基于神经网络的短文本情感分类方法及装置与流程
本发明涉及神经网络技术领域,更具体的说是涉及一种基于神经网络的短文本情感分类方法及装置。
背景技术:
目前,随着计算机科学和技术的不断发展和成熟,出现了大量的社交平台和电子商务平台。根据42期“中国互联网发展统计报告”,2018年6月,我国互联网的用户数目达到80200万,互联网的普及率为57.7%。对比2011年的5.13亿,可见互联网正在飞速发展,全民网络时代已经到来。由于操作方便,传输速度快,范围广,实时共享,社交网络平台广受欢迎。新闻报道或社交平台,是社会热点的主要传播渠道。由于新闻报道缺少实时性,传播范围小,故社交网络平台在事件的传播中发挥着重要作用。在众多社交平台中,微博影响力最大。根据《2017年微博用户发展报告》,截至2017年9月,微博每月的活跃用户比去年同时期增长了27%,达到3.76亿,每日活跃用户达到1.65亿,比2016年同期增加25%。微博通常聚焦于一个公开评论或转发的社会事件,内容简洁,精炼,可以更加直接明了地表达发表者的感受和看法,情感倾向也更加明显。对博文进行分析,可以及时了解社会舆情,可以帮助公共管理部门采取相应的解决措施。还可以监控微博用户的情绪,如若发现博主表现出极端情绪,比如自杀倾向,可以及时采取相应措施对该用户进行情绪疏导。文本情感分类的研究起步于国外,主要针对英文文本。近年来互联网行业在国内的发展突飞猛进,社交网络和电商平台上涌现出海量的评论内容,如何分析获取有价值的信息是当前国内情感分析的主要任务。
随着云计算和大数据时代的到来,计算能力的提高使得模型培训所花费的时间减少了。训练数据量的增加也降低了训练模型过度拟合的风险。在自然语言处理方面,国内外的很多学者都在此领域进行的大量的研究,其中bengio等人通过深度学习方法进行了多项工作,包括使用神经语言模型进行词向量的学习,最终实现分类任务。pal等人,通过多lstm层叠加提高了分类精度,将lstm层双向化数据的前向和反向传播。liujie等人,首先利用两个独立的bi-gru层分别得到词性和句子表示,结合辅助标签的概率与隐藏层的特征,捕获输出标签间的相关性。luo等人,首先利用lda主题模型构建基于主题分布的短文本特征向量表示,然后使用加入了gru的cnn作分类器,gru-cnn加强了词间和文本间的关系,实现了高精度的文本分类。
但是,在进行神经网络的优化训练阶段,现有的大多研究多采用小批量梯度下降算法。在采用小批量梯度下降算法进行模型训练时,随着训练的进行,我们所期望的是神经网络模型的loss值应该越来越接近全局最小值,而loss值倾向于降到局部最小值,在局部最小值附近反复振荡,使得模型的训练停滞不前,降低了最终的分类结果。并且在训练过程中relu函数在x<0时难以饱和,使得权重无法更新,导致神经元死亡,即样本失效,模型无法训练;输出全部为正值,出现偏移问题,影响模型的学习能力。
因此,如何建立可靠模型实现对文本价值信息的获取,并进行准确的情感分析是本领域技术人员亟需解决的问题。
技术实现要素:
有鉴于此,本发明提供了一种基于神经网络的短文本情感分析方法及装置,采用小批量梯度下降算法对分类模型进行训练,建立分类模型,在建模过程中利用基于热重启和余弦退火的训练批量周期变化策略sgdr改变传统小批量梯度下降算法中固定不变的训练批量,以此对学习率做出调整,加快梯度下降收敛速度,并提高模型精度;并采用新的激活函数srelu来进行建模过程中的非线性计算,解决缓解梯度弥散和输出偏移问题。
