一种数据可信处理方法与流程
【技术领域】
本发明属于数据可信领域,尤其涉及一种数据可信处理方法。
背景技术:
新一代核心系统建设伊始就面临着系统日渐繁多、数据量逐日剧增的现实情况。数据是银行的重要战略资产,如何最大程度的利用数据资源、服务于信息化建设的高速发展,对新一代核心系统建设的成功具有重大的保障意义。其中,提升数据质量对于充分发挥数据资源的价值而言是重中之重,而提升数据质量的根本出发点和落脚点就是要保证数据的一致性。随着系统增多和数据量爆炸式增长,数据质量问题已经成为了迫在眉睫的问题,而数据一致性是提升数据整体质量的基础,是为新一代核心系统建设顺利进行提供良好的数据支撑基础。中国建设银行在新一代建设之前,对数据的一致性管理大都还停留在系统级别,全行范围内缺乏一套企业级视角并且可以实施并落地的整体方案。其它银行也存在类似问题。基上述诸多问题,现在亟需一种新的数据可信处理方法,本发明能够对获取的用户数据的可信性进行量化评分,从用户和用户所处的客户端两方面同时出发考虑用户数据的可信性,使得可信评分不仅仅包括设备因素,还包括人为因素,以获取全方位的评分结果,精确的进行可信性的刻画,大大的提高了数据可信处理的效率和准确性。
技术实现要素:
为了解决现有技术中的上述问题,本发明提出了一种数据可信处理方法,该方法包括如下步骤:
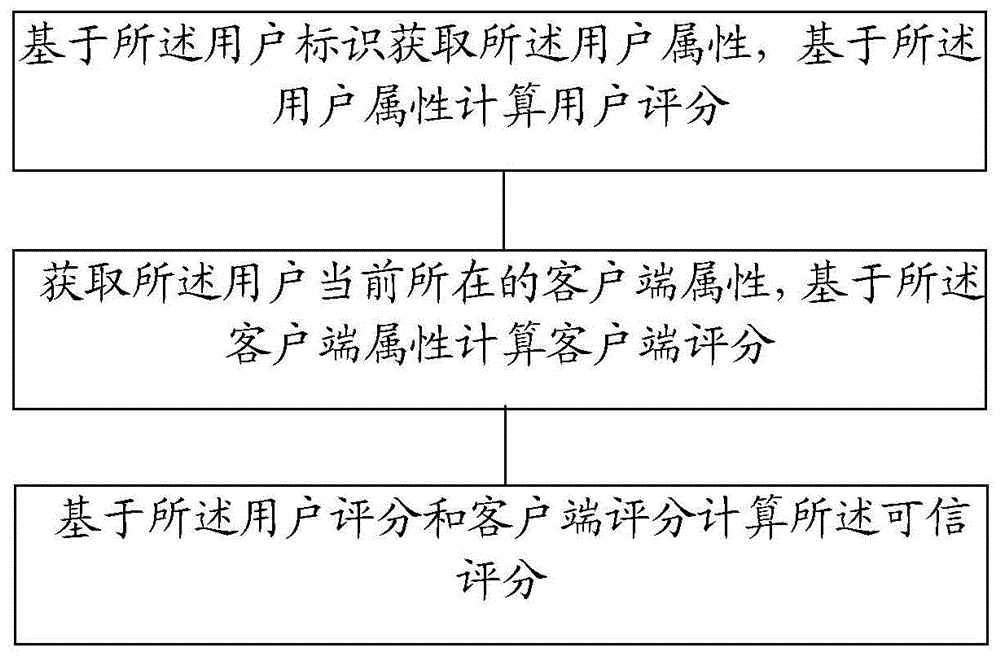
s11:基于所述用户标识获取所述用户属性,基于所述用户属性计算用户评分;
s21:获取所述用户当前所在的客户端属性,基于所述客户端属性计算客户端评分;
s31:基于所述用户评分和客户端评分计算所述可信评分。
进一步的,所述基于所述用户标识获取所述用户属性,基于所述用户属性计算用户评分,具体为:所述用户属性包括用户最近n次的历史用户评分hus、用户使用习惯等级hl、用户规律性等级rl、用户违规次数on;基于下式(1)计算所述用户评分us;
其中:husi为第i次的用户历史评分;i=1~n;w1~w4为调整值。
进一步的,所述调整值为预设值;
进一步的,所述用户属性和用户标识关联的保存在后台数据库中。
进一步的,所述获取所述用户当前所在的客户端属性,基于所述客户端属性计算客户端评分,具体为:所述客户端属性包括所述客户端的可信等级cfl、所述客户端的非可信次数nfn、所述客户端的专用等级asl;所述客户端和外界通信连接的可信等级cfl;
基于下式(2)计算所述客户端评分cs;
cs=wc1×cfl+wc2×nfn+wc3×asl+wc4×cfl(2);
其中:wc1~wc4为调整值。
进一步的,通过向客户端发送请求以获取所述客户端属性。
进一步的,所述可信等级指示所述客户端的可信性程度,所述非可信次数对客户端发生的非可信访问次数进行计数;。
进一步的,基于下式asl=usert/(b_usern×uern)计算所述专用等级;其中:usert为第三时间范围使用所述客户端的用户人次;usern为第三时间范围使用所述客户端的用户个数;b_usern为基准用户个数,所述基准用户个数为预设值。
