确定异常行为的方法、装置和存储介质与流程
本公开涉及网络安全领域,尤其涉及一种确定异常行为的方法、装置和存储介质。
背景技术:
在相关技术中,随着互联网技术的不断发展和广泛应用,人们能够通过网络便捷、灵活地获取和发布各种信息。互联网在带来便利的同时,也因为本身具有的开放和分散等特征,容易受到各种攻击,给用户带来不便,甚至造成经济损失,因此,网络安全越来越受到人们的重视。对于互联网受到的各种攻击,可以通过异常行为模式挖掘来分析有风险的用户具有的异常行为模式,从而能够识别出有风险的用户,以提高网络的安全度,避免给用户带来损失,识别异常行为模式的准确程度决定了网络的安全度。
技术实现要素:
为克服相关技术中存在的问题,本公开提供一种确定异常行为的方法、装置和存储介质。
根据本公开实施例的第一方面,提供一种确定异常行为的方法,所述方法包括:
根据异常样本用户对应的第一行为序列和预设的频繁路径挖掘算法,在所述第一行为序列中确定异常的第二行为序列,所述第一行为序列包括:操作信息和所述操作信息对应的操作时间信息;
获取所述第二行为序列中,在预设时间段内目标操作信息出现的目标次数,所述目标操作信息为按照预设规则在所述第二行为序列中选择的一种操作信息;
根据所述目标操作信息和所述目标次数,确定与所述第二行为序列匹配的异常样本用户的第一用户数量,和与所述第二行为序列匹配的正常样本用户的第二用户数量;
若所述第一用户数量与所述第二用户数量的比值大于或等于预设的比例阈值,确定所述第二行为序列为异常行为。
可选地,所述根据所述目标操作信息和所述目标次数,确定与所述第二行为序列匹配的异常样本用户的第一用户数量,和与所述第二行为序列匹配的正常样本用户的第二用户数量,包括:
根据所述目标操作信息和所述目标次数,确定样本用户集中与所述第二行为序列匹配的至少一个目标样本用户;
确定所述至少一个目标样本用户包括的异常样本用户的所述第一用户数量,和正常样本用户的所述第二用户数量。
可选地,所述根据所述目标操作信息和所述目标次数,确定样本用户集中与所述第二行为序列匹配的至少一个目标样本用户,包括:
若所述第二行为序列为所述样本用户集中任一样本用户对应的第三行为序列的子序列,且所述第三行为序列中,在所述预设时间段内所述目标操作信息出现的次数与所述目标次数满足第一预设条件,确定所述任一样本用户为所述目标样本用户;
所述第一预设条件为:在所述预设时间段内所述目标操作信息出现的次数大于或等于所述目标次数;或,在所述预设时间段内所述目标操作信息出现的次数与所述目标次数的比值大于或等于第一阈值。
可选地,所述方法还包括:
在获取到目标用户对应的目标行为序列后,若所述第二行为序列为所述目标行为序列的子序列,且所述目标行为序列中,在所述预设时间段内所述目标操作信息出现的次数与所述目标次数满足第二预设条件,确定所述目标用户为异常用户;
所述第二预设条件为:在所述预设时间段内所述目标操作信息出现的次数大于或等于所述目标次数;或,在所述预设时间段内所述目标操作信息出现的次数与所述目标次数的比值大于或等于第二阈值。
根据本公开实施例的第二方面,提供一种确定异常行为的装置,所述装置包括:
第一确定模块,被配置为根据异常样本用户对应的第一行为序列和预设的频繁路径挖掘算法,在所述第一行为序列中确定异常的第二行为序列,所述第一行为序列包括:操作信息和所述操作信息对应的操作时间信息;
获取模块,被配置为获取所述第二行为序列中,在预设时间段内目标操作信息出现的目标次数,所述目标操作信息为按照预设规则在所述第二行为序列中选择的一种操作信息;
第二确定模块,被配置为根据所述目标操作信息和所述目标次数,确定与所述第二行为序列匹配的异常样本用户的第一用户数量,和与所述第二行为序列匹配的正常样本用户的第二用户数量;