为了实现上述目的,本发明采用如下技术方案:
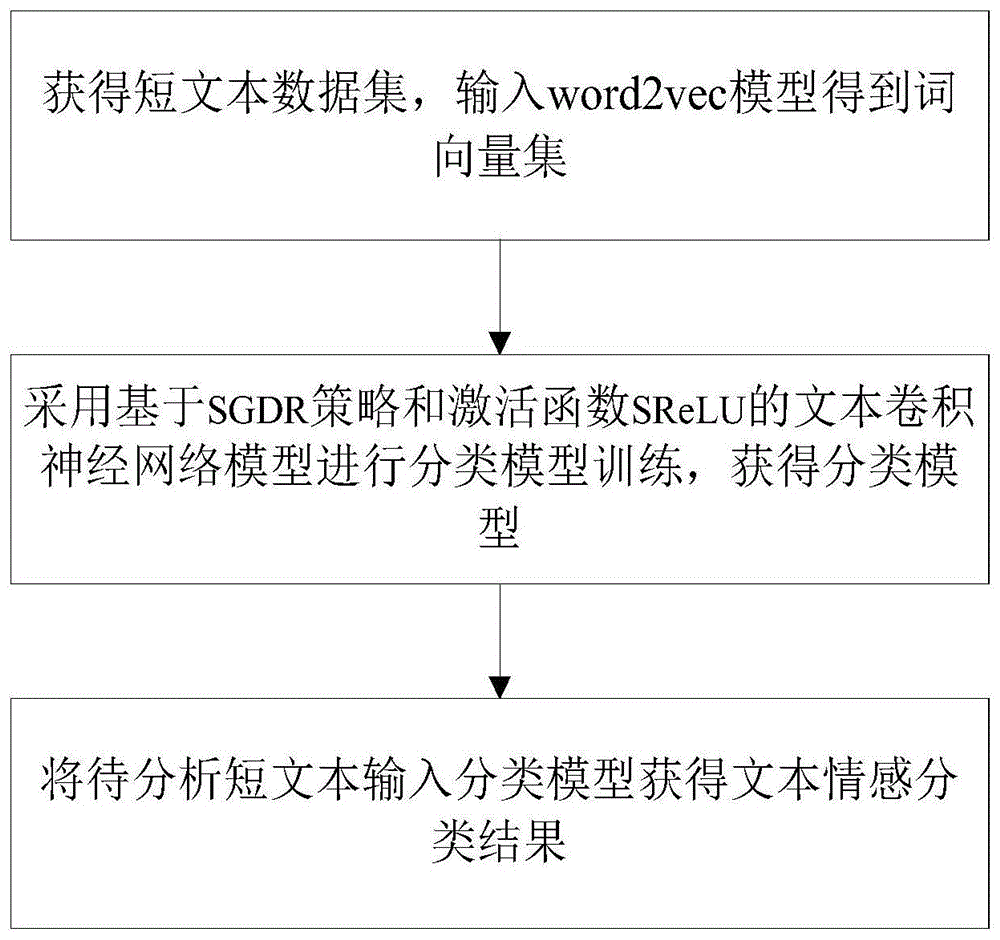
一种基于神经网络的短文本情感分析方法,包括:具体实现过程为:
步骤1:获取短文本数据集,将所述短文本数据集输入word2vec模型得到词向量集;
步骤2:所述词向量集作为样本数据采用文本卷积神经网络textcnn进行分类模型训练,在所述分类模型训练过程中采用小批量梯度下降算法进行优化,所述小批量梯度下降算法中利用基于热重启和余弦退火的训练批量周期变化策略sgdr和激活函数srelu,加快梯度下降收敛速度以及缓解梯度弥散和输出偏移,最终训练获得所述分类模型;
步骤3:输入待分析短文本,根据所述分类模型对所述待分析短文本进行情感分类,得到分类结果。
优选的,设置所述模型的损失值阈值,所述步骤2中采用文本卷积神经网络textcnn建立分类模型的具体过程为:
步骤21:输入所述样本数据至卷积层中不同尺寸的卷积核中进行特征提取运算,得到卷积层输出,所述卷积层输出为一维向量;
步骤22:将所述卷积层输出输入至池化层,采用serlu激活函数进行非线性映射,并通过取最大值的方式进行下采样,获得池化层输出;
步骤23:将所述池化层输出注入至全连接层进行拼接,获得拼接向量,对所述拼接向量进行全连接操作,并采用serlu激活函数进行非线性映射,生成最终表示向量;
步骤24:将所述最终表示向量输入至softmax层进行分类获得概率结果,再通过交叉熵损失公式计算获得损失值;最后采用基于热重启与余弦退火的训练批量周期变化策略sgdr的小批量梯度下降算法对损失函数进行优化,并进行网络参数的更新;
步骤25:如果所述损失值小于所述损失值阈值,则所述模型训练结束获得所述分类模型;否则,进入步骤21。
优选的,基于热重启和余弦退火的训练批量周期变化策略sgdr的小批量梯度下降算法的具体实现过程为:
步骤241:初始化参数,获得初始化参数模型,输入所述样本数据,取出一定数量的数据作为训练批量,将所述样本数据分为若干所述训练批量,所有所述训练批量输入所述初始化参数模型进行训练,所述训练的过程是配置最优参数的过程;初始设定最大训练批量为b_smax,当前训练批量为b_st,训练批量衰减比率为α;在所述最大训练批量下,设定训练周期数epoch;所有所述训练批量完成所述训练周期所需训练轮数为steps_per_epoch,最大训练批量周期衰减比率为bs_decay,所有所述训练批量完成训练的周期长度为c_length,在每个批量训练周期完成之后的周期缩放比率为tm;总迭代轮数tall=0;热重启迭代轮数tcur=0;
步骤242:开始训练,返回最大训练批量b_smax,初始设定热重启周期next_restart=c_length;
步骤243:训练批次,采用sgdr策略确定下轮训练的所述训练批量;
步骤244:更新总迭代轮数tall=tall+1,记录所述步骤243中的所述训练批量为历史训练批量,更新所述热重启迭代轮数tcur=tcur+1;
ti=steps_per_epoch*c_length
其中,ti为当前重启周期;αi表示第i次训练步骤的衰减比率;b_st为经过此轮迭代的所述当前训练批量;
步骤245:完成完整的训练周期,判断所述训练周期数epoch是否等于所述热重启周期next_restart;如果相等,则对所述参数进行更新,并输出所述当前训练批量;如果不相等,则所述热重启迭代轮数tcur=0,所述周期长度c_length=c_length×tm,所述热重启周期next_restart=next_restart+c_length,最大训练批量b_smax=b_smax×bs_decay,返回所述步骤242。
