基于多模态深度学习的病理分类方法及系统与流程
本发明涉及计算机技术中的计算机视觉和图像处理领域,特别是涉及一种基于多模态深度学习的病理分类方法及系统。
背景技术:
癌症是一个重要的世界范围内的公共健康问题。在所有的癌症类型中,乳腺癌是女性第二大常见癌症。此外,与其他类型的癌症相比,乳腺癌的死亡率非常高。虽然医学科学飞速发展,但是病理图像分析仍然是乳腺癌诊断中应用最广泛的方法。然而,组织病理学图像的复杂性和工作量的急剧增加使得这项任务非常耗时,而且其结果易受到病理学家的主观性的影响。面对这一难题,发展准确的乳腺癌自动诊断方法是这一领域非常迫切需求。
近年来,深度学习方法在计算机视觉和图像处理领域取得了长足的进步和显著的成绩。这也启发了许多专家将该技术应用于病理图像分析。尽管如此,仅凭单模态的病理图像数据对乳腺癌进行良恶性分类的准确性并不能满足临床实践的需要。
虽然仅利用病理图像无法获得较高的分类准确度,但是病理图像提供了一个丰富的环境和emr中结构化数据的融合,使得新的信息可以被获取和量化。尤其是原始病理图像是高维度的信息,它的获取需要更少的人力,但它包含了大量潜在的未被发现的信息。临床医生从电子病历(emr)中提取的结构化的临床信息的特征维度较低,但是,这些临床信息为诊断提供了更多的指导。
技术实现要素:
针对上述现有技术的不足,本发明提出了一种基于多模态深度学习的乳腺癌分类方法,解决了现有技术中根据单模态的特征表示来进行乳腺癌良恶性分类的准确率不高的技术问题。
针对现有技术的不足,本发明提出一种基于多模态深度学习的病理分类方法,其中包括:
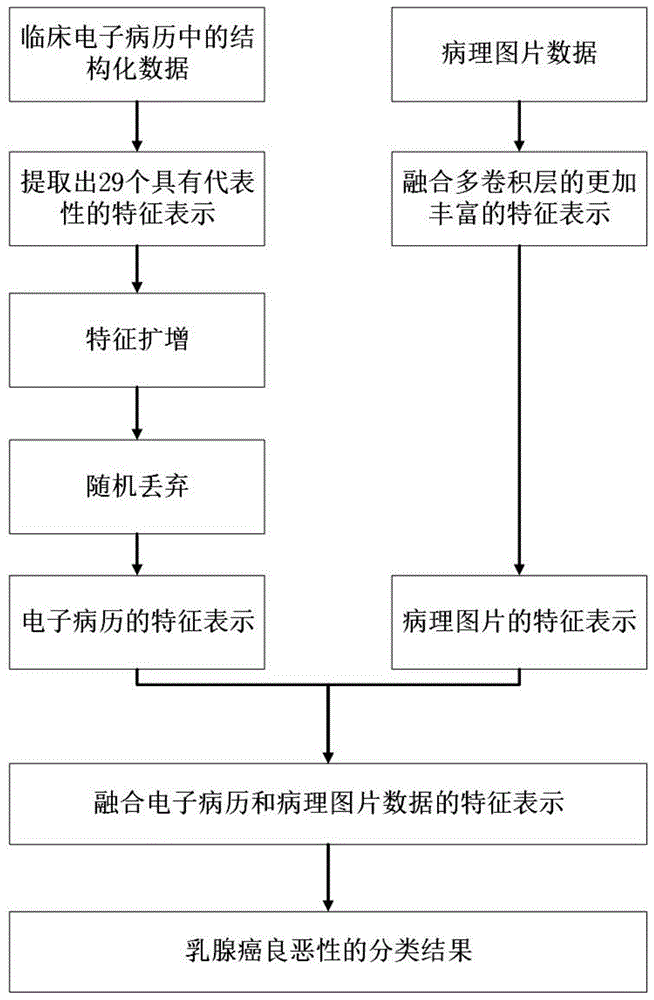
步骤1、从电子病历中提取出预先选择的属性作为结构化数据的特征表示向量,将该特征表示向量平均扩增后再按照预设比例随机丢弃,丢弃的部分被替换为数字0,作为电子病历中结构化数据的病历特征向量;
步骤2、获取与该电子病历对应的组织病理学图像,将卷积神经网络的各卷积层的特征图进行全局平均池化后拼接成一维向量,作为该组织病理学图像的一种丰富的图像特征向量;
步骤3、将该图像特征向量和该病历特征向量拼接在一起,得到多模态融合向量,然后将该多模态融合向量输入至全连接层,得到二值化的病理分类结果。
所述的基于多模态深度学习的病理分类方法,其中该步骤1包括:从该电子病历中提取出29个在医学理论上与乳腺癌的诊断密切相关的属性组成特征向量,再把从临床电子病历中提取的29维向量平均扩增一预设比例,然后按照一预设百分比随机丢弃,丢弃的部分被替换为数字0。
所述的基于多模态深度学习的病理分类方法,其中该步骤2包括:利用卷积神经网络的第三、第四和第五层卷积层,提取得到第三、第四和第五卷积层的特征图,然后使用全局平均池化操作将第三、第四和第五卷积层的特征图进行压缩后,拼接成该组织病理图像的特征表示向量。
所述的基于多模态深度学习的病理分类方法,其中步骤3中该全连接层为三个完整的连接层,分别有500,100和2个节点。
本发明还提出了一种基于多模态深度学习的病理分类系统,其中包括:
模块1、从电子病历中提取出预先选择的属性作为结构化数据的特征表示向量,将该特征表示向量平均扩增后再按照预设比例随机丢弃,丢弃的部分被替换为数字0,作为电子病历中结构化数据的病历特征向量;
模块2、获取与该电子病历对应的组织病理学图像,将卷积神经网络的各卷积层的特征图进行全局平均池化后拼接成一维向量,作为该组织病理学图像的一种丰富的图像特征向量;