判断模块,被配置为若所述第一用户数量与所述第二用户数量的比值大于或等于预设的比例阈值,确定所述第二行为序列为异常行为。
可选地,所述第二确定模块包括:
第一确定子模块,被配置为根据所述目标操作信息和所述目标次数,确定样本用户集中与所述第二行为序列匹配的至少一个目标样本用户;
第二确定子模块,被配置为确定所述至少一个目标样本用户包括的异常样本用户的所述第一用户数量,和正常样本用户的所述第二用户数量。
可选地,所述第一确定子模块被配置为若所述第二行为序列为所述样本用户集中任一样本用户对应的第三行为序列的子序列,且所述第三行为序列中,在所述预设时间段内所述目标操作信息出现的次数与所述目标次数满足第一预设条件,确定所述任一样本用户为所述目标样本用户;
所述第一预设条件为:在所述预设时间段内所述目标操作信息出现的次数大于或等于所述目标次数;或,在所述预设时间段内所述目标操作信息出现的次数与所述目标次数的比值大于或等于第一阈值。
可选地,所述装置还包括:
第三确定模块,被配置为在获取到目标用户对应的目标行为序列后,若所述第二行为序列为所述目标行为序列的子序列,且所述目标行为序列中,在所述预设时间段内所述目标操作信息出现的次数与所述目标次数满足第二预设条件,确定所述目标用户为异常用户;
所述第二预设条件为:在所述预设时间段内所述目标操作信息出现的次数大于或等于所述目标次数;或,在所述预设时间段内所述目标操作信息出现的次数与所述目标次数的比值大于或等于第二阈值。
根据本公开实施例的第三方面,提供一种确定异常行为的装置,所述装置包括:
处理器;
用于存储处理器可执行指令的存储器;
其中,所述处理器被配置为:
根据异常样本用户对应的第一行为序列和预设的频繁路径挖掘算法,在所述第一行为序列中确定异常的第二行为序列,所述第一行为序列包括:操作信息和所述操作信息对应的操作时间信息;
获取所述第二行为序列中,在预设时间段内目标操作信息出现的目标次数,所述目标操作信息为按照预设规则在所述第二行为序列中选择的一种操作信息;
根据所述目标操作信息和所述目标次数,确定与所述第二行为序列匹配的异常样本用户的第一用户数量,和与所述第二行为序列匹配的正常样本用户的第二用户数量;
若所述第一用户数量与所述第二用户数量的比值大于或等于预设的比例阈值,确定所述第二行为序列为异常行为。
根据本公开实施例的第四方面,提供一种计算机可读存储介质,其上存储有计算机程序指令,该程序指令被处理器执行时实现本公开第一方面所提供的确定异常行为的方法的步骤。
本公开的实施例提供的技术方案可以包括以下有益效果:
首先根据异常样本用户对应的第一行为序列和预设的频繁路径挖掘算法,在第一行为序列中确定异常的第二行为序列,其中,第一行为序列包括:操作信息和操作信息对应的操作时间信息,再获取第二行为序列中,在预设时间段内目标操作信息出现的目标次数,之后根据目标操作信息和目标次数,确定与第二行为序列匹配的异常样本用户的第一用户数量,和与第二行为序列匹配的正常样本用户的第二用户数量,若第一用户数量与第二用户数量的比值大于或等于预设的比例阈值,确定第二行为序列为异常行为。本公开通过结合用户行为的发生顺序和在预设时间段内的出现次数来确定用户行为是否异常,能够提高异常用户检测的准确度,有效地避免对正常用户的误判。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本公开的实施例,并与说明书一起用于解释本公开的原理。
图1是根据一示例性实施例示出的一种确定异常行为的方法的流程图。
图2是图1所示实施例示出的一种步骤103的流程图。
图3是根据一示例性实施例示出的另一种确定异常行为的方法的流程图。
图4是根据一示例性实施例示出的一种确定异常行为的装置的框图。
图5是图4所示实施例示出的一种第二确定模块的框图。
图6是根据一示例性实施例示出的另一种确定异常行为的装置的框图。
