一种基于生成式对抗网络的虚拟样本生成方法与流程
本发明涉及深度学习神经网络技术领域,具体涉及一种基于生成式对抗网络的虚拟样本生成方法。
背景技术:
由于数据本身性质、获取难易程度以及经济因素等条件导致数据容易出现分布不平衡现象。而样本不平衡会使得分类模型出现决策面偏移的现象,导致无法得到理想的分类结果。以svm分类器为例,在样本不均衡情况下的分类性能会随着不平衡率升高而下降。为解决样本不平衡问题,目前可以利用生成式对抗网络通过生成器与判别器的博弈,从而生成所需要的与原始样本分布非常近似的非人为干涉样本序列。但原始的gan存在训练不稳定、在不平衡问题上分类效果不佳等缺点。
技术实现要素:
本发明提供一种基于生成式对抗网络的虚拟样本生成方法,解决现有gan模型在训练上不稳定和不平衡问题分类效果不好的问题,能提高生成式对抗网络的稳定性和实用性。
为实现以上目的,本发明提供以下技术方案:
一种基于生成式对抗网络的虚拟样本生成方法,包括:
基于wgan-gp改进模型对生成器的输入样本进行svm分类预训练;
根据所述svm分类得到决策面的位置,并模拟生成位于所述决策面附近的少数类样本;
根据生成样本与所述决策面的几何距离,设置生成样本的位置约束,以控制样本生成范围;
根据所述位置约束建立pcgan模型,并进行基于所述pcgan模型的少数类样本扩充;
通过所述pcgan模型在svm决策面附近生成符合原始分布的生成样本。
优选的,还包括:
对生成样本进行数据筛选;
选择最好的生成数据重新训练svm分类,进而得到新的决策面。
优选的,所述对生成样本进行数据筛选包括:
使用全员筛选,对生成样本计算其与原始样本及近邻样本的欧式距离及余弦相似性,并判断是否满足设定条件,如果是,则选择扩充样本。
优选的,所述使用全员筛选包括:
对于每个
如果||xi-xj||<||xk-xj||,则进一步计算(xi-xj)和(xk-xj)余弦相似性
如果余弦相似性大于阈值c,则将xi纳入扩充数据集sexp;
其中,xi、xj、xk分别为生成样本、少数类样本、第k个最近邻样本,smin、sgen、sneighbor分别为少数类样本集、生成样本集、近邻样本集。
优选的,所述对生成样本进行数据筛选还包括:
使用基于danger集的筛选,以筛选位于所述danger集附近的符合样本分布的生成样本,其中,所述danger集包括近邻样本集中含有多数类的少数类样本。
优选的,所述使用基于danger集的筛选,包括:
对于
对于每个
如果||xi-xj||<||xk-xj||,则进一步计算(xi-xj)和(xk-xj)余弦相似性;
如果余弦相似性大于阈值c,则将xi纳入扩充数据集sexp;
其中,sdanger为最近邻样本集中含有多数类的少数类样本集合、si:m-nn为最近邻样本集、smaj为多数类样本集。
优选的,所述对生成样本进行数据筛选还包括:
通过核方法将样本映射到高维可分空间中,根据生成样本到超平面间的距离,当距离小于所设定的阈值时,将生成样本纳入到扩充样本集中,其中,映射函数使用rbf核。
优选的,所述设置生成样本的位置约束,包括:
设置smoothloss的限制条件,所述限制条件为:
其中,x为样本的生成范围,y为smooth分段函数的分界值。
优选的,所述根据所述位置约束建立pcgan模型,包括:
生成器的损失函数:
判别器的损失函数:
其中,e为期望、c为类别标签、x为原始样本、
优选的,所述进行基于所述pcgan模型的少数类样本扩充,包括:
