针对神经网络算法在集成电路上实现性能的评估系统的制作方法
本发明涉及的是一种神经网络领域的技术,具体是一种针对神经网络算法在集成电路上实现时性能的评估系统,对卷积神经网络、残差神经网络等进行可靠的硬件运行性能进行评估。
背景技术:
随着神经网络性能的不断提升,网络的参数数量越来越多,计算量也变得越来越大。现阶段急需一种能够在进行大规模计算前预先评估算法在集成电路上执行时间的技术,从而减少设计周期,进一步提高资源利用率。
技术实现要素:
本发明针对现有技术存在的上述不足,提出一种针对神经网络在集成电路上实现时的性能评估系统,针对于神经网络的拓扑结构以及具体网络参数,通过硬件可调参数的配置,在多种数据流组织方式下,完成对该神经网络硬件实现性能的评估,包括各个层级的延时,硬件资源的使用,不同等级存储器的访问情况等。
本发明是通过以下技术方案实现的:
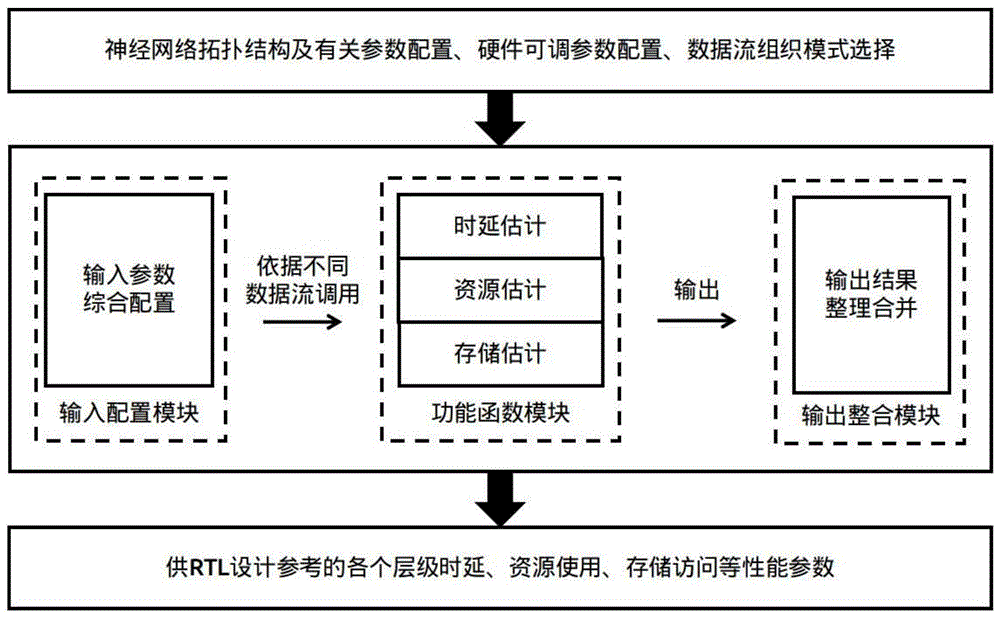
本发明涉及一种针对神经网络硬件性能的评估系统,包括:输入配置模块和功能函数模块,其中:输入配置模块中的数据流解析单元根据卷积神经网络循环展开的理论解析出待测神经网络算法的数据流组织方式,即每个卷积循环的卷积维度、循环分块和循环展开,输入配置模块中的硬件配置单元根据数据流组织方式设置对应的硬件框架参数配置,功能函数模块根据输入配置模块的输出进行时延估计、资源估计和存储估计并合并生成评估结果。
所述的功能函数模块包括:时延估计单元、资源估计单元和存储估计单元,分别针对硬件架构与数据流组织方式,本发明设计的评估系统对延时、资源使用、不同存储器访问次数进行评估。
所述的系统中进一步优选设有输出整合模块,该输出整合模块整理时延估计、资源估计和存储估计并通过交互方式选择性打印输出估计结果。
本发明涉及一种基于上述系统的神经网络硬件性能评估方法,通过配置待测神经网络的参数,通过输入配置模块进行数据流组织方式解析以及硬件框架参数配置,再通过功能函数模块对延时、资源使用、不同存储器访问次数进行评估。
技术效果
与现有技术相比,本发明可以为神经网络rtl级的设计提供精确的仿真参考数据。在不同的硬件存储资源下,采用不同的基于卷积循环展开所对应的数据流组织形式,做到不同数据的复用,对于已有硬件平台(如fpga)而言,可以最大化运算资源的使用,又同时最小化从片外读取数据的次数,极大地减少了时延;对于asic设计专用芯片而言,可以为之提供不同神经网络在集成电路上实现的性能和硬件参数配置的适用性指标,并还为之提供了精确的片上片下资源使用和芯片尺寸的重要参考。
附图说明
图1为本发明系统结构示意图;
图2、图3、图4为三类数据流组织形式示意图;
图中step表示优先计算的步骤,不同的step组合即表示了不同的循环展开次序;
图5为实施例中神经网络硬件架构示意图;
图6为实施例pearray示意图;
图7为实施例pe示意图;
图中的pe可以完成权重窗口尺寸内像素点的同步运算,即为第1层循环的展开;
图8为实施例数据流组织实现展开循环示意图;
图中的不同的channel表示第2层循环的展开,不同的kernel表示第4层循环的展开,不同的row表示第3层循环的展开。
具体实施方式
如图1所示,为本实施例涉及的一种针对神经网络硬件性能的评估系统,包括:输入配置模块、功能函数模块和输出整合模块。本实施例基于该系统,以vgg16为例进行硬件运行性能评估,具体包括以下步骤:
步骤一、配置待测神经网络参数,包括设置vgg16的网络层数、每层的尺寸与步长、是否有padding、是否池化、权重的尺寸与个数等。
