一种机构名实体识别方法与流程
本发明属于自然语言处理中的实体识别领域,其中涉及一种基于lstm(longshort-termmemory)和gcn(graphconvolutionalnetwork)结构的机构名实体识别方法。
背景技术:
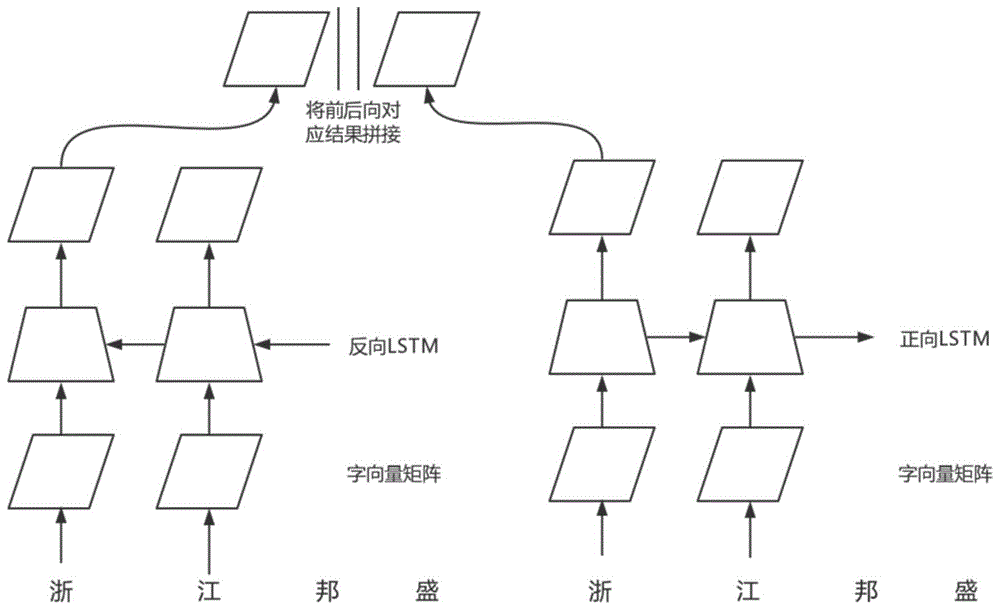
:随着世界的高速发展,各类文本数据都呈现出了爆炸式的增长趋势,从海量的文本数据中高效、准确地提炼出有效信息的相关技术正在成为众多公司和研究机构所关注的热点。传统的信息检索方法,通常通过字符串模糊匹配的方式,对文本中的目标信息进行抓取,再通过后续的规则方法过滤出有效信息。这种方法虽然可以在一定程度上获取到目标信息,但在海量文本复杂的上下文情景下其方法效率较低,且准确率难以达到要求。机构名实体识别是从指定文本上下文中识别出具有机构名意义的实体部分。在中文实体识别中,其过程主要分为两步:(1)实体的边界划分;(2)实体类别的识别。因为中文与英文语言特性的差异,中文实体识别需要对实体的边界进行划分,这一点使得中文实体识别相较于英文实体识别挑战更大,问题更多。技术实现要素:本发明的目的在于针对现有技术的不足,提供一种通过引入外部语料预训练词向量,基于词的gcn模型进行机构名实体识别的方法。本发明的目的是通过以下技术方案来实现的:一种机构名实体识别方法,该方法包括以下步骤:步骤1:将目标领域中的专有名词作为领域词构成领域词词库,为领域词中出现的每个字符分配与其对应的字向量。步骤2:将领域词词库中的字符进行数字编码,每个数字编码分别对应该字符的字向量序号,并使用数字编码来编码领域词词库中的每一个词。步骤3:对步骤2中产生的词编码进行one-hot编码后,用无监督方法进行字向量训练,得到以每个字符的领域字向量为行元素的矩阵,记为领域信息矩阵。步骤4:在步骤3训练出的领域字向量基础上加入通用标记语料n的上下文信息,得到最终使用的字向量矩阵。步骤5:使用步骤4产生的最终使用的字向量矩阵以及通用标记语料n训练分词模型。步骤6:统计通用标记语料n的n-gram特征,在n-gram特征大于设定阈值的词对之间建立拓扑连接,权重为n-gram特征值,生成拓扑关系矩阵。步骤7:根据拓扑关系矩阵分析通用标记语料n,生成词和词之间的拓扑关系。通过查询拓扑关系矩阵相应词对出现的频次,若其大于预期值s则认为它们之间存在拓扑关系,否则无拓扑关系。步骤8:将通用标记语料n和步骤7中产生的拓扑关系作为gcn模型的输入,训练机构名实体识别模型。步骤9:在预测时,首先将待预测语料送入步骤5中所产生的分词模型,获得分词结果后,再根据步骤6中获得的拓扑关系矩阵分析其拓扑关系,最后将分词结果和拓扑关系作为步骤8获得的机构名实体识别模型的输入,来获得最终的机构名实体识别结果。进一步地,所述步骤1中,为单音字分配一个字向量,为多音字的每个发音分配一个字向量;所述步骤2中,对于多音字,为每种发音生成一个数字编码。进一步地,所述步骤3中,对词编码进行one-hot编码后,使用cbow(continuousbag-of-words)或skip-gram方法进行n维字向量训练。进一步地,所述步骤4中,将领域字向量和通用标记语料n训练出的字向量进行拼接,得到最终使用的字向量矩阵,具体包括以下子步骤:i)使用双向lstm训练通用标记语料n的字向量。用通用标记语料n训练双向lstm模型后,将同一个字符的前向和后向输出结果进行拼接后作为该字符的通用字向量。