(1)初始化设计的超参数,主要包括梯度惩罚系数λ1=10、决策面约束系数λ2=5、每轮对抗优化中判别器训练次数ncritic=3、每轮对抗优化中生成器器训练次数ngen=1、训练一批的数据个数m=10、adam优化器超参数α=0.0001,β1=0.9,β2=0.99、初始化判别器参数
(2)对于判别器训练中每批次的每个样本,先从真实样本集采样得到x~pdata以及类别标签c,然后从噪声分布中采样得到z~p(z),并将噪声映射到生成样本空间,即
(3)判别器损失函数的表达式为
(4)重复执行步骤(2)~步骤(3)并且当执行该二重循环结束时停止训练,循环共ncritic×m次;
(5)对于生成器训练中每批次的每个样本,先从噪声分布中采样得到z~p(z),接着计算数据与决策面的几何距离
(6)根据smoothl1loss理论计算生成器损失函数,它的表达式为
(7)重复执行步骤(5)~步骤(6)并且当执行该二重循环结束时停止训练,循环共ngen×m次;
(7)重复执行步骤(2)~步骤(7)并且当生成网络的生成数据满足预设的数据要求时停止训练。
本发明提供一种基于生成式对抗网络的虚拟样本生成方法,通过在wgan-gp模型添加了基于svm理论的样本与决策面距离限制,从而对生成样本进行位置约束,然后在pcgan生成样本后进行数据筛选,经过pcgan模型生成样本及筛选之后,选取最好的生成样本重新训练svm得到新的决策面。提升了生成式对抗网络模型处理离散型数据的稳定性,在不平衡问题分类上有良好的效果。
附图说明
为了更清楚地说明本发明的具体实施例,下面将对实施例中所需要使用的附图作简单地介绍。
图1是本发明提供的一种基于生成式对抗网络的虚拟样本生成方法的流程图;
图2是本发明实施例中基于对抗式生成网络的少数类样本扩充流程示意图;
图3是本发明实施例中上述技术方案相比于其他方法在cmc、pima数据集上的性能评价结果图;
图4是本发明实施例中上述技术方案相比于其他方法在robot、satlog数据集上的性能评价结果图;
图5是本发明实施例中上述技术方案相比于其他方法在haberman、semeion数据集上的性能评价结果图;
图6是本发明实施例中上述技术方案相比于其他方法在yeast、yeast_2数据集上的性能评价结果图。
具体实施方式
为了使本技术领域的人员更好地理解本发明实施例的方案,下面结合附图和实施方式对本发明实施例作进一步的详细说明。
针对当前原始gan网络存在训练不稳定、在不平衡问题上分类效果不好的缺点,本发明提供一种基于生成式对抗网络的虚拟样本生成方法,通过在wgan-gp模型添加了基于svm理论的样本与决策面距离限制,从而对生成样本进行位置约束,然后在pcgan生成样本后进行数据筛选,经过pcgan模型生成样本及筛选之后,选取最好的生成样本重新训练svm得到新的决策面。解决现有gan模型在训练上不稳定和不平衡问题分类效果不好的问题,能提生成式对抗网络的实用性。
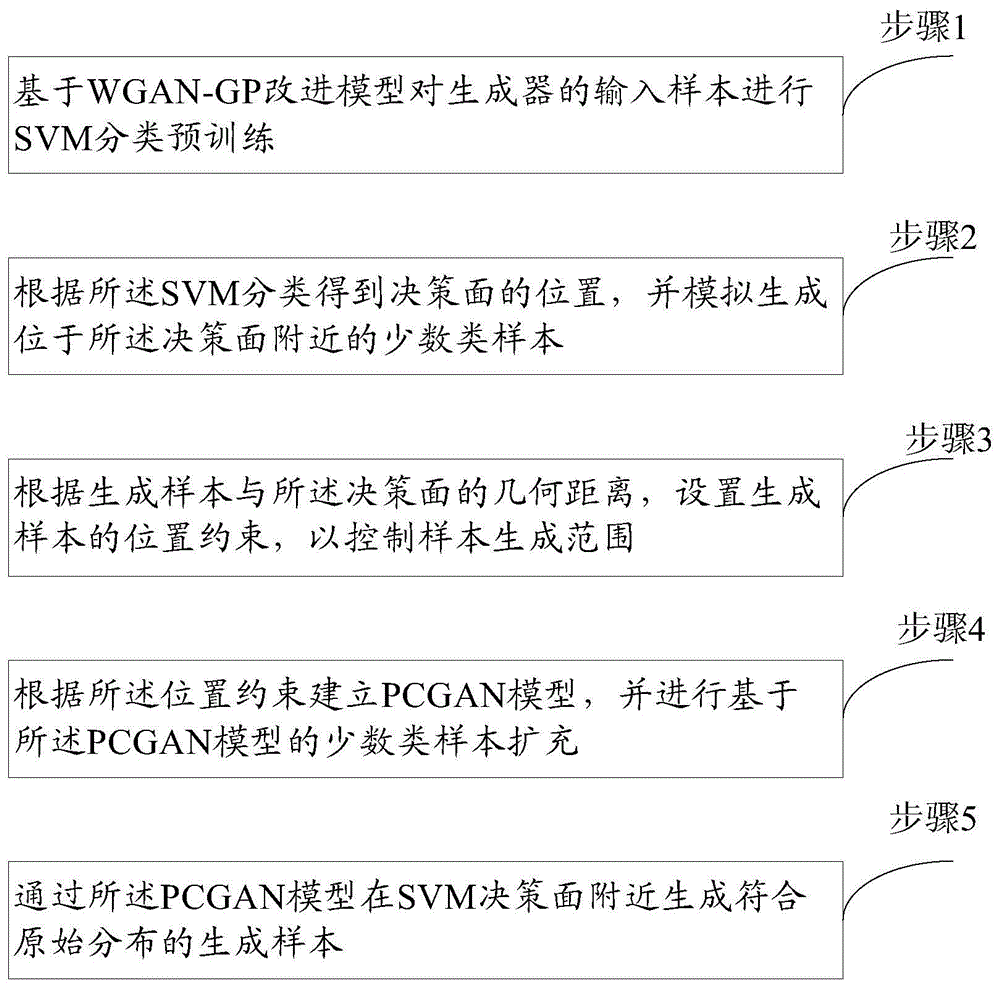
如图1所示,一种基于生成式对抗网络的虚拟样本生成方法,包括:
步骤1:基于wgan-gp改进模型对生成器的输入样本进行svm分类预训练;
步骤2:根据所述svm分类得到决策面的位置,并模拟生成位于所述决策面附近的少数类样本;
步骤3:根据生成样本与所述决策面的几何距离,设置生成样本的位置约束,以控制样本生成范围;
步骤4:根据所述位置约束建立pcgan模型,并进行基于所述pcgan模型的少数类样本扩充;
步骤5:通过所述pcgan模型在svm决策面附近生成符合原始分布的生成样本。
进一步,该方法还包括:
步骤6:对生成样本进行数据筛选;
