为表示通用的簇,zd代表文档d被分配的簇,k为特定的簇,z-d为除去文档d后的簇的所有文档;
p(zd|z-d,α)可以用中国餐馆过程CRP来表示:
其中mk(d)表示在簇k中除去文档d之外所有文档的总数目,n代表整个文档集中所有文档的总数目;
p(d|zd=k,z-d,-d,β)为:
其中nz,-d(w)表示词语w在簇z中除去文档d的所有文档中出现的总次数,Nd表示在文档d中所有词语的个数,nz,-d代表在簇中除去文档d所有文档内所有词语的个数;
2.3.c)随机为该文档分配一个簇,对该簇,将mz的计数加1,将nz的计数加Nd,Nd文档d中所有词语的个数,对每一个单词,nz(w)的计数加Nd(w),Nd(w)为文档d中,词语w的个数。
所述步骤1.1中,若一篇文档的长度超过整个原始数据的平均长度,则视为长文本;否则,视为短文本处理。
本发明的有益技术效果在于:
1)能够将文本向量特征不均匀的多源文本数据均匀化;
2)通过DMM模型,提升对高噪声、低信息量的短文本数据的话题检测效果;
3)能自动识别出聚类的类别个数,不需要事先给定簇的个数。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
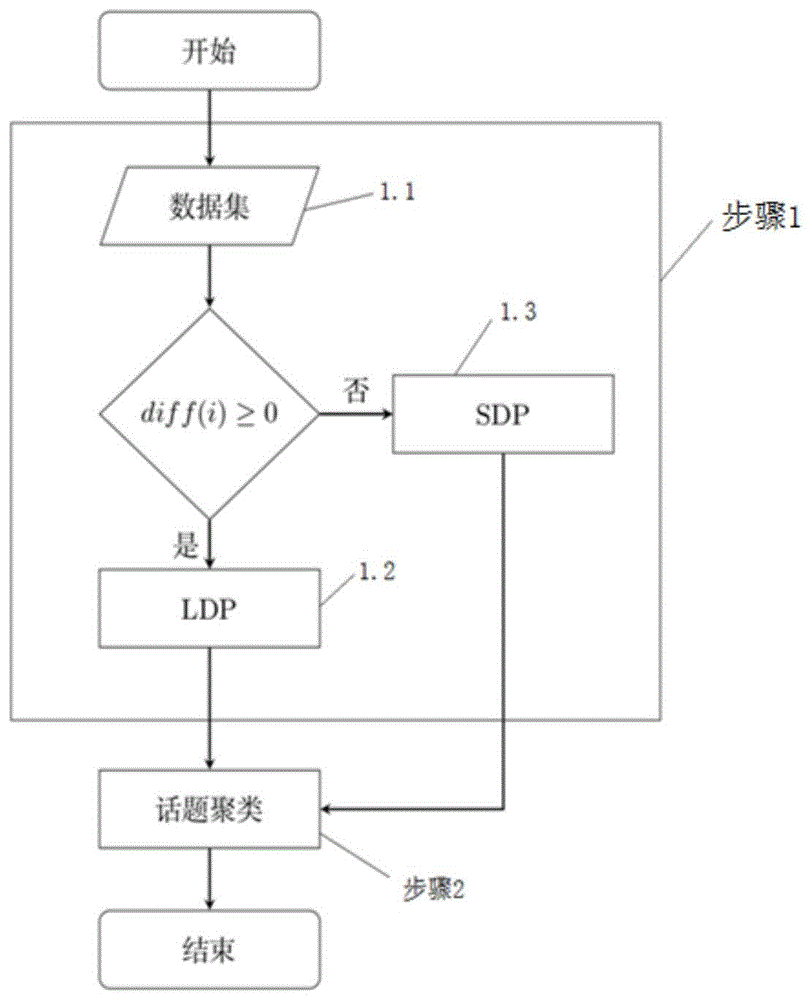
图1是本发明的一种面向多源信息的混合文本话题发现方法流程图;
图2是基于狄利克雷多项式混合模型的聚类方法流程图。
具体实施方式
如图1所示,本发明提供了一种面向多源信息的混合文本话题发现方法,包括以下步骤:
步骤一、从新闻网站、社交媒体、高校论坛获取原始数据,对原始数据进行基于TextRank的多源文本特征融合,以提升文本特征的均匀性,得到特征均匀的结果集D;
由于原始数据的多样性,原始数据既包含新闻网站类数据,也包含社交媒体类数据。这些文本数据的篇幅参差不齐,文本特征表现出不均匀性;针对上述问题,本文采用基于图排序的TextRank算法对新闻网站的长文本进行摘要提取,以减少新闻网站信息的篇幅,同时利用哈工大同义词词林(TYCCL)来对社交媒体的短文本进行同义词拓展,以达到语义增强,扩展篇幅的目的,进而实现多信息源文本数据的特征分布趋于均匀化,最终实现多源文本特征融合;
步骤1.1定义长文本和短文本,优选的,若一篇文档的长度超过整个原始数据的平均长度,则视为长文本;否则,视为短文本处理;
步骤1.2对每一个长文本,基于TextRank算法对长文本进行摘要提取;TextRank算法是基于PageRank算法改进而来,可以计算出一段文字中的每个词语或者句子相对于整篇文字的重要程度;通过选取文本中重要程度较高的句子来形成文摘,该过程简称为LDP(Long Document Process),具体包括以下子步骤:
1.2.a)预处理,将长文本内容按标点符号分割成句子,形成句子集V,对每个句子进行分词、去除停用词等操作;
1.2.b)句子间相似度计算,基于句子间的相似度,构建边集E,通过句子集V和边集E构建出图G,G=(V,E);每个句子Si可以表示为Ni个词语的集合,即
给定两个句子Si,Sj采用如下公式计算两个句子间的相似度wij:
公式中,分子的意义是同时出现在两个句子中的词语的个数,|Si|表示句子Si中词语的个数,|Sj|表示句子Sj中词语的个数;
如果两个句子之间的相似度大于某个设定的阈值,就可以认定这两个句子语义关联并将它们在图G中连接起来,wij作为边的权值;
1.2.c)基于该句子对相邻句子的贡献程度对句子重要程度计算;根据TextRank算法的计算公式,句子的权重WS(Vi)可以迭代表示为:
