分类模型的训练方法和训练装置与流程
本公开涉及机器学习领域,特别涉及一种分类模型的训练方法和训练装置。
背景技术:
基于生成式对抗网络(generativeadversarialnetworks,gan)的半监督分类方法:在训练阶段,同时训练生成式对抗网络的生成模型和分类模型。一般来说,训练分类模型所需要的迭代次数比训练生成模型所需要的迭代次数少,这会使得生成式对抗网络不太稳定。分类模型在训练时需要增加一个额外的虚假类别,专门用于识别生成模型生成的“虚假数据”,但该虚假类别在测试阶段不会被使用,这在一定程度上增加了训练的复杂性。此外,生成模型有时会生成足够真实的“虚假数据”,这样的训练数据对于训练没有帮助。
技术实现要素:
本公开可以单独训练分类模型,相对于同时训练相关的两个模型,模型的稳定性更好;并且基于生成样本数据设置用于抑制所有输出类别激活的损失函数,在真实类别的基础上不需要额外增加虚假类别,有利于降低训练的复杂度。此外,通过在特征层添加噪声的方法,在一定程度上避免生成模型生成过于真实的“虚假数据”,有利于提升训练数据的有效性和提升训练效果。
根据本公开的一方面,提出一种分类模型的训练方法,包括:
将真实样本数据和所述真实样本数据的标签数据输入待训练的分类模型,得到所述分类模型输出的第一组输出值,基于预设的第一损失函数和第一组输出值计算第一损失,并计算所述第一损失函数在所述分类模型当前参数下的第一梯度信息;
将生成样本数据输入所述分类模型,得到所述分类模型输出的第二组输出值,基于预设的用于抑制所有输出类别激活的第二损失函数和第二组输出值计算第二损失,并计算所述第二损失函数在所述分类模型当前参数下的第二梯度信息;
根据所述第一损失和所述第二损失判断所述分类模型是否收敛,在所述分类模型未收敛的情况下,基于第一梯度信息和第二梯度信息的梯度叠加信息,按照梯度下降的方法更新所述分类模型的参数,并对所述分类模型继续进行训练。
在一些实施例中,第二损失函数根据所述第二组输出值中每个输出类别上的输出值与数值小的预设值之间的差值信息确定。
在一些实施例中,第二损失函数的公式表示为:
其中,c表示输入输出类别的数量,i表示其中某个输出类别,
在一些实施例中,t小于或等于log0.0001。
在一些实施例中,所述生成样本数据通过生成模型生成,其中,所述生成模型的特征层被配置为添加噪声。
在一些实施例中,还包括:利用收敛的分类模型对输入的图像数据进行分类。
在一些实施例中,所述分类模型为图像分类模型;所述真实样本数据为真实事物的图像数据,所述真实样本数据的标签数据为标注的真实事物的种类,所述第一组输出值为真实事物的图像数据在各个种类上的概率;所述生成样本数据为对真实事物的图像数据添加噪声得到的虚假事物的图像数据,所述第二组输出值为虚假事物的图像数据在各个种类上的概率。
根据本公开的另一方面,提出一种分类模型的训练装置,包括:
第一训练单元,被配置为将真实样本数据和所述真实样本数据的标签数据输入待训练的分类模型,得到所述分类模型输出的第一组输出值,基于预设的第一损失函数和第一组输出值计算第一损失,并计算所述第一损失函数在所述分类模型当前参数下的第一梯度信息;
