基于用户偏好与服务变化双向感知的移动服务推荐方法与流程
本发明属于移动服务技术领域,涉及一种移动服务推荐方法,具体涉及一种基于用户偏好与服务变化双向感知的移动服务推荐方法。
背景技术:
近年来,随着移动互联网的飞速发展,移动服务的数量也呈现高速增长。用户寻找自己感兴趣的移动服务开始变得越来越困难,出现了严重的信息过载问题。因此,针对用户的移动服务推荐显得尤为重要。移动服务推荐可以帮助用户过滤无用的信息,从而使用户发现感兴趣的服务。
目前较为普遍的服务推荐方法主要有基于协同过滤与基于内容的推荐,基于协同过滤算法认为具有相似行为兴趣的用户喜欢相同的服务,而基于内容的推荐则将与用户曾经喜欢的服务相类似的其他服务推荐给用户,这些方法存在以下两个缺陷,一是不能准确感知用户真正的喜好,忽略用户自身喜好所带来的需求;二是认为用户的兴趣偏好和服务本身都是静态的,没有考虑两者的变化因素,而实际上,用户的兴趣会随着时间不断地变化,服务本身也在持续地改变。
所以,如何在考虑用户兴趣和服务变化的基础上,较为精准地为用户推荐所需的移动服务是服务推荐领域的难点与重点。
技术实现要素:
为了解决现有技术中存在的以上问题,本发明提供了一种基于用户偏好与服务变化双向感知的移动服务推荐方法。该方法能实现用户偏好与服务变化的双向感知,并根据感知结果进行精准的移动服务推荐。
本发明的目的是通过以下技术方案实现的:
一种基于用户偏好与服务变化双向感知的移动服务推荐方法,包括如下步骤:
步骤一、部署数据采集系统,监控应用市场里六种类型下的所有移动服务,每天定时采集这些移动服务的前端数据,并对采集的数据进行处理,生成服务的新增与退出、服务的受欢迎度以及服务的更新功能集合信息;
步骤二、收集用户的移动服务使用记录,计算各个移动服务的活跃度,形成用户的移动服务轨道数据;
步骤三、选择某个历史时间段history,获取在history时间段内p个用户,总计v个移动服务的轨道数据track_data以及history时间内这v个移动服务的更新功能集合udatefunction_history,构建track_data与udatefunction_history之间的关系模型;
步骤四、使用步骤三建立好的关系模型,根据当前时间段current用户的移动服务轨道数据,预测用户期望的更新功能更集合,并从数据采集系统在current时间段内监控的移动服务中选择契合用户期望的移动服务推荐给用户。
相比于现有技术,本发明具有如下优点:
本发明充分考虑了用户真实兴趣偏好和服务两者的动态变化,并根据历史数据建立起了用户兴趣偏好变化与服务功能变化之间的关系模型,通过关系模型可以较为精确地预测用户期望的更新功能集合,根据预测的结果推荐给用户的移动服务能够最大程度契合用户的期望。
附图说明
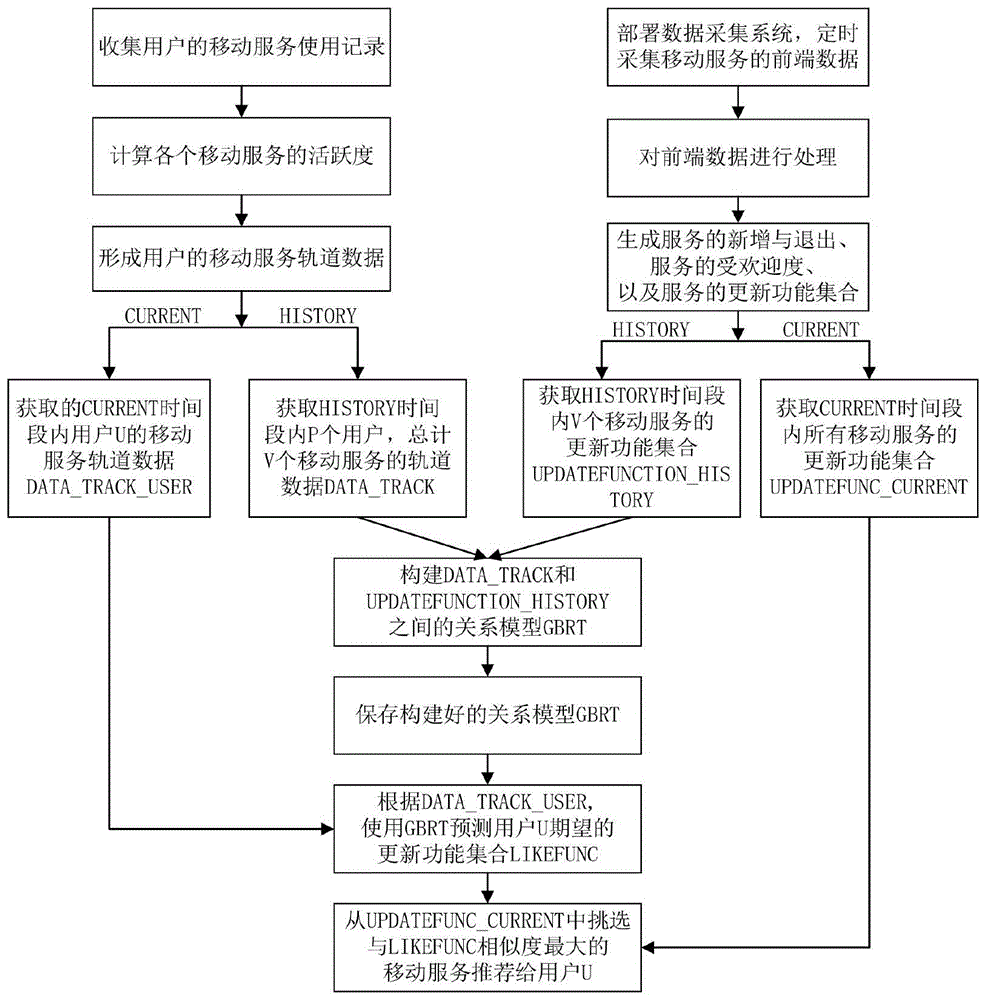
图1是本发明移动服务推荐方法的工作流程示意图;
图2是本发明功能抽取器的工作流程示意图;
图3是本发明gbrt模型的构建示意图。
具体实施方式
下面结合附图对本发明的技术方案作进一步的说明,但并不局限于此,凡是对本发明技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,均应涵盖在本发明的保护范围中。
本发明提供了一种基于用户偏好与服务变化双向感知的移动服务推荐方法,如图1所示,所述方法具体包括如下步骤:
步骤一、部署数据采集系统,监控应用市场里六种类型下的所有移动服务,每天定时采集这些移动服务的前端数据,并对采集的数据进行一系列处理,生成服务的新增与退出、服务的受欢迎度以及服务的更新功能集合等信息。
本步骤中,数据采集系统监控的移动服务所属的六种类型分别是便捷生活、影音播放、社交网络、新闻资讯、学习办公以及网购支付。