优选的,所述步骤2中的激活函数srelu具体表示为:
其中,λ是固定参数,是输入x>0时的斜率因子,λ越大,所述激活函数的导数值越大,变化越快;α为所述激活函数在负区间的饱和点位置;β为所述激活函数负值部分的截距,设β<-0.5,使的所述激活函数srelu的负区间的输出值总小于0,|β|表示函数负值部分与y轴的交点到原点的距离,β越大,距离越近。所述激活函数srelu解决了relu函数的零梯度问题,延缓了神经元坏死的问题,平均值更接近于0,在一定程度上降低了函数的偏移值。
一种基于神经网络的短文本情感分类装置,包括:
获取转换模块,获取输入短文本数据集,并输入word2vec模型得到词向量集;建模模块,采用文本卷积神经网络textcnn进行分类模型建模,并利用基于热重启和余弦退火的训练批量周期变化策略sgdr的小批量梯度下降算法以及激活函数srelu进行模型优化;
情感预测模块,存储所述分类模型,输入待分析短文本,根据所述分类模型进行情感分类,获得分类结果。
经由上述的技术方案可知,与现有技术相比,本发明公开提供了一种基于神经网络的短文本情感分类方法及装置,使用训练集数据,通过word2vec得到输入的词向量,基于小批量梯度下降算法训练深度学习模型,建模过程中,采用基于热重启与余弦退火的训练批量周期变化策略sgdr,该方法不是单调地或者随机的改变batch_size,而是使batch_size在合理的边界值之间循环变化,确定每次参与模型训练的数据批量,进行学习训练模型,使用循环batch_size而不是固定值进行训练,可以用于加速模型收敛,提高模型精度。然后基于已有的激活函数,采用新的激活函数srelu函数,用于建模过程中的非线性运算,解决缓解梯度弥散和输出偏移问题,最终得到用于分类的神经网络模型。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1附图为本发明提供的基于神经网络的短文本情感分类方法流程示意图;
图2附图为本发明提供的分类模型建模过程原理图;
图3附图为本发明提供的sgdr策略的batch_size变化图结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明实施例公开了一种基于神经网络的短文本情感分析方法,包括:具体实现过程为:
s1:获取短文本数据集,将短文本数据集输入word2vec模型得到词向量集;
s2:词向量集作为样本数据采用文本卷积神经网络textcnn进行分类模型训练,在分类模型训练过程中采用小批量梯度下降算法进行优化,小批量梯度下降算法中利用基于热重启和余弦退火的训练批量周期变化策略sgdr和激活函数srelu,加快梯度下降收敛速度以及缓解梯度弥散和输出偏移,最终训练获得分类模型;
s3:输入待分析短文本,根据分类模型对待分析短文本进行情感分类,得到分类结果。
为了进一步优化上述技术方案,设置模型的损失值阈值,s2中采用文本卷积神经网络textcnn建立分类模型的具体过程为:
s21:输入样本数据至卷积层中不同尺寸的卷积核中进行特征提取运算,得到卷积层输出,卷积层输出为一维向量;
s22:将卷积层输出输入至池化层,采用serlu激活函数进行非线性映射,并通过取最大值的方式进行下采样,获得池化层输出;