其中,d是阻尼系数,一般设置为0.85,Vi表示句子集中的句子,In(Vi)代表在图G中指向句子Vi的所有句子的集合,Out(Vj)代表在图G中句子Vj指向的所有句子的集合,wij代表由句子Si和Sj所连接的边的权值,wjk代表由句子Sj和Sk所连接的边的权值;
根据上述公式,迭代传播计算各个句子节点的权值;
1.2.d)选取候选摘要句:对1.2.c)中的句子权值进行倒序排序,选取权值最高的前N个句子作为候选摘要句;
1.2.e)形成摘要,根据设置的字数或句子数要求,从候选摘要句中选择句子组成摘要;输入的长文本经过上述过程后,输出为该长文本的摘要,即得到文档d,其中文档d属于结果集D;
步骤1.3针对短文本,基于哈工大同义词词林来对短文本进行同义词拓展,扩展其篇幅;TYCCL提供了每个中文词语wi的同义词集合synonym(wi),即对于一个词语wi,与任意词语wj∈synonym(wi)的意义相同;本文基于TYCCL提出一种短文本语义扩展方法,该方法简称为SDP(Short Document Process),具体如下:
1.3.a)预处理,将输入的文本集中的每篇文档d进行分词、去除停用词等操作;最终得到Nd个词语的集合D,即
1.3.b)名词同义词拓展:由于是进行热门话题发现,所以文档中的名词起到关键的作用;对经过预处理后的文档d中的每个名词wk∈Noun,利用TYCCL进行检索,并把所有词语wl∈synonym(wk)加入到文档d中;
1.3.c)输入结果:最终输出一个经过同义词扩展后的文档d,其中文档d属于结果集D;
步骤二、如图2所示,对步骤一中得到特征均匀的结果集D,基于狄利克雷多项式混合模型的聚类方法进行聚类;具体包括以下子步骤:
2.1初始化,设置α、β、K的值,将所有文档划分为K个簇,对每一个簇z,初始化mz,nz,nz(w)计数为0,其中mz簇z中所有文档的总数目,nz代表在簇z中所有文档内所有词语的个数,nz(w)表示词语w在簇z中出现的总次数;
2.2对于结果集D中每一篇文档d,随机为所有文档d初始化一个簇,对于加入的簇,每加入一个文档,将mz的计数加1,将nz的计数加Nd,Nd文档d中所有词语的个数,对每一个单词,nz(w)的计数加Nd(w),Nd(w)为文档d中,词语w的个数;
2.3每篇文档d的重新分配,首先,依次对于每一个簇中的每一篇文档d重新分配,具体包括以下子步骤:
2.3.a)将文档d从当前簇中移除,而后将mz的计数减1,将nz的计数减Nd,Nd文档d中所有词语的个数,对每一个单词,nz(w)的计数减Nd(w),Nd(w)为文档d中,词语w的个数;
2.3.b)通过坍塌吉布斯采样算法,计算
p(zd=k|z-d,D,α,β)∝p(zd=k|z-d,α)p(d|zd=k,z-d,-d,β)
z为表示通用的簇,zd代表文档d被分配的簇,k为特定的簇,z-d为除去文档d后的簇的所有文档;
p(zd|z-d,α)可以用中国餐馆过程CRP来表示:
其中mk(d)表示在簇k中除去文档d之外所有文档的总数目,n代表整个文档集中所有文档的总数目;
p(d|zd=k,z-d,-d,β)可以表示为:
其中nz,-d(w)表示词语w在簇z中所有文档中(除去文档d)出现的总次数,Nd表示在文档d中所有词语的个数,nz,-d代表在簇中所有文档(除去文档d)内所有词语的个数;
2.3.c)随机为该文档分配一个簇,对该簇,将mz的计数加1,将nz的计数加Nd,Nd文档d中所有词语的个数,对每一个单词,nz(w)的计数加Nd(w),Nd(w)为文档d中,词语w的个数;
2.4根据所求得的概率分布,最终每个文本被分配给一个特定的簇,即每个文本属于一个话题,那么第z个簇(话题)中w词语出现的概率为:
其中nz(w)表示词语w在簇z中出现的总次数;φz(w)可以理解为词语w对于簇z的重要程度,根据φz(w)的次序可以得到每个簇的代表词。