图7是根据一示例性实施例示出的一种确定异常行为的装置的框图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本公开相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本公开的一些方面相一致的装置和方法的例子。
在介绍本公开提供的确定异常行为的方法、装置和存储介质之前,首先对本公开各个实施例所涉及应用场景进行介绍。该应用场景可以包括:服务器,服务器能够为多种服务平台或者应用程序(英文:application,简称:app)提供数据服务,用户可以通过服务平台或者应用程序访问服务器。其中,服务器可以是本地服务器,也可以是云端服务器。
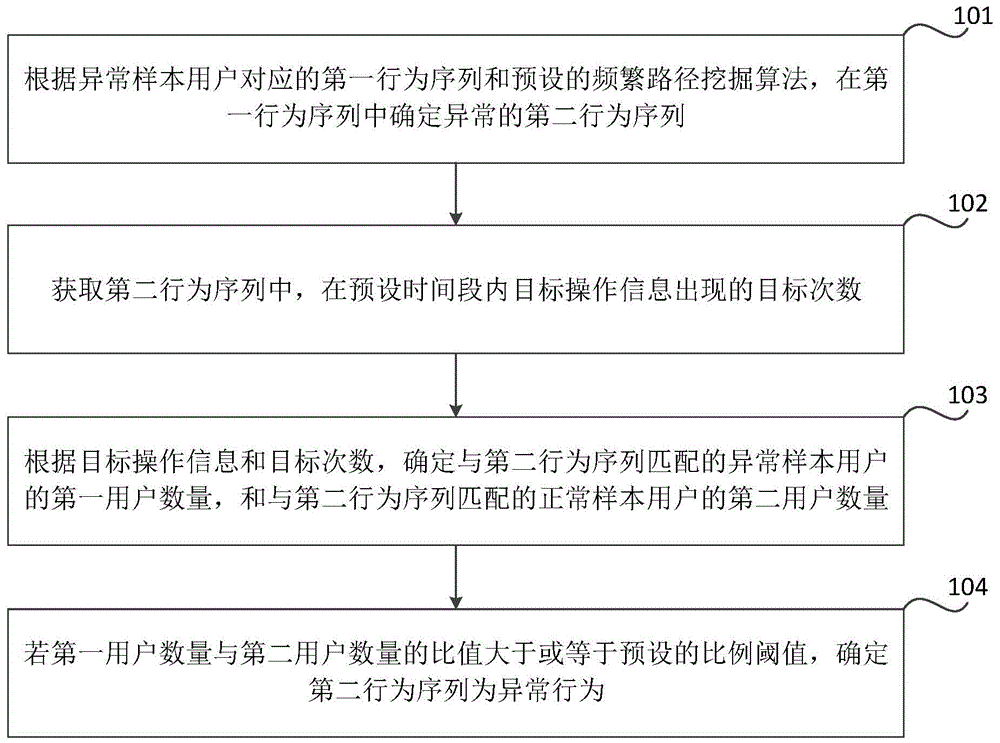
图1是根据一示例性实施例示出的一种确定异常行为的方法的流程图,如图1所示,该方法包括以下步骤:
在步骤101中,根据异常样本用户对应的第一行为序列和预设的频繁路径挖掘算法,在第一行为序列中确定异常的第二行为序列,第一行为序列包括:操作信息和操作信息对应的操作时间信息。
举例来说,可以从服务器上的数据库中获取预先存储在服务器上的异常样本用户以及异常样本用户对应的第一行为序列。每个异常样本用户可以包括账户数据(例如可以是用户名或用户识别码),第一行为序列可以包括操作信息(操作信息可以是用户执行的各种操作,例如登录、退出、更改密码等操作)和操作信息对应的操作时间信息,例如,异常样本用户1按时间先后顺序t1、t2、t3分别进行了操作α、β、γ,则异常样本用户1对应的第一行为序列为[α(t1),β(t2),γ(t3)]。之后按照预设的频繁路径挖掘算法确定第一行为序列中的异常的第二行为序列,频繁路径挖掘算法可以找出异常样本用户对应的第一行为序列共有的多个子序列,即所要确定的第二行为序列。
在步骤102中,获取第二行为序列中,在预设时间段内目标操作信息出现的目标次数,目标操作信息为按照预设规则在第二行为序列中选择的一种操作信息。
示例的,确定第二行为序列后,再获取第二行为序列中,在预设时间段内目标操作信息出现的目标次数,目标操作信息可以是第二行为序列中包含的所有操作信息中的任一种操作信息。选择目标操作信息的规则,例如可以是根据经验选取,也可以是服务器按照预设规则在第二行为序列中选择的一种操作信息。预设规则例如可以是选取第二行为序列中出现频率最高的操作信息。例如,目标操作信息为登录失败,预设时间段为最近12小时,那么目标次数即为第二行为序列中在最近12小时内出现登录失败的次数。
在步骤103中,根据目标操作信息和目标次数,确定与第二行为序列匹配的异常样本用户的第一用户数量,和与第二行为序列匹配的正常样本用户的第二用户数量。
在步骤104中,若第一用户数量与第二用户数量的比值大于或等于预设的比例阈值,确定第二行为序列为异常行为。
举例来说,在获取到目标次数后,可以根据目标操作信息和目标次数,确定与第二行为序列匹配的异常样本用户的第一用户数量,和与第二行为序列匹配的正常样本用户的第二用户数量。根据目标操作信息和目标次数,确定某一样本用户(异常样本用户或正常样本用户)与第二行为序列是否匹配的方式可以是:确定第二行为序列和该样本用户对应的行为序列是否满足预设的条件,当满足预设条件时,确定该样本用户与第二行为序列匹配。