以这些通用字向量为行元素的矩阵记为通用上下文信息矩阵;ii)将领域信息矩阵和通用上下文信息矩阵中相同字符的字向量进行拼接整合,得到最终字向量矩阵。若相应字符只在领域信息矩阵中或通用上下文信息矩阵中出现,则用0向量进行拼接补齐为等维向量。iii)对步骤ii)获得的字向量矩阵进行降维,得到最终使用的字向量矩阵。进一步地,所述步骤4中,固定领域字向量,根据通用标记语料n的上下文信息构建以领域字向量为中心的其它字符的字向量表达,得到最终使用的字向量矩阵,具体包括以下子步骤:i)将步骤3中训练得到的领域字向量作为其代表字符的初始化值,初始化到双向lstm模型前接的embedding层,作为对应字符的初始化字符向量,并将其固定,即在训练过程中不改变初始化字符向量的值。对于在通用上下文信息矩阵中出现,但在领域信息矩阵中未出现的字符,将该字符对应的字符向量初始化为全部由0组成的等维向量。ii)使用通用标记语料n训练双向lstm模型,以领域字向量为中心,构建在通用上下文信息矩阵中出现,但在领域信息矩阵中未出现的字符对应的字向量。训练完成后将前向lstm和后向lstm的两个embedding层中表示同一字符的两个字向量进行拼接,最终使用的字向量矩阵。进一步地,所述步骤5中,所述分词模型需选择可引入字向量的分词模型,包括bi-lstm,cnn等模型。本发明的有益效果是:本发明方法解决了在特定领域的机构名识别场景下,领域标记语料不足、识别准确率低以及对于领域专有名词识别能力较弱的问题。附图说明图1为将领域字向量和通用语料训练出的字向量进行拼接模型示意图;图2为固定领域字向量,以其为中心构建相关字表达的模型示意图。具体实施方式下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述,以下实施例用于说明本发明,但不用来限制本发明的范围。本发明提供的一种机构名实体识别方法,该方法包括以下步骤:步骤1:将目标领域中的专有名词作为领域词构成领域词词库,为领域词中出现的每个字符分配与其对应的字向量,为单音字分配一个字向量,为多音字的每个发音分配一个字向量。如“审判长”为一个领域词,因“长”字为多音字,拼音分别为“cháng”和“zhǎng”,因此“长”字有两个字向量,分别对应两种发音。步骤2:将领域词词库中的字符进行数字编码,每个数字编码分别对应该字符的字向量序号。对于多音字,为每种发音生成一个数字编码。并使用数字编码来编码领域词词库中的每一个词。步骤3:对步骤2中产生的词编码进行one-hot编码后,使用无监督方法进行n维字向量训练,可选择cbow(continuousbag-of-words)或skip-gram方法,得到以每个字符的领域字向量为行元素的矩阵,记为领域信息矩阵,以如下形式表示:[x0,0x0,1…x0,n][x1,0x1,1…x1,n][xk,0xk,1…xk,n]其中,k为领域词词库中出现的不同字符总数,n为人为设定的领域字向量维度。步骤4:在步骤3训练出的领域字向量基础上加入通用标记语料n(可以采用人民日报语料库、搜狗新闻语料库等)的上下文信息,得到最终使用的字向量矩阵,这里有两套方案可选,根据具体领域情况而定:方案1:将领域字向量和通用标记语料n训练出的字向量进行拼接。i)使用双向lstm训练通用标记语料n的字向量。其示意图如图1所示,用通用标记语料n训练双向lstm模型后,将同一个字符的前向和后向输出结果进行拼接后作为该字符的通用字向量。如图1中将“浙”字的前向输出和后向输出进行了拼接。