步骤二、输入配置模块进行数据流组织方式解析以及硬件框架参数配置,根据循环展开理论结合硬件资源情况,合理地对卷积运算四层循环进行展开,并行计算所展开循环中对应的乘加运算,从而利用有限资源并行化运算,具体包括:
2.1)数据流解析单元根据卷积神经网络循环展开的理论解析出待测神经网络算法的数据流组织方式,即根据卷积循环维度与硬件设计变量表得到卷积神经网络的关键参数:
根据卷积运算对应的四层循环展开的伪代码:
for(no=0;no<nof;no++)→loop-4
for(y=0;y<noy;y++)→loop-3
for(x=0;x<nox;x++)→loop-3
for(ni=0;ni<nif;ni++)→loop-2
for(ky=0;ky<nky;ky++)→loop-1
for(kx=0;kx<nkx;kx++)→loop-1
pixell(no;x,y)+=pixell-1。(ni;s×x+kx,s×y+ky)×weightl-1(ni,no;kx,ky);
pixell(no;x,y)=pixell(no;x,y)+bias(no);
其中l表示当前运算的卷积层的层数,s表示滑动步长,weight表示权重,pixel表示输入特征图像素点,no表示输出特征通道计数,ni表示输入特征通道计数,kx表示卷积窗口内像素点的列计数,ky表示卷积窗口内像素点的行计数,x表示输入特征图内划窗的列计数,y表示输入特征图内划窗的行计数,bias表示输出特征图对应的偏置。其中的参数如表1所示:
表1
如表1所示:第1层循环是输入特征图在对应的权重窗口上遍历各个像素点,循环次数为权值窗口的尺寸;第2层循环是输入特征图遍历各个输入通道,循环次数为输入特征图的通道数;第3层循环是权重窗口在一个通道的输入特征图上划窗遍历所有像素点,循环次数为在一张特征图上划窗的次数;第4层循环是遍历所有输出特征图通道,循环次数为权重的个数(即输出特征图通道数)。
根据遍历各个输入特征图的输入通道的不同方式以及权重窗口在一个通道的输入特征图上划窗遍历所有像素点的不同方式,对应有三种基于循环展开的数据流组织形式,包括:如图2所示的第1层循环和第3层循环的展开,对应权值和卷积部分和的数据复用;如图3所示的第1层循环和第2层循环的展开,对应权值和卷积部分和的数据复用;如图4所示的第1层循环和第4层循环的展开,对应输入图像数值和卷积部分和的数据复用。
如图2所示,第一类数据流组织形式依次遍历输入特征图、输入通道、输出通道,对于卷积层的运算操作符合传统习惯,控制简单,并且片上内存大小适中,只需存储一张最大的输出特征图即可。
如图3所示,第二类数据流组织形式依次遍历输入通道、输入特征图、输出通道,由于优先遍历输入通道,因此片上所需的存储空间可以达到最小,但是时延相对最长。
如图4所示,第三类数据流组织形式依次遍历输出通道、输入特征图、输入通道,由于只需读取一次输入特征图,因此虽然可以做到时延最小化但耗费较大的片上存储。
2.2)硬件配置单元根据数据流组织方式设置对应的硬件框架参数配置
如图5所示,所述的硬件框架包括:作为片下部分的dram、片上部分以及用于数据传输的双倍速率同步动态随机存储器(ddr),其中:dram用于存放原始图像、权重和各层的中间数据,片上部分包括:用于组织输入数据的数据读入(feeder)模块、用于暂存权重数据的权重缓存模块、用于计算乘加的运算单元簇(pecluster)模块、用于暂存输出数据的输出缓存模块、池化处理模块、用于排列和组织输出特征图数据以写回dram的数据综合模块。