第二训练单元,被配置为将生成样本数据输入所述分类模型,得到所述分类模型输出的第二组输出值,基于预设的用于抑制所有输出类别激活的第二损失函数和第二组输出值计算第二损失,并计算所述第二损失函数在所述分类模型当前参数下的第二梯度信息;
判断单元,被配置为根据所述第一损失和所述第二损失判断所述分类模型是否收敛;
模型参数更新单元,被配置为在所述分类模型未收敛的情况下,基于第一梯度信息和第二梯度信息的梯度叠加信息,按照梯度下降的方法更新所述分类模型的参数,以便继续执行所述第一训练单元、所述第二训练单元、所述判断单元和所述模型参数更新单元,对所述分类模型继续进行训练。
根据本公开的再一方面,提出一种分类模型的训练装置,包括:
存储器;以及
耦接至所述存储器的处理器,所述处理器被配置为基于存储在所述存储器中的指令,执行前述任一个实施例的分类模型的训练方法。
根据本公开的又一方面,提出一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现前述任一个实施例的分类模型的训练方法的步骤。
附图说明
下面将对实施例或相关技术描述中所需要使用的附图作简单地介绍。根据下面参照附图的详细描述,可以更加清楚地理解本公开,
显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
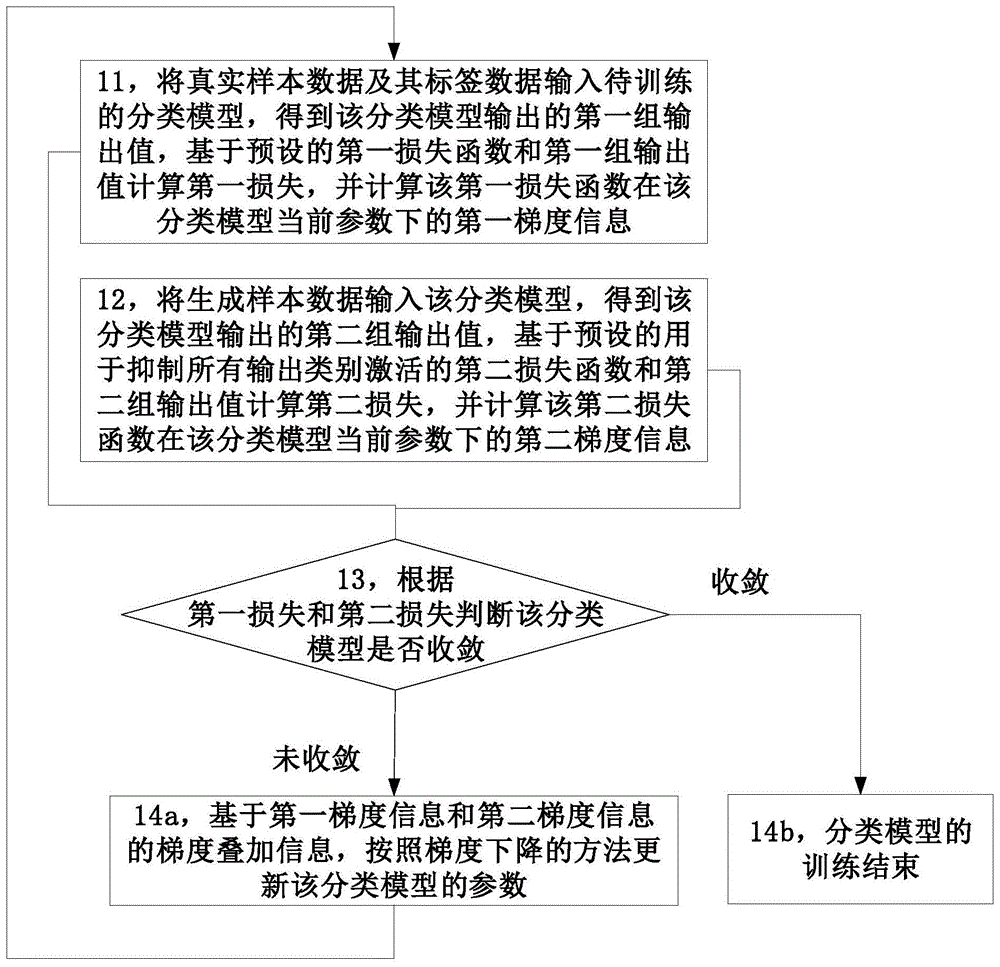
图1为本公开分类模型的训练方法一些实施例的流程示意图。
图2示出分类模型训练过程的信息流转示意图。
图3为本公开分类模型的训练装置一些实施例的结构示意图。
图4为本公开分类模型的训练装置一些实施例的结构示意图。
具体实施方式
下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述。
本公开的“第一”“第二”等描述,用来区分不同的对象,并不用来表示大小或时序等含义。例如,第一损失函数和第二损失函数表示两个损失函数。
本公开中的分类模型、生成模型等均为机器学习模型。本公开用开对分类模型进行训练,对分类模型具体为何种模型不做限制。训练用的真实样本数据及其标签数据为标记数据,训练用的生成样本数据为无标记数据,因此,本公开涉及一种半监督的分类方案。
图1为本公开分类模型的训练方法一些实施例的流程示意图。
如图1所示,该实施例的训练方法包括:
步骤11,将真实样本数据和该真实样本数据的标签数据输入待训练的分类模型,得到该分类模型输出的第一组输出值,基于预设的第一损失函数和第一组输出值计算第一损失,并计算该第一损失函数在该分类模型当前参数下的第一梯度信息。
其中,第一损失函数针对真实训练数据设置,例如为交叉熵损失函数、指数损失函数、铰链损失函数等。
此外,在定义好损失函数和模型参数的情况下,损失和梯度信息的具体计算可以参考现有技术。
步骤12,将生成样本数据输入该分类模型,得到该分类模型输出的第二组输出值,基于预设的用于抑制所有输出类别激活的第二损失函数和第二组输出值计算第二损失,并计算该第二损失函数在该分类模型当前参数下的第二梯度信息。
可理解的,步骤11和12的执行不分先后顺序。
