基于函数依赖的批量交通视频数据结构及其挖掘方法与流程
本发明涉及一种数据挖掘方法,尤其是一种基于函数依赖的批量交通视频数据挖掘方法。
背景技术:
随着计算机的迅速发展和互联网的进一步普及,数据存储容量迅速增长。数据存储技术也同样迅速发展,数据存储容量和读写速度都有了巨大的提高。数据仓库技术也同样取得了长足的进步。然而,生成的海量数据远远超出了人们的处理和掌握能力。处理这些数据的能力以及信息组织形式的多样化使得信息处理变得更加困难。因此,利用现有的信息处理工具很难从这些数据中提取知识。智能交通系统(its)在数据通信、自动控制和计算技术方面有着显著的进步。此外,自20世纪80年代以来,交通数据的研究和应用依赖于智能交通系统的快速发展。最近,美国、日本和欧洲在智能交通系统的发展方面一直处于世界领先地位。
随着视频监控系统的大规模部署,城市道路被摄像头监控,每天产生大量的交通监控视频数据。通过对视频数据的分析,可以构建多种智能服务,如感兴趣的人员识别、交通监控和事故检测等。视频元数据是构建智能服务的重要基础。这些元数据可以通过结构分析方法从交通数据的视频监控中提取出来。视频结构分析方法依赖于实际场景中的视频分析算法。虽然这种方法不够精确,但很容易生成大量不正确的视频元数据。同时,独立的基于视频的结构分析方法无法有效地处理大量视频监控数据。本文将该方法应用于实际交通监控视频的实验结果表明,该方法修正了函数依赖性,提高了从交通视频数据中提取元数据的准确性。该方法还大大提高了处理大量视频监控数据的效率。
技术实现要素:
1、本发明的目的
本发明为了有效解决现有技术的产生大量视频监控数据冗余的问题,而提出了一种基于函数依赖的批量交通视频数据挖掘方法。
2、本发明所采用的技术方案
本发明提出了一种基于函数依赖的批量交通视频数据结构,设r(u)是u上的关系,x,y∈u,且
本发明提出了一种基于函数依赖的批量交通视频数据挖掘方法,具体为已知以下情况:
(a)关系表r(u),关系表i的输入参数集,输出参数集o;
(b)输入参数x#;
(c)参数y;
假设已知函数check-bd(x,y,c),用于确定bd{x#}∪c→y上的关系r(u),使用权利要求1所述的数据结构,如果满足,则函数返回值true,即数据挖掘成功。
更进一步,步骤一、在已知条件下,初始化属性集合、结果子集和迭代层级
输入:上述条件(a),(b),(c);
输出:(i-{x#})子集bdset,满足一下条件:
如果c∈bdset,那么bd{x#}∪c→y,输出的格式为("c","x#","y");
步骤二、确定子集上的依赖关系
如果bd{x#}∪c→y为真,那么c'∈bdset('cc)就意味着根据数据结构,bdset包含x#和y上的r(u),它们都是彼此依赖的,但没有输出;
步骤三、搜索空间修剪和子集合并
添加到下一级别的集合中,第二层有s={ab},k={bc},则得到的结果为{abc},因为|ab|=|bc|=|abc|-1,所以{abc}属于nextlevelset元素;如果s=k={ab},或s={ab},k={cd},则结果为{ab}或{abcd},因此,当|{ab}|=2,|{abcd}|=4时,它不属于子集的下一层;
程序行对搜索空间进行删减,假设它是第一层,在{x}∪d→y中可以找到满足批相关,然后包含d的所有子集将被修剪;
步骤四、层次集合判断和迭代的退出
算法行从levelset处删除d,d不再出现在任何nextlevelset;子集搜索算法不再执行搜索空间。
与现有技术相比,本发明的有益效果是:
1)提高了分类器的性能。在应用了本算法后,shnb、nb和hnb在实验数据集中都优于其他算法,证明本方法提高了算法的鲁棒性。