进一步的,所述基于所述用户评分us和客户端评分cs计算所述可信评分,具体为:基于下式(3)计算所述可信评分fscore;
本发明的有益效果包括:能够对获取的用户数据的可信性进行量化评分,从用户和用户所处的客户端两方面同时出发考虑用户数据的可信性,使得可信评分不仅仅包括设备因素,还包括人为因素,以获取全方位的评分结果,精确的进行可信性的刻画,大大的提高了数据可信处理的效率和准确性。
【附图说明】
此处所说明的附图是用来提供对本发明的进一步理解,构成本申请的一部分,但并不构成对本发明的不当限定,在附图中:
图1是本发明的数据可信处理方法的流程图。
【具体实施方式】
下面将结合附图以及具体实施例来详细说明本发明,其中的示意性实施例以及说明仅用来解释本发明,但并不作为对本发明的限定。
对本发明所应用的一种数据可信处理方法进行详细说明,所述方法包含下述步骤:
s1:服务器从客户端获取用户数据;具体的:在获取间隔到达时,基于当前时间判断是否存在和所述当前时间对应的用户标识列表,基于所述用户标识列表向所述用户标识列表中的每个用户标识对应的客户端发送用户数据获取请求,客户端在接收到所述用户数据获取请求后,将用户数据进行打包后发送给服务器,服务器接收打包数据并进行数据包解析以获取用户数据;
优选的:所述客户端为一个或多个;
每个获取间隔到达时的当前时间有对应用户标识列表,所述用户标识列表保存了所有需要进行用户数据获取的用户标识;
优选的:获取间隔为进行用户数据获取的最小时间间隔;在获取间隔到达时,进行下一获取间隔到达时对应的用户标识列表的更新;所述用户标识列表包括固定部分和临时部分;所述固定部分指示需要进行定期的用户数据获取的用户标识,所述临时部分指示零散而非周期性的需要进行用户数据获取的用户标识;
所述进行下一获取间隔到达时对应的用户标识列表的更新,具体为:基于每个用户属性,判断所述用户在下一获取间隔到达时是否需要进行用户数据获取,如果需要,则将所述用户的用户标识放入所述下一获取间隔到达时对应的用户标识列表的固定部分中;所述用户属性中包含有管理员设置的获取周期等信息;
优选的:在接收到在第一时间进行针对第一用户的用户数据获取请求时,将所述第一用户的用户标识放入所述第一时间对应的用户标识列表的临时部分中;如果用户标识列表不存在,则创建新的用户标识列表;
所述基于所述用户标识列表向用户客户端发送用户数据获取请求,具体为:对于所述用户标识列表中的每个用户标识,基于所述用户标识查询用户客户端对应表以获取所述用户当前所在的客户端,并向所述客户端发送用户数据获取请求;
所述将用户数据进行打包后发送给服务器,具体为:基于所述用户属性,确定是否需要对所述用户数据进行加密处理,如果是,将所述用户数据进行加密处理后附加所述用户标识和加密标识以形成打包数据;所述加密标识指示所述打包数据是否经过加密以及加密的方式;优选的,当所述加密标识为默认值时指示未经过加密;
所述服务器接收打包数据并进行数据包解析以获取用户数据:接收打包数据,基于加密标识确定是否需要进行解密以及解密方式,如果需要进行解密则进行打包数据的解密处理以获取用户数据;