步骤7:选择最好的生成数据重新训练svm分类,进而得到新的决策面。
具体地,在第一方面,基于wgan-gp的改进pcgan的建立方法包括如下步骤:
步骤s1:在生成部分预训练svm,得到决策面的位置。
svm理论中只有位于决策面附近的点对决策面的变化存在影响,因此本发明的主要目标是通过生成式对抗网络模拟生成位于决策面附近的少数类样本。
步骤s2:在生成器训练过程中,衡量生成样本与决策面的几何距离;
步骤s3:添加了smoothloss的限制条件,从而控制样本生成范围;
其中,smoothloss限制条件表述如下:
其中,x为样本的生成范围,y为smooth分段函数的分界值。
进一步地,所述的pcgan的结构,目标表述如下:
其中,生成器的损失函数表述如下:
判别器的损失函数:
其中,e为期望、c为类别标签、x为原始样本、
在第二方面,提出的三种样本生成后的筛选方法有,方法1:对于生成样本计算其与原始样本及近邻样本的欧式距离及余弦相似性,若满足特定条件,则选择扩充样本。方法2:筛选位于“danger集”附近的符合样本分布的生成样本。其中,“danger集”包括近邻样本集中含有多数类的少数类样本。方法3:本发明通过核方法将样本映射到高维可分空间中,根据生成样本到超平面间的距离,当距离小于所设定的阈值时,将生成样本纳入到扩充样本集中。
具体地,所述对生成样本进行数据筛选包括:使用全员筛选,对生成样本计算其与原始样本及近邻样本的欧式距离及余弦相似性,并判断是否满足设定条件,如果是,则选择扩充样本。
进一步,所述使用全员筛选包括:
对于每个
所述对生成样本进行数据筛选还包括:使用基于danger集的筛选,以筛选位于所述danger集附近的符合样本分布的生成样本,其中,所述danger集包括近邻样本集中含有多数类的少数类样本。
所述使用基于danger集的筛选,包括:对于
所述对生成样本进行数据筛选还包括:通过核方法将样本映射到高维可分空间中,根据生成样本到超平面间的距离,当距离小于所设定的阈值时,将生成样本纳入到扩充样本集中,其中,映射函数使用rbf核,样本筛选方法以欧氏距离和余弦相似度来衡量生成样本与真实样本之间的相似度。
需要说明的是,上述样本筛选实施例中虽然将各个步骤按照上述先后次序的方式进行了描述,但是本领域技术人员可以理解,为了实现本实施例的效果,不同的步骤之间不必按照这样的次序执行,其可以同时(并行)执行或以颠倒的次序执行,这些简单的变化都在本发明的保护范围之内。
进一步,所述设置生成样本的位置约束,包括:
设置smoothloss的限制条件,所述限制条件为:
其中,x为样本的生成范围,y为smooth分段函数的分界值。
所述根据所述位置约束建立pcgan模型,包括:
生成器的损失函数:
判别器的损失函数:
其中,e为期望、c为类别标签、x为原始样本、
在一实施例中,基于对抗式生成网络的少数类样本扩充流程可以包括如下步骤:
(1)初始化设计的超参数,主要包括梯度惩罚系数λ1=10、决策面约束系数λ2=5、每轮对抗优化中判别器训练次数ncritic=3、每轮对抗优化中生成器器训练次数ngen=1、训练一批的数据个数m=10、adam优化器超参数α=0.0001,β1=0.9,β2=0.99、初始化判别器参数
(2)对于判别器训练中每批次的每个样本,先从真实样本集采样得到x~pdata以及类别标签c,然后从噪声分布中采样得到z~p(z),并将噪声映射到生成样本空间,即
(3)判别器损失函数的表达式为
(4)重复执行步骤(2)~步骤(3)并且当执行该二重循环结束时停止训练。循环共ncritic×m次。