之后根据第一用户数量和第二用户数量确定第二行为序列是否为异常行为,确定第二行为序列是否为异常行为的方式可以是将第一用户数量和第二用户数量的比值,与预设的比例阈值进行比较,若第一用户数量与第二用户数量的比值大于或等于预设的比例阈值,确定第二行为序列为异常行为,若第一用户数量与第二用户数量的比值小于预设的比例阈值,确定第二行为序列不为异常行为。例如,预设的比例阈值为4,与第二行为序列匹配的异常样本用户的第一用户数量为100,与第二行为序列匹配的正常样本用户的第二用户数量为20,则第一用户数量与第二用户数量的比值大于4,确定第二行为序列为异常行为。可以理解为,当与第二行为序列匹配的正常样本用户较多时,即第二行为序列中包括的操作信息不具有代表性,较多的正常样本用户也会执行第二行为序列中包括的操作信息,那么第二行为序列不为异常行为,从而避免对正常用户的误判。当与第二行为序列匹配的异常样本用户较多时,即第二行为序列中包括的操作信息具有代表性,较多的异常样本用户会执行第二行为序列中包括的操作信息,那么第二行为序列为异常行为,从而提高检测的准确度。
需要说明的是,现有技术中,如果只通过目标操作信息出现的次数来确定第二行为序列,那么就无法区分目标操作信息出现的次数相同,但操作信息的执行顺序不同的第二行为序列。而本方案通过频繁路径挖掘算法能够根据行为序列中操作信息的执行顺序来识别第二行为序列,再结合第二行为序列中目标操作信息出现的次数,从而提高检测的准确度。例如,通过频繁路径挖掘算法得到了两个第二行为序列(i1,i2,i2,i2)和(i2,i2,i2,i1),目标操作信息为i2,两个第二行为序列中i2出现的次数也相同,但i2的执行顺序不同,因此两个第二行为序列不相同。
综上所述,首先根据异常样本用户对应的第一行为序列和预设的频繁路径挖掘算法,在第一行为序列中确定异常的第二行为序列,其中,第一行为序列包括:操作信息和操作信息对应的操作时间信息,再获取第二行为序列中,在预设时间段内目标操作信息出现的目标次数,之后根据目标操作信息和目标次数,确定与第二行为序列匹配的异常样本用户的第一用户数量,和与第二行为序列匹配的正常样本用户的第二用户数量,若第一用户数量与第二用户数量的比值大于或等于预设的比例阈值,确定第二行为序列为异常行为。本公开通过结合用户行为的发生顺序和在预设时间段内的出现次数来确定用户行为是否异常,能够提高异常用户检测的准确度,有效地避免对正常用户的误判。
需要说明的是,步骤101中频繁路径挖掘算法的实现方式可以包括:
以异常样本用户为多个来举例,对应的存在多个第一行为序列。将多个第一行为序列和预设的支持度阈值作为频繁路径挖掘算法的输入,并获取频繁路径挖掘算法输出的至少一个第二行为序列。其中,第二行为序列在第一行为序列中出现的频率都大于或等于支持度阈值。
频繁路径挖掘算法为根据预设的支持度阈值对多个第一行为序列进行逐层迭代,得到满足预设的支持度阈值的频繁项集,并从得到的多个频繁项集中选取符合预设项数(可以理解为频繁项集中包括的操作信息的数量大于或等于预设项数)的频繁项集作为至少一个第二行为序列。其中,频繁路径挖掘算法例如可以是apriori(中文:关联规则)算法,gsp(英文:generalizedsequentialpattern,中文:广义序列模式)算法和freespan算法。
其中,支持度阈值可以是预先设置的,也可以根据具体需求灵活调整,当支持度阈值过低时,即频繁路径挖掘算法会输出较多的第二行为序列,容易造成误判,当支持度阈值过高时,即频繁路径挖掘算法会输出较少的第二行为序列,容易造成漏检。因此支持度阈值可以先根据经验进行设置,之后再根据频繁路径挖掘算法输出第二行为序列的多少对支持度阈值进行调整。以有4个第一行为序列(i1,i2,i3),(i1,i2),(i1)和(i2,i3),i1,i2,i3分别对应三个不同的操作信息,预设的支持度阈值为2,预设项数为2(即第二行为序列中包含的操作信息的数量至少为2个)为例,将4个第一行为序列和预设的支持度阈值作为频繁路径挖掘算法的输入,得到的频繁项集为(i1),(i2),(i3),(i1,i2)和(i2,i3),从得到的多个频繁项集中选取预设项数为2的频繁项集作为第二行为序列,则频繁路径挖掘算法输出的第二行为序列为(i1,i2)和(i2,i3)。