s2:对所述用户进行可信评分,具体为:基于所述用户标识获取所述用户属性,基于所述用户属性计算用户评分;获取所述用户当前所在的客户端属性,基于所述客户端属性计算客户端评分;基于所述用户评分和客户端评分计算所述可信评分;
所述基于所述用户标识获取所述用户属性,基于所述用户属性计算用户评分,具体为:所述用户属性包括用户最近n次的历史用户评分hus、用户使用习惯等级hl、用户规律性等级rl、用户违规次数on;基于下式(1)计算所述用户评分us;
其中:husi为第i次的用户历史评分;i=1~n;w1~w4为调整值,所述调整值为预设值;优选的:
优选的:所述用户属性和用户标识关联的保存在后台数据库中;通过基于用户标识访问后台数据库以获取所述用户属性;用户使用习惯等级对用户使用习惯的可信性进行评级,所述用户规律性等级为用户习惯的规律性进行评级,所述用户违规次数对用户的违规次数进行计数;其中:所述用户违规次数周期性的进行更新,仅对最近的第一时间范围内的违规次数进行计数;
所述获取所述用户当前所在的客户端属性,基于所述客户端属性计算客户端评分,具体为:所述客户端属性包括所述客户端的可信等级cfl、所述客户端的非可信次数nfn、所述客户端的专用等级asl;所述客户端和外界通信连接的可信等级cfl;
基于下式(2)计算所述客户端评分cs;
cs=wc1×cfl+wc2×nfn+wc3×asl+wc4×cfl(2);
其中:wc1~wc4为调整值,所述调整值为预设值;优选的:
优选的:通过向客户端发送请求以获取所述客户端属性;所述可信等级指示所述客户端的可信性程度,所述非可信次数对客户端发生的非可信访问次数进行计数;其中:所述非可信次数周期性的进行更新,仅对最近的第二时间范围内的非可信访问次数进行计数;所述专用等级描述了用户对客户端使用的专用性程度;所述和外界通信连接的可信程度描述了和客户端发生通信连接的通信链路的可信程度;
优选的:基于下式asl=usert/(b_usern×uern)计算所述专用等级;其中:usert为第三时间范围使用所述客户端的用户人次;usern为第三时间范围使用所述客户端的用户个数;b_usern为基准用户个数,所述基准用户个数为预设值;
所述基于所述用户评分us和客户端评分cs计算所述可信评分,具体为:基于下式(3)计算所述可信评分fscore;
优选的:所述第一时间范围、第二时间范围、第三时间范围为预设值;
s3:基于所述可信评分对用户数据进行可信处理;具体的:如果所述可信评分大于等于第一可信阈值,则不对所述用户数据进行处理,直接返回所述用户数据;否则,如果所述可信评分小于所述第一可信阈值,则基于可信评分对所述用户数据进行差异化可信处理;
所述基于可信评分对所述用户数据进行差异化可信处理,具体为:对所述可信阈值进行非线性划分以获取第二可信阈值和第三可信阈值;如果所述可信评分小于等于第二可信阈值,则采用第一处理策略进行处理;如果所述可信评分大于第二可信阈值且小于等于第三可信阈值,则采用第二处理策略进行处理;如果所述可信评分大于第三可信阈值,则采用第三处理策略进行处理;
所述对所述可信阈值进行非线性划分以获取第二可信阈值和第三可信阈值,具体为:获取所述第一可信阈值ftrd,基于公式