s23:将池化层输出注入至全连接层进行拼接,获得拼接向量,对拼接向量进行全连接操作,并采用serlu激活函数进行非线性映射,生成最终表示向量;
s24:将最终表示向量输入至softmax层进行分类获得概率结果,再通过交叉熵损失公式计算获得损失值;最后采用基于热重启与余弦退火的训练批量周期变化策略sgdr的小批量梯度下降算法对损失函数进行优化,并进行网络参数的更新;
s25:如果损失值小于损失值阈值,则模型训练结束获得分类模型;否则,进入步骤21。
为了进一步优化上述技术方案,基于热重启和余弦退火的训练批量周期变化策略sgdr的小批量梯度下降算法的具体实现过程为:
s241:初始化参数,获得初始化参数模型,输入样本数据,取出一定数量的数据作为训练批量,将样本数据分为若干训练批量,所有训练批量输入初始化参数模型进行训练;初始设定最大训练批量为b_smax,当前训练批量为b_st,训练批量衰减比率为α;在最大训练批量下,设定训练周期数epoch;所有训练批量完成训练周期所需训练轮数为steps_per_epoch,最大训练批量周期衰减比率为bs_decay,所有训练批量完成训练的周期长度为c_length,在每个批量训练周期完成之后的周期缩放比率为tm;总迭代轮数tall=0;热重启迭代轮数tcur=0;s242:开始训练,返回最大训练批量b_smax,初始设定热重启周期next_restart=c_length;
步骤243:训练批次,采用sgdr策略确定下轮训练的训练批量;
s244:更新总迭代轮数tall=tall+1,记录s243中的训练批量为历史训练批量,更新热重启迭代轮数tcur=tcur+1;
ti=steps_per_epoch*c_length
其中,ti为当前重启周期;αi表示第i次训练步骤的衰减比率;b_st为经过此轮迭代的当前训练批量;
s245:完成完整的训练周期,判断训练周期数epoch是否等于热重启周期next_restart,如果相等,则对s241中的参数进行更新,即确定训练批量的参数以及参与训练的训练批量,并输出当前训练批量;如果不相等,则热重启迭代轮数tcur=0,周期长度c_length=c_length×tm,热重启周期next_restart=next_restart+c_length;最大训练批量b_smax=b_smax×bs_decay,返回s242。
为了进一步优化上述技术方案,s2中的激活函数srelu具体表示为:
其中,λ是固定参数,是输入x>0时的斜率因子,λ越大,激活函数的导数值越大,变化越快;α为激活函数在负区间的饱和点位置;β为激活函数负值部分的截距,设β<-0.5,使的激活函数srelu的负区间的输出值总小于0,|β|表示函数负值部分与y轴的交点到原点的距离,β越大,距离越近。激活函数srelu解决了relu函数的零梯度问题,延缓了神经元坏死的问题,平均值更接近于0,在一定程度上降低了函数的偏移值。
一种基于神经网络的短文本情感分类装置,包括:
获取转换模块,获取输入短文本数据集,并输入word2vec模型得到词向量集;建模模块,采用文本卷积神经网络textcnn进行分类模型建模,并利用基于热重启和余弦退火的训练批量周期变化策略sgdr的小批量梯度下降算法以及激活函数srelu进行模型优化;
情感预测模块,存储分类模型,输入待分析短文本,根据分类模型进行情感分类,获得分类结果。
实施例
(1)小批量梯度下降算法