图2是图1所示实施例示出的一种步骤103的流程图。如图2所示,步骤103包括以下步骤:
在步骤1031中,根据目标操作信息和目标次数,确定样本用户集中与第二行为序列匹配的至少一个目标样本用户。
在步骤1032中,确定至少一个目标样本用户包括的异常样本用户的第一用户数量,和正常样本用户的第二用户数量。
具体地,可以在服务器上的数据库中预先存储有样本用户集(包括了多个样本用户),和样本用户集中每个样本用户对应的行为序列,多个样本用户可以分为正常样本用户和异常样本用户。在获取到目标次数后,可以根据目标操作信息和目标次数,确定在样本用户集中,与第二行为序列匹配的至少一个目标样本用户。根据目标操作信息和目标次数,确定目标样本用户与第二行为序列是否匹配的方式可以是:确定任一样本用户对应的行为序列与第二行为序列是否满足预设的条件,当满足预设的条件时,确定任一样本用户与第二行为序列匹配,即为目标样本用户。根据至少一个目标样本用户中包括的异常样本用户和正常样本用户的数量,确定第一用户数量和第二用户数量。
可选地,步骤1031可以通过以下方式实现:
若第二行为序列为样本用户集中任一样本用户对应的第三行为序列的子序列,且第三行为序列中,在预设时间段内目标操作信息出现的次数与目标次数满足第一预设条件,确定任一样本用户为目标样本用户。
第一预设条件为:在预设时间段内目标操作信息出现的次数大于或等于目标次数,或,在预设时间段内目标操作信息出现的次数与目标次数的比值大于或等于第一阈值。
举例来说,若第二行为序列为样本用户集中任一样本用户对应的第三行为序列的子序列(即第三行为序列中包括的多个操作信息中,不仅包含了第二行为序列中的每个操作信息,还可能包含了其它操作信息),且第三行为序列中,在预设时间段内目标操作信息出现的次数与目标次数满足第一预设条件时,确定任一样本用户为目标样本用户。
图3是根据一示例性实施例示出的另一种确定异常行为的方法的流程图。如图3所示,该方法还包括:
在步骤105中,在获取到目标用户对应的目标行为序列后,若第二行为序列为目标行为序列的子序列,且目标行为序列中,在预设时间段内目标操作信息出现的次数与目标次数满足第二预设条件,确定目标用户为异常用户。
第二预设条件为:在预设时间段内目标操作信息出现的次数大于或等于目标次数,或,在预设时间段内目标操作信息出现的次数与目标次数的比值大于或等于第二阈值。
示例的,当确定第二行为序列为异常行为时,可以将第二行为序列、目标操作信息和目标次数存入服务器的数据库中,作为检测异常用户的依据。当目标用户访问数据库时,记录目标用户的操作信息,和操作信息对应的操作时间信息,以获取目标用户对应的目标行为序列。在获取到目标用户对应的目标行为序列后,判断第二行为序列是否为目标行为序列的子序列,若第二行为序列为目标行为序列的子序列,进一步判断目标行为序列中,在预设时间段内目标操作信息出现的次数与目标次数是否满足第二预设条件。若第二行为序列为目标行为序列的子序列,且目标行为序列中,在预设时间段内目标操作信息出现的次数与目标次数满足第二预设条件,确定目标用户为异常用户。
例如,第二行为序列为(i1,i2,i1,i1,i3,i1,i1,i1),目标操作信息为i1,在3小时内i1出现的次数(即目标次数)为4,目标用户对应的目标行为序列为(i1,i2,i1,i1,i3,i1,i1,i1,i1,i1),目标行为序列中,在3小时内i1出现的次数为6,第二预设条件为:在预设时间段内目标操作信息出现的次数大于或等于目标次数。第二行为序列为目标行为序列的子序列,且目标行为序列中,在预设时间段(3小时)内i1出现的次数(6)大于目标次数(4),则目标用户为异常用户。
进一步的,当确定目标用户为异常用户时,服务器可以对目标用户进行权限管控(例如:强制退出、输入验证码、或者拥有浏览权限,无编辑权限等),以保证服务器和访问服务器的其他用户的安全。