生成样本数据相对于真实样本数据来说也称为“虚假样本数据”。在一些实施例中,训练用的生成样本数据可以通过生成模型生成,其中,该生成模型的特征层被配置为添加噪声,使得生成模型生成接近真实样本数据但又不会过于真实致使模型难以分辨的“虚假样本数据”,有利于提升训练数据的有效性和提升训练效果。
其中,第二损失函数根据该第二组输出值中每个输出类别上的输出值与数值小的预设值之间的差值信息确定。
在一些实施例中,第二损失函数的公式表示例如为:
其中,c表示输入输出类别的数量,i表示其中某个输出类别,
如果分类模型在输出类别i上的输出值
则,在二分类b下的第二损失lss,b可以表示为:
步骤13,根据该第一损失和该第二损失判断该分类模型是否收敛。
例如,将第一损失和第二损失叠加起来得到总损失,如果总损失的变化均足够小,则判定分类模型收敛。其中,总损失的变化根据迭代训练中相邻两次训练的总损失之间的差值确定。
步骤14a,在该分类模型未收敛的情况下,基于第一梯度信息和第二梯度信息的梯度叠加信息,按照梯度下降的方法更新该分类模型的参数,并对该分类模型继续进行训练,即继续从步骤11开始执行本方法。
其中,将第一梯度信息和第二梯度信息叠加起来得到梯度叠加信息。
其中,按照梯度下降的方法更新该分类模型的参数例如为:分类模型更新前的参数减去学习率与梯度叠加信息的乘积得到分类模型更新后的参数。
步骤14b,在该分类模型收敛的情况下,分类模型的训练结束。
此外,在一些应用中,利用收敛的分类模型可以对输入的图像数据进行分类。
上述实施例,单独训练分类模型,相对于同时训练相关的两个模型,模型的稳定性更好;并且基于生成样本数据设置用于抑制所有输出类别激活的损失函数,在真实类别的基础上不需要额外增加虚假类别,有利于降低训练的复杂度。此外,通过在特征层添加噪声的方法,在一定程度上避免生成模型生成过于真实的“虚假数据”,有利于提升训练数据的有效性和提升训练效果。
针对上述实施例描述的训练方法,图2示出分类模型训练过程的信息流转示意图。其中的箭头方向表示信息的流转方向。
在一些实施例中,分类模型为图像分类模型;真实样本数据为真实事物的图像数据,真实样本数据的标签数据为标注的真实事物的种类,第一组输出值为真实事物的图像数据在各个种类上的概率;生成样本数据为对真实事物的图像数据添加噪声得到的虚假事物的图像数据,第二组输出值为虚假事物的图像数据在各个种类上的概率。
下面以服饰图像的分类为例,具体说明本公开的方案。
模型训练阶段:
将真实的服饰图像和标注的服饰图像的种类输入待训练的图像分类模型,输出真实的服饰图像在各个种类上的概率(即第一组输出值),基于交叉熵损失函数和真实的服饰图像在各个种类上的概率计算第一损失,并计算交叉熵损失函数在图像分类模型当前参数下的第一梯度信息;
对真实的服饰图像添加噪声得到“虚假的”服饰图像,将“虚假的”服饰图像输入图像分类模型,输出“虚假的”服饰图像在各个种类上的概率(即第二组输出值),基于前述的用于抑制所有输出类别激活的第二损失函数lss,m和第二组输出值计算第二损失,并计算第二损失函数lss,m在图像分类模型当前参数下的第二梯度信息;