训练批量:训练开始时建立初始模型,每次从样本数据中随机抽取一定数量的数据放入初始模型进行训练,训练过程就是配置模型最优参数的过程,抽取的一定数量的数据称为训练批量。
训练周期(周期):通过一定数量的训练批量将所有的训练数据都放入模型中训练完成,这个过程周期称为训练周期。
重启周期:训练批量从一个峰值(最大值)衰减到预设最小训练批量所经历的训练步骤数。
训练步骤:用训练批量的数据训练一次模型,记为一个训练步骤。
批量训练周期:是指初始化一个批量大小,经sgdr策略开始衰减,一直到重启(即batch-size重新设为初始大小)为止。
在采用小批量梯度下降算法进行模型训练过程中,设置一个较小的重启周期,在每次重启之后适当按比率tm增大重启周期,同时在重启之后按比率最大训练批量周期衰减比率bs_decay衰减最大训练批量会取得更好的效果。图3所示为sgdr策略的batch_size变化图,纵坐标表示训练批量,横坐标表示训练的batch数,batch为使用训练集的一小部分样本,对模型的权重进行一次反向传播(利用梯度下降法)的参数更新,其中的部分样本称为一个batch,每个batch中含有的样本数量称为batch-size,其中预设b_smax=256,c_length=1,tm=1.2,bs_decay=0.9。
(2)激活函数
本发明在传统激活函数relu函数在负值区间参考sigmoid函数对正值输入的处理方式,添加了固定参数,使得当输入一个负值时,得到一个负值,解决了relu函数的零梯度问题,延缓了神经元坏死的问题。对于正值区间,参考了relu函数的处理方式,以减少梯度消失问题。综上所述,srelu函数解决了零梯度问题,缓解了函数值的偏移问题。
激活函数srelu函数的导数公式:
其中,s(x)如下公式(2)所示。
为确保srelu函数在0点处可导,如下公式(3)所示为添加的参数约束:
为了避免反向传播中的梯度弥散或爆炸问题,srelu函数中λ的设置如公式(4)所示:
λ=1(4)
求解公式(3),得到以下结果:
综上所述,srelu函数的准确数学表达式为公式(6)所示:
srelu函数的导数公式(1)可表示为公式(7):
利用srelu函数对分类模型进行参数化非线性变换,得到输出的平均值osrelu,如下公式(8)所示:
其中,w表示输入x对应的概率,x+表示正值区间输入,x-表示负值区间输入。
而传统relu函数的输出平均值orelu如公式9所示:
orelu(x)=∑wfrelu(x)
=∑wx+(9)
对比上述osrelu和orelu,由于概率w永远取值为正,公式(8)由正负两项组成,在一定程度上可以将srelu函数输出的平均值校正为0,而公式(9)中relu函数的输出平均值orelu永远保持为正值,故srelu函数可以在一定程度上缓解传统relu函数的偏移问题。
(3)验证模型的分类的准确性
1)实验数据收集:
从csdn上下载得到新浪微博文本数据集,共有121509条博文,已完成人工情感标注,“1”代表积极,“2”代表消极,“3”表示中立,表现为积极情感的文本共50351条,表现为消极情感的共50279条,表现为中立的为20879条。
2)实验环境搭建,设置具体实验设备和参数如下表1实验参数表所示。
表1实验参数表
3)数据预处理
首先要对实验文本进行预处理,包括去噪、去停用词以及分词等步骤。微博文本中可能有噪声存在,如“#”、“@”、“【”、“】”、“http”等,在一定程度上对文本情感的倾向性判定带来一些干扰,降低最终情感倾向性判定的准确率。使用jieba分词工具,对去噪处理的文本进行分词。通过整合现有的停用词表,得到了一份较为全面的停用词表,利用分词工具载入停用词表,在完成分词的同时去掉停用词。