需要说明的是,如果只将目标操作信息出现的次数作为检测目标用户的依据,不考虑目标行为序列中包括的多个操作信息之间的发生顺序,可能会误杀正常用户。例如,目标用户1对应的目标行为序列1中包括了i1,i2,i2,i2,目标用户2对应的目标行为序列2中包括了i2,i2,i2,i1。其中,操作信息i1表示登录成功操作,操作信息i2表示登录失败操作,i1和i2对应的操作时间信息都处于最近1天内,目标行为序列中操作的出现顺序对应为操作的执行顺序,即目标用户1的执行顺序为:i1,i2,i2,i2,目标用户2的执行顺序为:i2,i2,i2,i1。现有技术中,如果只通过目标操作信息出现的次数满足预设条件来检测异常用户,当目标操作信息为i2时,预设条件为最近1天内i2出现的次数大于或等于3时,会将目标用户1和目标用户2都作为异常用户。而在现实场景中,目标用户1可能是正常的(例如:目标用户1成功登录后,再次登录时输错了密码),目标用户2可能是异常的(例如:撞库行为)。本方案通过结合用户行为的发生顺序和目标操作信息出现的次数来确定用户行为是否异常,首先在确定第二行为序列时,能够将(i2,i2,i2,i1)和(i1,i2,i2,i2)作为两个不同的第二行为序列,之后结合两个第二行为序列中,在预设时间段内目标操作信息出现的次数,再确定样本用户集中与这两个第二行为序列匹配的样本用户,根据第一用户数量和第二用户数量,可以确定(i2,i2,i2,i1)为异常行为,(i1,i2,i2,i2)不为异常行为,因此能够判断目标用户1为正常用户,目标用户2为异常用户,以降低误杀正常用户的概率。
综上所述,首先根据异常样本用户对应的第一行为序列和预设的频繁路径挖掘算法,在第一行为序列中确定异常的第二行为序列,其中,第一行为序列包括:操作信息和操作信息对应的操作时间信息,再获取第二行为序列中,在预设时间段内目标操作信息出现的目标次数,之后根据目标操作信息和目标次数,确定与第二行为序列匹配的异常样本用户的第一用户数量,和与第二行为序列匹配的正常样本用户的第二用户数量,若第一用户数量与第二用户数量的比值大于或等于预设的比例阈值,确定第二行为序列为异常行为。本公开通过结合用户行为的发生顺序和在预设时间段内的出现次数来确定用户行为是否异常,能够提高异常用户检测的准确度,有效地避免对正常用户的误判。
图4是根据一示例性实施例示出的一种确定异常行为的装置的框图。如图4所示,装置200包括:
第一确定模块201,被配置为根据异常样本用户对应的第一行为序列和预设的频繁路径挖掘算法,在第一行为序列中确定异常的第二行为序列,第一行为序列包括:操作信息和操作信息对应的操作时间信息。
获取模块202,被配置为获取第二行为序列中,在预设时间段内目标操作信息出现的目标次数,目标操作信息为按照预设规则在第二行为序列中选择的一种操作信息。
第二确定模块203,被配置为根据目标操作信息和目标次数,确定与第二行为序列匹配的异常样本用户的第一用户数量,和与第二行为序列匹配的正常样本用户的第二用户数量。
判断模块204,被配置为若第一用户数量与第二用户数量的比值大于或等于预设的比例阈值,确定第二行为序列为异常行为。
图5是图4所示实施例示出的一种第二确定模块的框图。如图5所示,第二确定模块203包括:
第一确定子模块2031,被配置为根据目标操作信息和目标次数,确定样本用户集中与第二行为序列匹配的至少一个目标样本用户。
第二确定子模块2032,被配置为确定至少一个目标样本用户包括的异常样本用户的第一用户数量,和正常样本用户的第二用户数量。
可选地,第一确定子模块2031被配置为若第二行为序列为样本用户集中任一样本用户对应的第三行为序列的子序列,且第三行为序列中,在预设时间段内目标操作信息出现的次数与目标次数满足第一预设条件,确定任一样本用户为目标样本用户。