以这些通用字向量为行元素的矩阵记为通用上下文信息矩阵,以如下形式表示:[y0,0y0,1…y0,q][y1,0y1,1…y1,q][yl,0yl,1…yl,q]其中,l为通用标记语料n中出现的不同字符总数;q为人为设定的通用字向量维度;ii)将领域信息矩阵和通用上下文信息矩阵中相同字符的字向量进行拼接整合,得到最终字向量矩阵。例如,若[xi,0xi,1…xi,n]和[yj,0yj,1…yj,q]表达的是同一个字符则将其拼接成[xi,0xi,1…xi,nyj,0yj,1…yj,q],若同一字符存在多个字向量则将同一发音的字向量进行拼接。若相应字符只在领域信息矩阵中或通用上下文信息矩阵中出现,则用0向量进行拼接补齐为q+n维。其形式为:[xr,0xr,1…xr,n00…0]和[00…0ys,0ys,1…ys,q]。iii)上一步中得到最终字向量矩阵,其字向量维度往往较大,且较为稀疏,此处将使用一些降维方法对字向量进行降维,可选pca(principalcomponentanalysis)降维方法。降维后的字向量矩阵才是最终使用的字向量矩阵。方案2:固定领域字向量,根据通用标记语料n的上下文信息构建以领域字向量为中心的其它字符的字向量表达。i)将步骤3中训练得到的领域字向量作为其代表字符的初始化值,初始化到双向lstm模型前接的embedding层,作为对应字符的初始化字符向量,如图2所示,并将其固定,即在训练过程中不改变初始化字符向量的值。对于在通用上下文信息矩阵中出现,但在领域信息矩阵中未出现的字符,将该字符对应的字符向量初始化为全部由0组成的等维向量。ii)使用通用标记语料n训练双向lstm模型,以领域字向量为中心,构建在通用上下文信息矩阵中出现,但在领域信息矩阵中未出现的字符对应的字向量。训练完成后将前向lstm和后向lstm的两个embedding层中表示同一字符的两个字向量进行拼接,最终使用的字向量矩阵,如图2所示。步骤5:使用步骤4产生的最终使用的字向量矩阵以及通用标记语料n训练分词模型,分词模型需选择可引入字向量的分词模型,如:bi-lstm,cnn等模型。步骤6:统计通用标记语料n的n-gram特征,在n-gram特征大于设定阈值的词对之间建立拓扑连接,权重为n-gram特征值,生成拓扑关系矩阵。以二维n-gram特征(即根据两个相连词的组合情况进行统计)为例子:有一条语料:浙江|邦盛科技|位于|杭州。其中“|”为分词标记,我们在统计二维n-gram特征的时候,根据词对进行统计,如“浙江”和“邦盛科技”这两个词前后相连出现,则其词对频次加1,同样的词对“邦盛科技”和“位于”也加1。将这条语料处理后其n-gram特征形成的矩阵如下:浙江邦盛科技位于杭州浙江0100邦盛科技1010位于0101杭州0010将所有语料进行上述统计操作并累加合并成一个大矩阵后即为最终的拓扑关系矩阵。步骤7:根据拓扑关系矩阵分析通用标记语料n,生成词和词之间的拓扑关系。通过查询拓扑关系矩阵相应词对出现的频次,若其大于预期值s则认为它们之间存在拓扑关系,否则无拓扑关系。步骤8:将通用标记语料n和步骤7中产生的拓扑关系作为gcn模型的输入,训练机构名实体识别模型。步骤9:在预测时,首先将待预测语料送入步骤5中所产生的分词模型,获得分词结果后,再根据步骤6中获得的拓扑关系矩阵分析其拓扑关系,最后将分词结果和拓扑关系作为步骤8获得的机构名实体识别模型的输入,来获得最终的机构名实体识别结果。上述实施例用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1