模块3、将该图像特征向量和该病历特征向量拼接在一起,得到多模态融合向量,然后将该多模态融合向量输入至全连接层,得到二值化的病理分类结果。
所述的基于多模态深度学习的病理分类系统,其中该模块1包括:从该电子病历中提取出29个在医学理论上与乳腺癌的诊断密切相关的属性组成特征向量,再把从临床电子病历中提取的29维向量平均扩增一预设比例,然后按照一预设百分比随机丢弃,丢弃的部分被替换为数字0。
所述的基于多模态深度学习的病理分类系统,其中该模块2包括:利用卷积神经网络的第三、第四和第五层卷积层,提取得到第三、第四和第五卷积层的特征图,然后使用全局平均池化操作将第三、第四和第五卷积层的特征图进行压缩后,拼接成该组织病理图像的特征表示向量。
所述的基于多模态深度学习的病理分类系统,其中模块3中该全连接层为三个完整的连接层,分别有500,100和2个节点。
本发明还提出了一种存储介质,用于存储执行所述基于多模态深度学习的病理分类方法的程序。
与现有技术相比,本发明具有以下的有益效果:
(1)首次集成多模态数据来诊断乳腺癌,而且基于深度学习的多模态融合方法的准确率显著优于仅使用任何单一模态信息的方法;
(2)为了使病理图像与emr中结构化数据更加充分地融合,本发明提出了一种从多个卷积层中提取病理图像的更加丰富的特征表示的方法,可以保留更加完整的图像信息,特别是在高层卷积中损失的局部纹理和细节信息;
(3)为了在数据融合前不丢失各个模态的信息,本发明采用了一种低维数据扩增的方法,而不是数据融合前就将高维数据压缩为低维数据。这样,在信息融合之前的每一个模态都有足够的信息,这为更加充分的信息融合提供了前提;
(4)提出了一种在模型的训练过程中随机丢弃结构化数据的策略。该策略使得模型对emr中缺少部分结构化数据的情况具有更好的泛化能力,同时,也降低了整个模型的过拟合的风险。
附图说明
图1为实施数据融合的结构示意图;
图2为多模态数据融合的方法细节示意图;
图3为使用的病理图片数据集的描述示意图。
具体实施方式
本申请提出一种数据融合的方法来模拟病理诊断任务。从多模态数据融合的角度,尝试将电子病历emr中的病理图像与结构化数据相结合,进一步提高乳腺癌诊断的准确性。这也符合病理学家阅读病理图像进行诊断时的实际情况。病理学家在阅读病理图像时,会反复的参考患者emr中的相关临床结构化信息,以此作为先验,直至做出最后的诊断。其中,通过与病理学家的讨论和查阅乳腺癌相关的医学文献,从临床电子病历中提取出29个具有代表性的属性。这些属性在医学理论上与乳腺癌的诊断密切相关,而且,这29个属性都是常规的临床指标,可以从现有的医院信息系统的数据库中直接取得。
目前为止,几乎没有使用多模态数据对乳腺癌进行分类的方法,但是多模态融合方法在医学的其他领域,例如文本、影像等领域已取得良好效果。虽然他们的融合方法比传统的方法取得了更好的效果,但是它仍然有一些问题,如图像的特征表示不够丰富、信息融合的不够充分、尤其是在信息融合前就损失了高维的信息,和实际场景中经常遇到的部分缺失数据的问题。
本发明提出了如下的技术方案:一种基于多模态数据融合的乳腺癌分类方法,包括:
步骤1:首先进行了数据增强。除了将整幅图的大小调整到224*224像素,还随机从2048*1536的原始图像中提取了40、20、10和5个大小分别为224*224、512*512、1024*1024和1536*1536的图片块。同时,我们也对图像进行了常规的数据增强,如随机翻转、旋转、亮度等;