第一预设条件为:在预设时间段内目标操作信息出现的次数大于或等于目标次数,或,在预设时间段内目标操作信息出现的次数与目标次数的比值大于或等于第一阈值。
图6是根据一示例性实施例示出的另一种确定异常行为的装置的框图。如图6所示,装置200还包括:
第三确定模块205,被配置为在获取到目标用户对应的目标行为序列后,若第二行为序列为目标行为序列的子序列,且目标行为序列中,在预设时间段内目标操作信息出现的次数与目标次数满足第二预设条件,确定目标用户为异常用户。
第二预设条件为:在预设时间段内目标操作信息出现的次数大于或等于目标次数,或,在预设时间段内目标操作信息出现的次数与目标次数的比值大于或等于第二阈值。
关于上述实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,此处将不做详细阐述说明。
综上所述,首先根据异常样本用户对应的第一行为序列和预设的频繁路径挖掘算法,在第一行为序列中确定异常的第二行为序列,其中,第一行为序列包括:操作信息和操作信息对应的操作时间信息,再获取第二行为序列中,在预设时间段内目标操作信息出现的目标次数,之后根据目标操作信息和目标次数,确定与第二行为序列匹配的异常样本用户的第一用户数量,和与第二行为序列匹配的正常样本用户的第二用户数量,若第一用户数量与第二用户数量的比值大于或等于预设的比例阈值,确定第二行为序列为异常行为。本公开通过结合用户行为的发生顺序和在预设时间段内的出现次数来确定用户行为是否异常,能够提高异常用户检测的准确度,有效地避免对正常用户的误判。
图7是根据一示例性实施例示出的一种确定异常行为的装置的框图。例如,装置300可以被提供为一服务器。参照图7,装置300包括处理组件322,其进一步包括一个或多个处理器,以及由存储器332所代表的存储器资源,用于存储可由处理组件322的执行的指令,例如应用程序。存储器332中存储的应用程序可以包括一个或一个以上的每一个对应于一组指令的模块。此外,处理组件322被配置为执行指令,以执行上述确定异常行为的方法。
装置300还可以包括一个电源组件326被配置为执行装置300的电源管理,一个有线或无线网络接口350被配置为将装置300连接到网络,和一个输入输出(i/o)接口358。装置300可以操作基于存储在存储器332的操作系统,例如windowsservertm,macosxtm,unixtm,linuxtm,freebsdtm或类似。
本公开还提供一种计算机可读存储介质,其上存储有计算机程序指令,该程序指令被处理器执行时实现本公开提供的确定异常行为的方法的步骤。
综上所述,首先根据异常样本用户对应的第一行为序列和预设的频繁路径挖掘算法,在第一行为序列中确定异常的第二行为序列,其中,第一行为序列包括:操作信息和操作信息对应的操作时间信息,再获取第二行为序列中,在预设时间段内目标操作信息出现的目标次数,之后根据目标操作信息和目标次数,确定与第二行为序列匹配的异常样本用户的第一用户数量,和与第二行为序列匹配的正常样本用户的第二用户数量,若第一用户数量与第二用户数量的比值大于或等于预设的比例阈值,确定第二行为序列为异常行为。本公开通过结合用户行为的发生顺序和在预设时间段内的出现次数来确定用户行为是否异常,能够提高异常用户检测的准确度,有效地避免对正常用户的误判。
本领域技术人员在考虑说明书及实践本公开后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本公开的真正范围和精神由下面的权利要求指出。
应当理解的是,本公开并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本公开的范围仅由所附的权利要求来限制。
- 还没有人留言评论。精彩留言会获得点赞!