4)特征提取
根据数据预处理后的文本建立相应的词典,基于词集训练词向量矩阵,对预处理文本采用word2vec获得词向量,使用的word2vec基于skip-gram模型,词向量维度为256,词向量上下文的最大距离为默认值5。参与词向量训练的最小词频取值为2,可以去掉预料中的部分生僻词,选择基于hierarchicalsoftmax的优化目标函数,参与训练的线程数为8,即同时进行8组训练,随机梯度下降法中的最大迭代次数为20。
5)模型训练
基于应用srelu函数的文本卷积神经网络模型进行模型训练,并使用提出的动态调整训练样本批数量大小的sgdr策略在反向传播中对其进行模型的优化训练,使batch_size在合理的边界值之间循环变化。
6)结果展示
①基于srelu函数的实验结果及分析
首先选用原始的小批量梯度下降mbgd算法对模型进行训练,对比多种激活函数进行实验说明。各激活函数的实验对比结果如下表2所示:
由表2可知,srelu函数得到了最佳的实验效果,其“宏查准率”和“宏f1”分别为91.46%、93.12%。经过实验得出,本文提出的srelu函数的实验结果相较于其他激活函数的实验结果均有提高,一定程度上验证了srelu函数的有效性。
②基于热重启与余弦退火的训练批量周期变化策略的实验结果及分析
采用小批量梯度下降mbgd算法进行textcnn的训练,在此过程中不同训练批量batch_size的大小对实验结果会产生不同的影响,采用sgdr算法,对不同初始化大小的batch_size进行周期性调整,对比实验结果如下表3所示。
由表3可知,sgdr算法取得了各项评估指标的最佳实验结果,其各项结果均优于mbgd算法,对于batch_size不同大小的初始化中,初始化大小为128时取得最佳的实验结果,其“宏查准率”和“宏f1”分别为91.24%和93.01%。
基于应用srelu函数的文本卷积神经网络模型,使用提出的动态调整训练样本批数量大小的sgdr策略在反向传播中进行模型的优化训练,使batch_size在合理的边界值之间循环变化。初始化batch_size的大小为128,将采用srelu函数和sgdr策略的文本卷积神经网络textcnn构建模型与其他几个比较常用的神经网络模型进行对比实验。综合实验对比结果如下表4所示。
由表4可知,基于应用srelu函数的文本卷积神经网络模型,使用提出的动态调整训练样本批数量大小的sgdr策略的实验结果最佳,其宏查准率、宏准确率以及宏f1分别为91.66%、97.41%和93.21%,由此对提出方法的有效性进行了验证。
本发明采用基于应用srelu函数的文本卷积神经网络模型进行分类模型训练,弥补了传统激活函数收敛速度慢,网络不易收敛,计算量大等缺点,还解决了relu函数的偏移,负值区间神经元坏死等问题,改进后的srelu函数不仅具备光滑性,还具备稀疏性。使用提出的动态调整训练样本批数量大小的sgdr策略在反向传播中对其进行模型的优化训练,使batch_size在合理的边界值之间循环变化。使用循环变化的batch_size而不是固定值进行训练。它可用于加速模型收敛,提高模型精度,并改善模型多样性。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!