步骤2:在结构化数据方面,通过与病理学家的讨论和查阅乳腺癌相关的医学文献,从临床电子病历中提取由29个具有代表性的特征组成的特征向量,这些特征在医学理论上与乳腺癌的诊断密切相关;
步骤3:在病理图像方面,从vgg16卷积神经网络中提取第三、第四、第五卷积层,然后将它们全局平均池化后拼接成一个1280维的向量作为病理图片的更丰富的特征表示;
步骤4:先把从临床电子病历中提取的29维向量平均扩增了20次(29d*20),然后按照一定的百分比(20%)随机丢弃,丢弃的部分被替换为数字0;
步骤5:最后,将从结构化数据中提取的29d*20维向量与病理图像中提取的1280d维向量拼接在一起,形成一个1860d的向量。然后这个1860d的向量经过接下来的三个全连接层,得到良性和恶性乳腺癌之间的分类结果。三个完整的连接层分别有500,100和2个节点。
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。需要注意的是,本申请的处理对象为病理学图像和结构化的电子病历,而非以有生命的人体为直接实施对象,且本申请还可用于医疗教学领域。本发明的病理分类不限于肿瘤良恶性的分类,下文仅以乳腺癌的良恶性分类进行说明。
步骤1:首先进行了数据增强。除了将整幅图的大小调整到224*224像素,我们还随机从2048*1536的原始图像中提取了40、20、10和5个大小分别为224*224、512*512、1024*1024和1536*1536的图像块patch。同时,我们也对图像进行了常规的数据增强,如随机翻转、旋转、亮度等。最后,我们有(40+20+10+5)*3764*9,即2540700对训练样本。这里需要指出的是,emr中的一条结构化数据通常对应多张病理图像。因此,在训练阶段以病理图像的数量为基准,将每张病理图像和其配对的结构化数据一起送入网络进行训练。最新的研究指出卷积神经网络结构对病理图像的细微的颜色变化是鲁棒的,因此颜色归一化对于获得好的效果并不是必须的。因此,与目前大多数深度学习方法在病理图像中的应用不同,我们没有对图像进行归一化预处理。
步骤2:通过与病理学家的讨论和查阅乳腺癌相关的医学文献,我们从临床电子病历中挑选出与乳腺癌诊断密切相关的29个代表性的特征,以此作为结构化数据来表示患者的临床病情描述。具体地说,这些29特性包括年龄、性别、病程类型、胸肌粘连、个人肿瘤史、家族肿瘤史、前期治疗、新辅助化疗、酒窝症、橘皮症、皮肤红肿、皮肤破溃、有无肿块、乳房变形、乳头改变、乳头溢液、腋窝淋巴结肿大、锁骨上淋巴结肿大、肿瘤部位、肿瘤数目、肿瘤大小、肿瘤质地、肿瘤边界、表面是否光滑、肿瘤形态、活动度、包膜、压痛、皮肤粘连及诊断。根据实际情况,将数据量化为具体数值。患者的病历号是电子病历和病理图像的唯一标识符。具体的特征的描述如表1所示。
表1临床电子病历中提取的29个特征作为结构化信息:
步骤3:接下来我们使用多卷积层融合的方法提取病理图片的特征表示。由于病理图像中的对象具有不同的尺度和较高的复杂性,学习丰富的层次表示对于多模态数据的融合至关重要。此外,随着卷积层数的增加,卷积神经网络提取的卷积特征逐渐变的粗糙。受这些观测结果的启发,本申请尝试在融合任务中使用更丰富的卷积特性。与从vgg16网络结构最后的完全连接层提取的特征相比,更丰富的卷积特性提供了更丰富的特征表示。因为多层卷积层保留了更加完整的信息,比如被高层丢失的局部纹理和细节信息。