如图6所示,本实施例中所述的pecluster模块中进一步设有参数可调的运算单元阵列(pearray)作为子模块,每个运算单元阵列通过输入特征图的行(row)和卷积核(kernel)并联连接,该阵列在定制化的feeder模块与权重缓存模块的配合下实现了卷积运算的四层循环的展开。
如图7所示,本实施例以3*3为例的pe结构,可同时完成一个尺寸为3的卷积窗口的乘加操作,即可完成卷积运算第1层循环的展开,其他尺寸的卷积本发明也可以通过配置参数完成对pe结构的更新。
如图8所示,为图6中的硬件框架在图7中定制参数的pecluster模块情况下的数据流。
步骤三、基于步骤二确定的硬件架构与数据流组织方式,功能函数模块对延时、资源使用、不同存储器访问次数进行评估。
所述的延时估计包括:ttotal=tddr-rd-wei+max(tload-new-data,tpe)×nuntil-read-all-pixels×nrepeat-times+tpool+tddr-wr,其中:ttotal表示一层卷积运算的总体时延,tddr-rd-wei表示ddr读取权重数据的时延,tload-new-data表示ddr加载新的输入特征图数据的时延,tpe表示pe阵列中处理完feeder组织的一批数据的时延,tload-new-data与tpe的最大值决定了流水处理一批输入特征图数据的基本单位时延,nuntil-read-all-pixels表示直至读取所有输入通道的所有像素点的总次数,nrepeat-times表示需要读取整张特征图的重复次数,tpool表示池化运算的时延,tddr-wr表示ddr写回输出特征图的时延。
所述的存储估计包括:使用的dsp数量、存储器的存储用量以及寄存器文件大小,具体为:
①ndsp=numpe×ndsp-used-in-one-pe,其中:ndsp表示片上使用的dsp数量,numpe表示pe阵列中pe的总数,ndsp-used-in-one-pe表示一个pe使用的dsp数量。
②memdram=(datainitial-pic+dataweight+2×max(dataoutput-feature-map))×databits,其中:memdram表示片下动态随机存取存储器的存储大小,datainitial-pic表示初始待检测图像的数据量,dataweight表示所有权重的数据量,dataoutput-feature-map表示输出特征图的数据量,databits表示数据位数。
③memsram=(dataone-kernel+dataone-output-channel)×numkernels-in-one-compute×databits,其中:memsram表示片上静态随机存取存储器的存储大小,dataone-kernel表示一个权重的数据量,dataone-output-chanmel表示一个通道的输出特征图的数据量,numkernels-in-one-compute表示固定feeder中的输入数据,同批次进行计算的权值的个数,databits表示数据位数。
④memrf=(numfeeder+numcomparator+numcouector)×databits,其中:memrf表示片上寄存器文件的存储大小,numfeeder表示feeder使用的寄存器数量,numcomparator表示pooling模块中的比较器数量,numcouector表示collector模块使用的寄存器数量,databits表示数据位数。