2)能够处理好带有噪点的数据,兼容性好。算法时间和空间性能优于现有算法。
附图说明
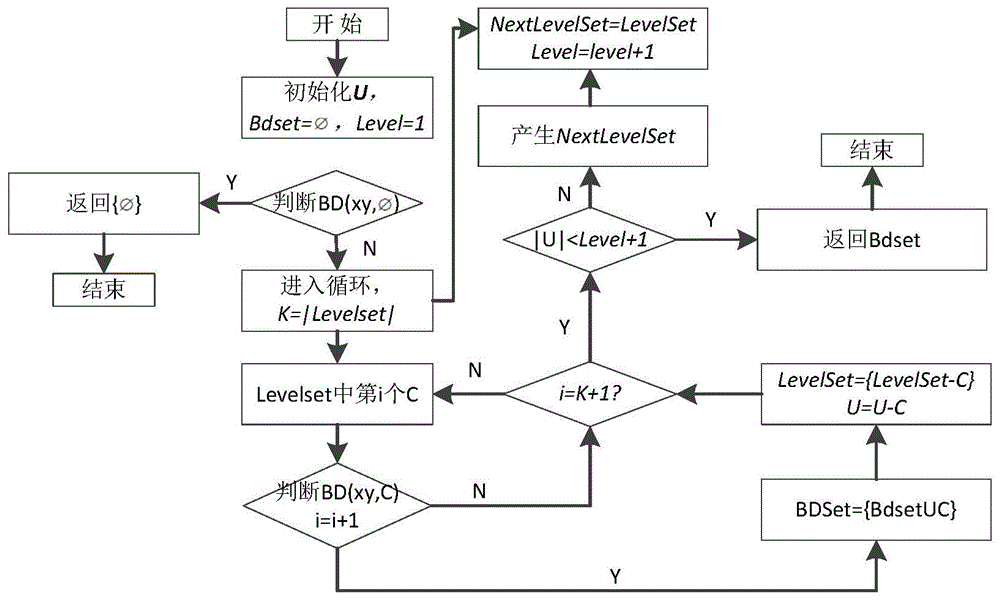
图1是本发明的算法流程图;
图2是本发明的伪代码描述。
具体实施方式
实施例
引理1:设r(u)是u上的关系,x,y∈u,且
证明:在等价类的r(u)|={bd{x}∪c1→y}上,使πc1,πc1c2是r(u)上的属性集c1和(c1∪c2),那么,在[t]c1|={bdx→y}上有对应的[t]c1πc1.因为,对于任一个[t]c1,如果存在
引理1表明,如果y在条件c1下依赖于x批次,那么就不需要检测可以获得的数据库。条件c1∪c2,y下的批次取决于x。
假设已知以下情况:
(a)关系表r(u),关系表i的输入参数集,输出参数集o;
(b)输入参数x#;
(c)参数y。
假设已知函数check-bd(x,y,c)。它用于确定bd{x#}∪c→y上的关系r(u)。如果满足,则函数返回值true。算法的详细过程如下:
输入:上述条件(a),(b),(c)
输出:(i-{x#})子集bdset,满足一下条件:
(a')如果c∈bdset,那么bd{x#}∪c→y,输出的格式为("c","x#","y")。
(b')如果bd{x#}∪c→y为真,那么c'∈bdset('cc)就意味着根据引论1,bdset包含x#和y上的r(u),它们都是彼此依赖的,但没有输出。
它将添加到下一级别的集合中。例如:第二层有s={ab},k={bc},则得到的结果为{abc},因为|ab|=|bc|=|abc|-1,所以{abc}属于nextlevelset元素。但是,如果s=k={ab},或s={ab},k={cd},则结果为{ab}或{abcd},因此,当|{ab}|=2,|{abcd}|=4时,它不属于子集的下一层。算法流程图如图1所示。
程序行对搜索空间进行删减,假设它是图2中的第一层,在{x}∪d→y中可以找到满足批相关,然后包含d的所有子集将被修剪。算法行从levelset处删除d,d不再出现在任何nextlevelset。子集搜索算法不再是执行搜索空间以下的算法。算法的伪代码如图2所示。
为了评估该算法的性能,本研究选择了oracle数据库进行了九个数据集实验。比较了hnb和shnb的结果。选择低分辨率和高分辨率的数据集来验证结果。表1概述了所选数据集的详细信息。首先,在数据集的预处理中,无监督方法使用weka过滤器来去除不相关的属性数据集。其次,如果存在数据缺失,则无监督方法使用weka来替换缺失值过滤器来处理数据集并填充缺失数据。最后,在无监督滤波器中使用weka进行离散化。
表1数据集的详细信息*
*一些数据来自uci机器学习库
分类精度通常用来衡量分类器的性能。然而,在某些情况下,单一使用分类精度来评估分类器的性能是不全面的。例如,当一个数据样本类,如二进制分类问题中,有一个样本类型占总样本的99%时,分配给该类的所有样本都能获得99%的分类精度。很明显,分类并不理想。然而,这些数据在现实世界中并不少见,比如信用卡欺诈、罕见疾病诊断等。
此外,类似于贝叶斯分类器,这种分类模型可以预测某些类型的指定样本的概率。这种分类准确性的能力被忽略了。同一个样本将分配给同一个类。当分类精度的概率分布不存在差异时,两个分类器分别得到0.51和0.99。然而,他们显然没有同样的性能。最后,贝叶斯分类器可以获得不同类别样本的排序信息。这些信息在许多情况下都很有用,例如市场分析。它不仅关系到客户将购买什么商品,还关系到客户购物的可能性,这表现了使用精确性无法衡量的能力。
- 还没有人留言评论。精彩留言会获得点赞!