判断第一损失和第二损失叠加起来的总损失的变化是否足够小,以确定图像分类模型是否收敛,在图像分类模型未收敛的情况下,基于第一梯度信息和第二梯度信息的梯度叠加信息,按照梯度下降的方法更新图像分类模型的参数,并对图像分类模型继续进行训练,直至图像分类模型收敛。从而,得到能够对服饰图像进行分类的图像分类模型。
该图像分类模型是单独训练得到的,相对于同时训练相关的生成模型和分类模型,图像分类模型的稳定性更好;并且,在训练过程中,仅涉及真实图像的种类,没有额外增加的虚假图像种类,有利于降低训练的复杂度。
模型使用阶段:
将待分类的服饰图像输入上述训练得到的收敛的分类模型中,输出待分类的服饰图像在各个种类上的概率,其中,概率最大的种类被判定为该服饰图像的种类。
图3为本公开分类模型的训练装置一些实施例的结构示意图。
如图3所示,该实施例的训练装置30包括:
第一训练单元31,被配置为将真实样本数据和该真实样本数据的标签数据输入待训练的分类模型,得到该分类模型输出的第一组输出值,基于预设的第一损失函数和第一组输出值计算第一损失,并计算该第一损失函数在该分类模型当前参数下的第一梯度信息;
第二训练单元32,被配置为将生成样本数据输入该分类模型,得到该分类模型输出的第二组输出值,基于预设的用于抑制所有输出类别激活的第二损失函数和第二组输出值计算第二损失,并计算该第二损失函数在该分类模型当前参数下的第二梯度信息;
判断单元33,被配置为根据该第一损失和该第二损失判断该分类模型是否收敛;
模型参数更新单元34,被配置为在该分类模型未收敛的情况下,基于第一梯度信息和第二梯度信息的梯度叠加信息,按照梯度下降的方法更新该分类模型的参数,以便继续执行该第一训练单元、该第二训练单元、该判断单元和该模型参数更新单元,对该分类模型继续进行训练。
第二训练单元32涉及的第二损失函数根据第二组输出值中每个输出类别上的输出值与数值小的预设值之间的差值信息确定。例如,第二损失函数的公式表示为:
其中,c表示输入输出类别的数量,i表示其中某个输出类别,
第二训练单元32涉及的生成样本数据通过生成模型生成,其中,该生成模型的特征层被配置为添加噪声。
图4为本公开分类模型的训练装置一些实施例的结构示意图。
如图4所示,该实施例的训练装置40包括:
存储器41;以及耦接至该存储器的处理器42,该处理器42被配置为基于存储在该存储器中的指令,执行前述任一个实施例的分类模型的训练方法。
其中,存储器41例如可以包括系统存储器、固定非易失性存储介质等。系统存储器例如存储有操作系统、应用程序、引导装载程序(bootloader)以及其他程序等。
本领域内的技术人员应当明白,本公开的实施例可提供为方法、系统、或计算机程序产品。因此,本公开可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本公开可采用在一个或多个其中包含有计算机可用程序代码的计算机可用非瞬时性存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
以上所述仅为本公开的较佳实施例,并不用以限制本公开,凡在本公开的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!