数据匹配方法及装置、存储介质、终端与流程
本发明涉及数据处理技术领域,尤其涉及一种数据匹配方法及装置、存储介质、终端。
背景技术:
在数据交易和数据流通过程中,数据交易平台通常需要对数据需方所需数据和数据供方所提供的数据之间进行数据匹配。具体地,有典型的两种场景需要进行数据匹配:一种场景为数据需方将希望查询的数据标识(identity,id)发送给数据供方前置机,数据供方前置机收到id文件后与自己的存量id进行数据匹配;另一种场景为数据需方向数据供方发送查询请求,数据供方根据需方请求返回指定条数的数据记录,数据需方前置机收到数据供方返回的数据后与自己的存量id进行数据匹配。
这两种场景下数据匹配都发生在数据供方或数据需方的前置机上,该前置机通常为一个单机环境。
但是,在单机环境下进行数据匹配时,由于需要进行数据的全量匹配,数据匹配效率低;并且,现有的数据匹配依赖关系数据库,关系数据库存储上限约为十几万张表数亿条记录,当数据量达到或者接近该存储上限时,关系数据库的读写速度会显著下降,除了开源的mysql以外,oracle等商业数据库还有成本高,使用困难等缺点,使用关系数据库执行数据匹配的性能低下。
技术实现要素:
本发明解决的技术问题是如何提升数据匹配的效率。
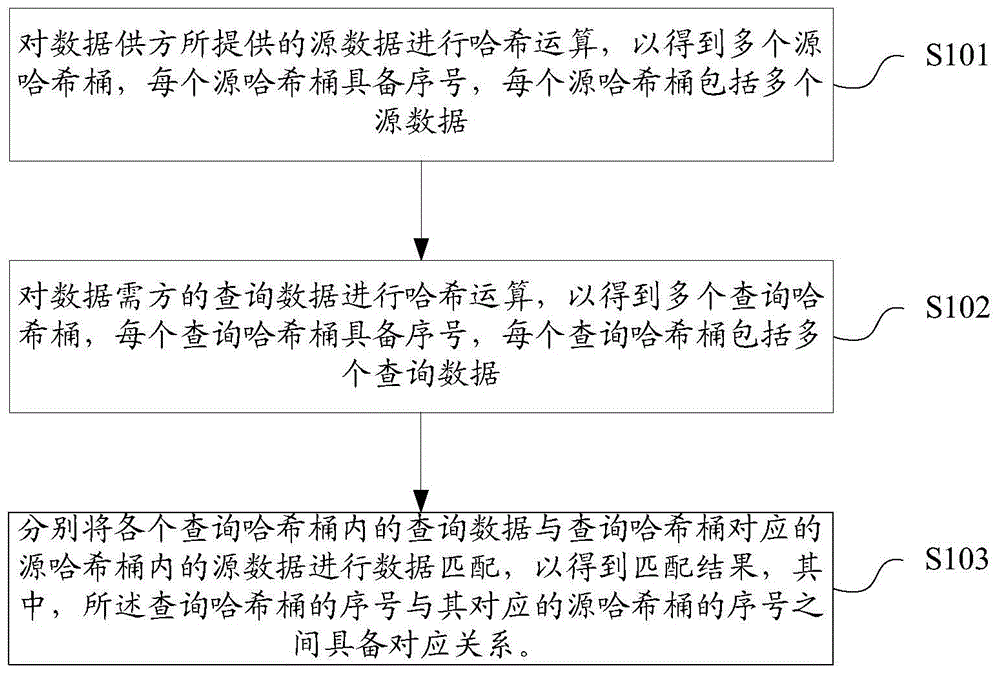
为解决上述技术问题,本发明实施例提供一种数据匹配方法,数据匹配方法包括:对数据供方所提供的源数据进行哈希运算,以得到多个源哈希桶,每个源哈希桶具备序号,每个源哈希桶包括多个源数据;对数据需方的查询数据进行哈希运算,以得到多个查询哈希桶,每个查询哈希桶具备序号,每个查询哈希桶包括多个查询数据;分别将各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配,以得到匹配结果,其中,所述查询哈希桶的序号与其对应的源哈希桶的序号之间具备对应关系。
可选的,所述分别将各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配包括:分别将各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配,以得到多个桶匹配结果;将所述多个桶匹配结果进行合并,以得到所述匹配结果。
可选的,所述分别将各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配包括:采用多个进程分别将各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配。
可选的,所述对数据供方所提供的源数据进行哈希运算之前还包括:接收来自所述数据供方的源数据;所述对数据需方的查询数据进行哈希运算包括:从所述数据需方的服务器获取所述查询数据,并对所述查询数据进行哈希运算。
可选的,所述对数据供方所提供的源数据进行哈希运算之前还包括:接收来自所述数据需方的查询数据;所述对数据供方所提供的源数据进行哈希运算包括:从所述数据供方的服务器获取所述源数据,并对所述源数据进行哈希运算。
可选的,所述多个源哈希桶的数量与所述多个查询哈希桶的数量相同。
可选的,所述数据匹配方法还包括:对所述匹配结果进行统计分析,以得到各个查询哈希桶内的查询数据与其对应的源哈希桶内的源数据的匹配分布。
为解决上述技术问题,本发明实施例还公开了一种数据匹配装置,数据匹配装置包括:第一哈希模块,用以对数据供方所提供的源数据进行哈希运算,以得到多个源哈希桶,每个源哈希桶具备序号,每个源哈希桶包括多个源数据;第二哈希模块,用以对数据需方的查询数据进行哈希运算,以得到多个查询哈希桶,每个查询哈希桶具备序号,每个查询哈希桶包括多个查询数据;数据匹配模块,用以分别将各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配,以得到匹配结果,其中,所述查询哈希桶的序号与其对应的源哈希桶的序号之间具备对应关系。
本发明实施例还公开了一种存储介质,其上存储有计算机指令,所述计算机指令运行时执行所述数据匹配方法的步骤。
本发明实施例还公开了一种终端,包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机指令,所述处理器运行所述计算机指令时执行所述数据匹配方法的步骤。
与现有技术相比,本发明实施例的技术方案具有以下有益效果:
本发明技术方案通过对数据供方提供的源数据以及数据需方的查询数据进行哈希运算,可以分别将源数据以及查询数据按照其数据特征划分至源哈希桶以及查询哈希桶。由于具备相同数据特征的源数据和查询数据被分配的哈希桶的序号相对应,因此可以仅对查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配,避免了数据的全量匹配,提高了数据匹配的效率。