优选的:所述第一、第二、第三处理策略保存在后台数据库的策略表中;所述处理策略以批处理文件的形式保存;基于当前可信性要求对所述策略表进行动态修改,提高了可信性处理的实时性;
优选的:所述第一处理策略包含第一核心策略和第二、第三处理策略;所述第二处理策策略包含第二核心策略和第三处理策略;
优选的:所述第三处理策略包括清除所述用户数据中的木马程序和重复性用户数据;
优选的:所述第一核心策略的复杂度高于所述第二核心策略;
优选的;当可用处理资源的数量小于第一可用阈值时,将所述第一处理策略设置为和第二处理策略相同;
s4:将经过可信处理的用户数据进行数据集成保存;具体的:将经过可信处理的用户数据进行数据集成,并将集成数据的用户数据保存在可信缓存中;
所述将经过可信处理的用户数据进行数据集成,具体为:确定经过可信处理的用户数据的重要度,基于所述重要度将用户数据进行分组,基于分组的大小进行分组的合并和拆分,将拆分后的分组进行排序,将所有的分组按照排序顺序集成起来构成集成数据;
所述确定经过可信处理的用户数据的重要度,具体为:获取所述用户数据对应用户的重要度imu、获取所述用户数据的可信评分dfl、用户数据经过可信处理的次数pts,并基于下式计算所述用户数据的重要度imd;
imd=imu×dfl/pts(4);
基于所述重要度将用户数据进行分组,将用户数据按照重要度梯度进行分组,并为所述分组设置标签,所述标签的内容为所述重要度;优选的:所述重要度梯度为进行将重要度按照固定的重要度粒度划分为多个梯度,并将所述用户数据按照重要度分入相应的分组;
所述基于分组的大小进行分组的合并和拆分,具体为:逐个的获取每个分组的大小,如果所述分组的大小大于第一大小阈值,则将所述分组进行拆分,以形成多个大小为第一大小阈值的分组,以及一个单另的分组,将所述拆分后的分组的重要度设置为等于所述拆分前分组的重要度;如果所述分组的大小小于第二大小阈值,则将所述分组和其他分组合并以形成大小小于第一大小阈值的分组;
所述将所述分组和其他分组合并,具体为,只有当两个分组之间的重要度差值小于重要度差值阈值时,才进行两个分组的合并;并为所述合并后的分组重新设置重要度;所述重新设置的重要度等于所述两个分组的重要度中的较大者;
所述将拆分后的分组进行排序,具体为:将分组按照重要度的从大到小的顺序排序;
通过将数据按照重要度排序,并划分成符合后续处理要求大小的分组,方便了后续的处理;还能根据可信处理和数据保护条件,选择性的从头开始进行用户数据的保护;
所述将集成数据的用户数据保存在可信缓存中,具体为:计算所述集成数据的重要度,选择和所述重要度匹配的可信缓存分区中,并将所述集成数据保存在所述选择的可信缓存分区中;
所述计算所述集成数据的重要度,具体为:设置所述重要度等于集成数据中所有分组重要度的加和,并除以分组的个数;
优选的:所述可信缓存为本地缓存;
以上所述仅是本发明的较佳实施方式,故凡依本发明专利申请范围所述的构造、特征及原理所做的等效变化或修饰,均包括于本发明专利申请范围内。
- 还没有人留言评论。精彩留言会获得点赞!