(5)对于生成器训练中每批次的每个样本,先从噪声分布中采样得到z~p(z),接着计算数据与决策面的几何距离
(6)根据smoothl1loss理论计算生成器损失函数,它的表达式为
(7)重复执行步骤(5)~步骤(6)并且当执行该二重循环结束时停止训练。循环共ngen×m次。
(7)重复执行步骤(2)~步骤(7)并且当生成网络的生成数据满足预设的数据要求时停止训练。
在一实施例中,对上述样本生成流程进行具体说明。
实施例中目标数据集采用uci数据库中的部分不平衡数据集,同时按照8:2的比例随机将该目标数据集划分为训练集和测试集,实验过程中每一个数据均是通过10次实验结果取平均数而得到的。其中使用f1-score、g-mean作为评价标准。对比算法包括:传统svm算法、带有核(rbf)的svm算法、smote算法及本实施例中提出的技术方案。
参阅附图3,图3示例地示出了本实施例中上述技术方案相比于其他方法在cmc和pima数据集上的性能评价结果。
具体地,在cmc数据集上,本实施例中提出的pcgan所生成的数据对分割面的平移起到推动作用,让分类效果提升了12.5%(与rbfsvm相比);在pima数据集上,本实施例中提出的pcgan及筛选方法,是以svm分割面修正为目标建立的模型,所生成的样本为pcgan模拟原始样本的分布,而不是简单的聚类后线性插值,对于此类数据的处理表现得更为合理,因此相聚于rbfsvm提升了5.2%。
参阅附图4,图4示例地示出了本实施例中上述技术方案相比于其他方法在robot和stalog数据集上的性能评价结果。
具体地,在robot数据集上,本实施例中提出的pcgan所生成的数据在此数据集上对于分割面的变化推动较小,结果略有提升,为0.7%;在stalog数据集上,本实施例与rbfsvm分类效果相近,但本方法为组内最佳。
参阅附图5,图5示例地示出了本实施例中上述技术方案相比于其他方法在haberman和semeion数据集上的性能评价结果。
具体地,在haberman数据集上,本实施例中提出的pcgan能较好的模拟数据分布,使得分类效果有了质的提升,达到16.3%;在semeion数据集上,本实施例表现稳定,与rbfsvm效果相当。
参阅附图6,图6示例地示出了本实施例中上述技术方案相比于其他方法在yeast和yeast_2数据集上的性能评价结果。
具体地,在yeast和yeast_2数据集上,本实施例中提出的pcgan和筛选方法生成样本过于集中,样本多样性不足,因此提升有限。
通过上述样本生成流程在8个uci数据集上进行实验来验证pcgan方法的性能,并发现其在绝大多数的数据集上的f1-score和g-mean表现都很突出,共14/16个指标达到第一,效果优于传统svm算法、带有核(rbf)的svm算法和smote算法。
可见,本发明提供一种基于生成式对抗网络的虚拟样本生成方法,通过在wgan-gp模型添加了基于svm理论的样本与决策面距离限制,从而对生成样本进行位置约束,然后在pcgan生成样本后,提出了三种基于欧式距离、余弦相似性的筛选方法。实验表明,所构建的少数类样本扩充流程提升了生成式对抗网络模型处理离散型数据的稳定性,在不平衡问题分类上有良好的效果。
以上依据图示所示的实施例详细说明了本发明的构造、特征及作用效果,以上所述仅为本发明的较佳实施例,但本发明不以图面所示限定实施范围,凡是依照本发明的构想所作的改变,或修改为等同变化的等效实施例,仍未超出说明书与图示所涵盖的精神时,均应在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!