提取vgg16网络的第三、第四和第五特征图,然后使用全局平均池化操作将原来的56*56*256、28*28*512和14*14*512压缩成1*256、1*512和1*512。最后将这三个向量拼接成一个1280*(512+512+256)维向量,作为病理图像更丰富的特征表示。具体的融合过程如图2所示。
步骤4:在医院的实际应用场景中,丢失的数据不仅是单一模式的完全丢失,而且是单一模式下一小部分数据的丢失。因此,有必要针对更细粒度的数据丢失情况提出新的方法。为了提高数据融合的有效性和方法的泛化能力。我们提出在训练中随机“丢弃”部分结构化数据。该策略使得我们的方法能够在缺少部分结构化数据的情况下进行准确预测。此策略对于模型的鲁棒性非常有效。具体地说,将丢弃率定义为在整个网络训练阶段删除部分结构化数据的概率。实验结果表明,针对部分缺失数据的训练方法不仅可以减轻缺失数据的影响,而且会给整个算法模型带来降低过拟合风险的“副作用”。
步骤5:在提取出病理图像的丰富的特征表示后,可以将不同模式的数据进行融合。与病理图像的1280维的特征表示相比,emr中提取的代表性特征只有29个,即一个29维向量。如果我们直接把它们拼接,29维的向量会完全被1280维的向量淹没。以前的方法是将高维图像数据的特征表示先降维,然后再和低维的数据融合。然而,这样的方法在不同模式融合之前就产生了大量的信息丢失,使得信息融合不充分。
相反,将低维向量按一定比例扩增,这样它就与高维数据具有相同大小的数量级。特别是在重复10次、15次、20次、25次、30次的情况下进行实验,我们发现,将一个29维的向量复制20次,效果最好。然后将病理图像中提取的1280维向量与之拼接,形成1860维向量。然后这个1860维的向量经过接下来的三个完整的连接层,得到良性和恶性乳腺癌的分类结果。其中,三个完整的全连接层分别有500,100和2个节点。
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
本发明还提出了一种基于多模态深度学习的病理分类系统,其中包括:
模块1、从电子病历中提取出预先选择的属性作为结构化数据的特征表示向量,将该特征表示向量平均扩增后再按照预设比例随机丢弃,丢弃的部分被替换为数字0,作为电子病历中结构化数据的病历特征向量;
模块2、获取与该电子病历对应的组织病理学图像,将卷积神经网络的各卷积层的特征图进行全局平均池化后拼接成一维向量,作为该组织病理学图像的一种丰富的图像特征向量;
模块3、将该图像特征向量和该病历特征向量拼接在一起,得到多模态融合向量,然后将该多模态融合向量输入至全连接层,得到二值化的病理分类结果。
所述的基于多模态深度学习的病理分类系统,其中该模块1包括:从该电子病历中提取出29个在医学理论上与乳腺癌的诊断密切相关的属性组成特征向量,再把从临床电子病历中提取的29维向量平均扩增一预设比例,然后按照一预设百分比随机丢弃,丢弃的部分被替换为数字0。
所述的基于多模态深度学习的病理分类系统,其中该模块2包括:利用卷积神经网络的第三、第四和第五层卷积层,提取得到第三、第四和第五卷积层的特征图,然后使用全局平均池化操作将第三、第四和第五卷积层的特征图进行压缩后,拼接成该组织病理图像的特征表示向量。
所述的基于多模态深度学习的病理分类系统,其中模块3中该全连接层为三个完整的连接层,分别有500,100和2个节点。
- 还没有人留言评论。精彩留言会获得点赞!