所述的资源估计包括:存储器和寄存器文件的访问次数,具体为:
以下为在mode3数据流组织方式下,本系统对于vgg16神经网络估计得到的各层运算周期数,并根据不同的系统时钟频率,给出其相应的时延。数据具体是依据上述估计策略的指导下编写的对应估计函数中迭代计算得到的。
numbersofcyclesofeachlayerasfollows:
no.1conv:258912
no.2conv:1105728
no.3conv:549440
no.4conv:957632
no.5conv:534720
no.6conv:1018816
no.7conv:1018816
no.8conv:549344
no.9conv:1073376
no.10conv:1073376
no.11conv:371512
no.12conv:371512
no.13conv:371512
no.1fc:6422528
no.2fc:1048576
no.3fc:256063
total:16961863
latencyofdifferentsystemfrequencyasfollows:
100mhz:169.619ms
200mhz:84.809ms
500mhz:33.924ms
如上所示:不同深度的卷积层运算周期数不尽相同,且符合各卷积层尺寸与权重的数据量大小分布规律,全连接层占用了大量的运算周期数,这是由于它巨大的权重数据量造成的。该参数可以为rtl设计者是否选择该神经网络用于指定任务与该硬件架构实现其算法提供有效的指导,也为进一步优化和加速相关数据的传输与运算提供重要参考。
以下数据是本系统针对vgg16神经网络所估计的集成电路片上及片下硬件资源使用情况。具体数据是依据上述估计策略指导下而编写的对应估计函数迭代计算得到。
hardwareevaluationasfollows:
off-chipdram:289.533mbyte
on-chipsram:11.141mbyte
rf:54144byte
dsps:1344
如上所示:在实施例的硬件参数设定下,本系统估计使用了289.533mb的片下dram存储资源,11.141mb的片上sram存储资源和54144b的rf资源,dsp使用量为1344个。该参数可以为rtl设计者根据现有的硬件平台(fpga)资源使用率或者asic设计提供资源使用量的参考。
以下为针对vgg16神经网络在上述设定的硬件配置下,对于不同等级存储器的访问数据。具体数据是依据上述估计策略指导下而编写的对应估计函数迭代计算得到。
memoryvisitevaluationasfollows:
ddrreadtimes:9.216m
ddrwritetimes:0.560m
ddrtatolvisittimes:9.776m
ramreadtimes:8.686m
ramwritetimes:8.687m
ramtatolvisittimes:17.373m
rfreadtimes:1.133m
rfwritetimes:1.133m
rftatolvisittimes:2.267m
如上所示:对于不同存储器的读写访问次数和总次数如上,该数据为rtl设计者对于集成电路的能耗大小预估提供了重要参考指标之一。
上述具体实施可由本领域技术人员在不背离本发明原理和宗旨的前提下以不同的方式对其进行局部调整,本发明的保护范围以权利要求书为准且不由上述具体实施所限,在其范围内的各个实现方案均受本发明之约束。
- 还没有人留言评论。精彩留言会获得点赞!