使用经过网络爬虫获取的包含多信息源语料库进行聚类分析。目前常用的聚类质量评估方法主要有两种:外部评估法和内部评估法。外部评估法指的是用来比较聚类方法对特定数据集的聚类结果与已知分类的相似度,采用聚类熵(Entropy)和聚类纯度(Purity)作为外部评估指标;内部评估法主要通过计算聚类结果簇间距离和簇内相似度来评估一个聚类方法的效果,使用轮廓系数(silhouette coefficient)作为内部评估指标。
为了计算聚类结果的熵(Entropy),需要首先计算pij,pij表示簇i中的文档属于簇j的概率,其中mii代表簇i中的文档属于簇j的个数,mi表示簇i中所有文档的个数。这样,每个簇的熵ei可以表示为
其中,K表示簇的个数。
所以整个聚类结果的熵可以表示为:
其中ni表示簇i中的总文档个数,n表示整个文档集的总文档个数。
2)聚类纯度,表示正确聚类的文档占总文档的比例。可以表示为:
其中,N代表用于聚类的文档集的总文档数目,ωk代表第k个簇中的所有文档,cj代表文档集中原本属于类别j的所有文档。
3)轮廓系数,现在假设已经将具有n个文档的数据集D划分成了k个簇,C1,...,Ck。对于每一个文档d,a(d)表示数据点d和d所在簇中其他文档的平均距离,将a(d)称为文档d的簇内不相似度。
假设文档d∈Ci,1≤i≤k,则a(d)可以表示为:
对于每一个文档d,b(d)表示数据点d和其他所有d不属于的簇之间的最小平均距离,将b(d)成为文档d的簇间不相似度。
依旧假设文档d∈Ci,1≤i≤k,则b(d)可以表示为:
根据文档d的簇内不相似度和簇间不相似度,可以定义文档d的轮廓系数为:
文档d的轮廓系数取值范围是[-1,1]。s(d)接近+1,则说明文档d聚类合理;s(d)接近-1,则说明文档d更应该聚类到其他的簇中;s(d)接近0,说明文档d在两个簇的边界处。
在采用是复旦大学中文语料库与微博数据集共同组成的混合数据集,以满足本文算法的应用场景——多源混合文本。
将混合数据集分成三个子数据集,每个数据集中包含10个类别,表1展示了本文的实验数据集。在使用K-means聚类算法时,设定K-Means的聚类数量K为10,并且使用TF-IDF对文本进行向量化;在使用GSDMM聚类算法时,设置参数a=0.2,b=0.01,K=50;在使用本发明的算法时,设置参数a=0.2,b=0.01,K=50。表2展示了三种聚类算法在对数据及进行聚类后的聚类熵对比。
得出本文提出的算法,在聚类熵上,要略好于K-Means算法和GSDMM算法。这是因为,K-Means算法比较依赖高维度的文本特征,比较适用于长文本聚类。而GSDMM算法比较适用于短文本聚类。对于多源混合文本,本文提出的算法的聚类熵更低。
对数据集进行聚类之后,本发明的聚类算法与K-Means聚类算法的聚类纯度对比;本发明的提出的聚类算法,在聚类纯度上要略高于经典的K-Means算法。
在聚类结果的轮廓系数对比,可以看出,本发明的提出的算法的轮廓系数普遍高于K-Means算法,说明本发明的算法在簇内相似度和簇间距离的综合效果要优于K-Means。
以上描述仅为本申请的较佳实施例以及对所运用技术原理的说明。本领域技术人员应当理解,本申请中所涉及的发明范围,并不限于上述技术特征的特定组合而成的技术方案,同时也应涵盖在不脱离上述发明构思的情况下,由上述技术特征或其等同特征进行任意组合而形成的其它技术方案。例如上述特征与本申请中公开的(但不限于)具有类似功能的技术特征进行互相替换而形成的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!