本步骤中,移动服务的前端数据包括六种类型下所有移动服务的统一资源定位符url、移动服务的下载量download、好评率likerate以及最新版本更新内容updatecontent。
本步骤中,服务的新增与退出信息是通过对比相邻两次采集的所有移动服务的统一资源定位符集合来获取的,假设前一次采集的统一资源定位符的集合为lasturls,本次采集的统一资源定位符集合为nowurls,则新增的服务为nowurls和lasturls的差集nowurls\lasturls,退出的服务为lasturls与nowurls的差集lasturls\nowurls。
本步骤中,服务的受欢迎度popularity定义为移动服务的下载量download与移动服务的好评率likerate乘积:
popularity=download×likerate。
本步骤中,服务的更新功能集合updafunction是指通过功能抽取器从最新版本更新内容updatecontent中抽取的功能短语,其工作流程如图2所示,功能抽取器先对最新版本的更新内容updatecontent进行分词,然后进行词性标注,再进行依存语法分析,最后从分析结果中抽取出名词加动词的主谓短语。
步骤二、收集用户的移动服务使用记录,计算各个移动服务的活跃度,形成用户的移动服务轨道数据。
本步骤中,假设用户的相关移动服务有s1,s2,…sn,移动服务的活跃度指的是一段时间内用户花费在该移动服务的总时长,其中一段时间可以为一周。假设该段时间内活跃度最高的是移动服务si,活跃度值为lt,活跃度最低的是移动服务sj,活跃度值为st,则将区间[lt,st]划分成10个更小的等长区间[lt1,st1],…,[lt10,st10],每个区间称之为一个轨道,区间的编号i为轨道的值,轨道值越小,代表该移动服务越频繁被使用,每个移动服务根据其使用时长划分到相应的轨道,例如,si的活跃度值在[lti,sti]之间,则si的轨道为i。用户使用的所有移动服务及其轨道(s1,track1),(s2,track2),…,(sn,trackn)汇集起来便形成了本步骤所述的用户的移动服务轨道数据。
步骤三、选择某个历史时间段history,获取在history时间段内p个用户,总计v个移动服务的轨道数据track_data以及history时间内这v个移动服务的更新功能集合udatefunction_history,构建track_data与udatefunction_history之间的关系模型。
本步骤中,历史时间段history是一段长为m周的时间,移动服务轨道数据来自于p个用户,总共涵盖v个移动服务,平均每个用户包含大约v/p个移动服务,最终得到的移动服务轨道数据track_data如下所示:
其中,si表示第i移动服务,[tracki1,…trackim]表示第i个移动服务1至m周的轨道值。
m周内v个移动服务的更新功能集合
updatefunction_history如下所示:
其中,ufi表示第i移动服务在1至m周的更新功能集合。
本步骤中,track_data与updatefunction_history之间关系的构建主要采用集成学习方法中的梯度上升回归树(gbrt)模型,具体包括以下分步骤:
①对于track_data中每个移动服务si的轨道序列[tracki1,…trackim],提取其统计特征xi1、熵特征xi2以及分段特征xi3,其中:统计特征xi1包括最小(min)、最大值(max)、均值(mean)、方差(var),熵特征xi2包括binnedentropy、approximateentropy,分段特征xi3包括分段聚合逼近(paa),将这三类特征连接成一维的特征向量xi=[xi1,xi2,xi3]。所述的binnedentropy、approximateentropy、paa的计算方法分别如下:
a、binnedentropy:
从熵的定义出发,考虑把序列t的取值进行分桶操作,将[min(t),max(t)]等分为maxbin个桶,t的取值就会分散在这maxbin个桶中,根据等距分桶的情况,计算出这个概率分布的熵:
其中,pk表示序列t的取值落在第k个桶的概率,maxbin表示桶的个数,len(t)表示序列t的长度。
如果序列t的binnedentropy的取值较大,说明序列t的取值是较为均匀的分布在[min(t),max(t)]之间的,相反,如果取值较小,说明取值是集中在某一段的。
b、approximateentropy:
假设序列t:{t1,…tn}的长度为n,同时approximateentropy拥有两个参数q和r,计算approximateentropy的步骤如下:
step1:固定两个参数,正整数q和整数r,q是为了对序列进行一个片段的提取,r是表示两个序列之间距离的参数,需要构造新的q维向量如下:
step2:通过新的向量t1(q),…tn-q+1(q),计算哪些向量与ti较为相似:
在这里,距离d通常选择l2范数;
step3:考虑函数
step4:approximateentropy的值为:
approximateentropy(q,r)=φm(r)-φm+1(r);
如果序列x具有某种趋势或重复片段,那么它的approximateentropy就会很小,反之,如果序列x几乎是随机出现的,那么它的approximateentropy就会很大。
c、paa:
假设原始序列是t:{t1,…tn},产生的paa序列为
式中,n表示原始序列的长度,w表示产生的paa序列的长度,w取值越小,paa对原始序列的抽象程度越低,在这里,w通常取3~5,i={1,2,…,w}。
②使用lda主题模型对updatefunction_history的每一个移动服务si的更新功能集合ufi进一步抽象表示,形成主题分布向量tsi,将该向量作为目标变量yi的值。
③将上述两个步骤中得到的移动服务si的特征向量xi以及其对应的目标变量yi作为第i条训练样例,v个移动服务总共构成大小为v条训练样例的训练集,输入gbrt模型进行训练,并将训练结束后的模型持久化到磁盘。
步骤四、使用建立好的关系模型,根据当前时间段current用户的移动服务轨道数据,预测用户期望的更新功能更集合,并从数据采集系统在current时间段内监控的移动服务中选择契合用户期望的移动服务推荐给用户。若current时间段内用户的移动服务轨道数据为track_data_user,预测的用户期望的更新功能集合的主题分布向量为tu',则步骤一current时间段内监控的所有移动服务的更新功能集合为updatefunction_current,将其中每一个移动服务的更新功能集合通过主题模型表示成主题分布向量tsi',计算tsi'与用户期望的主题分布向量tu'之间的相似度,并将相似度最大的移动服务推荐给用户。
本步骤中,选择的当前时间段current是最近u周,用户移动服务轨道数据为track_data_user,数据采集系统监控下的最近u周所有移动服务的更新功能集合为updatefunction_current,加载训练好的gbrt模型,预测用户期望的更新功能集合的主题分布向量tu',然后再将updatefunction_current中的每一个移动服务si'的更新功能集合ufi'通过主题模型表示成主题分布向量tsi',计算其与tu'的相似度,最后将相似度最大的移动服务推荐给用户。
本步骤中,tsi'和tu'相似度的度量采用余弦相似度计算方法,余弦相似度计算方法的公式为:
- 还没有人留言评论。精彩留言会获得点赞!