进一步地,采用多个进程分别将各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配。本发明技术方案中,每个进程可以负责一对查询哈希桶与源哈希桶内数据的匹配,而多个进程之间是可以并行处理的,因此,多个进程负责的多对查询哈希桶与源哈希桶内数据的匹配可以同时进行,进一步提升数据匹配的效率。
附图说明
图1是本发明实施例一种数据匹配方法的流程图;
图2是本发明实施例另一种数据匹配方法的流程图;
图3是本发明实施例又一种数据匹配方法的流程图;
图4是本发明实施例一种数据匹配装置的结构示意图。
具体实施方式
如背景技术中所述,在单机环境下进行数据匹配时,由于需要进行数据的全量匹配,数据匹配效率低;并且,现有的数据匹配依赖关系数据库,关系数据库存储上限约为十几万张表数亿条记录,当数据量达到或者接近该存储上限时,关系数据库的读写速度会显著下降,除了开源的mysql以外,oracle等商业数据库还有成本高,使用困难等缺点,使用关系数据库执行数据匹配的性能低下。
本发明技术方案通过对数据供方提供的源数据以及数据需方的查询数据进行哈希运算,可以分别将源数据以及查询数据按照其数据特征划分至源哈希桶以及查询哈希桶。由于具备相同数据特征的源数据和查询数据被分配的哈希桶的序号相对应,因此可以仅对查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配,避免了数据的全量匹配,提高了数据匹配的效率。
为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
图1是本发明实施例一种数据匹配方法的流程图。
本实施例所示的数据匹配方法可以由数据供方的前置机来执行,也可以由数据需方的前置机来执行,或者也可以由数据交易中心来执行。
本实施例中,数据供方是指交易系统的数据提供方;数据需方是指交易系统中的数据需求方;前置机是指数据供方或数据需方与数据交易中心协商好的服务器。
图1所示数据匹配方法可以包括以下步骤:
步骤s101:对数据供方所提供的源数据进行哈希运算,以得到多个源哈希桶,每个源哈希桶具备序号,每个源哈希桶包括多个源数据;
步骤s102:对数据需方的查询数据进行哈希运算,以得到多个查询哈希桶,每个查询哈希桶具备序号,每个查询哈希桶包括多个查询数据;
步骤s103:分别将各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配,以得到匹配结果,其中,所述查询哈希桶的序号与其对应的源哈希桶的序号之间具备对应关系。
需要指出的是,本实施例中各个步骤的序号并不代表对各个步骤的执行顺序的限定。
在步骤s101的具体实施中,可以对数据供方提供的源数据进行哈希运算。具体地,源数据可以包括源数据id以及标签数据等,源数据id可以是源数据的标识,标签数据可以是源数据的数据内容;具体可以是对源数据id进行哈希运算。
对源数据进行哈希运算的过程可以是对源数据进行数据分片的过程。也就是说,将各个源数据分别划分至多个源哈希桶中。源哈希桶的数量可以是预先配置的,例如可以是64、12等,本发明实施例对此不作限制。
具体实施中,可以通过对源数据id执行哈希算法计算得到源数据id对应的固定长度的序列号,通过对该序列号执行取余运算,可以获得该源数据被分配的源哈希桶的序号。例如,源哈希桶的数量为64时,可以对源数据id的序列号执行对64的取余运算。
在将源数据分配至多个源哈希桶时,可能出现至少一个源哈希桶中数据量为0的情况。
与前述步骤s101不同的是,在步骤s102中,执行哈希运算的对象是数据需方的查询数据。具体而言,查询数据也可以包括查询数据id以及标签数据。具体可以是对查询数据id执行哈希运算。
具体实施中,可以通过对查询数据id执行哈希算法计算得到查询数据id对应的固定长度的序列号,通过对该序列号执行取余运算,可以获得该查询数据被分配的查询哈希桶的序号。例如,查询哈希桶的数量为64时,可以对查询数据id的序列号执行对64的取余运算。
关于对查询数据执行哈希运算得到多个查询哈希桶的具体过程可参照步骤s101的具体实施例,本发明对此不作限制。
需要说明的是,为了保证后续数据匹配的准确性,源哈希桶的总数量与查询哈希桶的总数量相同。此外,对源数据进行哈希运算以及对查询数据进行哈希运算所采用的哈希算法是相同的。
在一个具体实施例中,确定源哈希桶和查询哈希桶的数量,例如均为16个,分别对源数据和查询数据执行哈希算法,再对哈希结果执行取余运算,例如对哈希结果针对16进行取余,以分别得到源数据被分配的源哈希桶的序号和查询数据被分配的查询哈希桶的序号。
在步骤s103的具体实施中,可以分别对各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配。
本实施例中,具备相同数据特征的源数据和查询数据被分配的哈希桶的序号相对应,例如序号相同,或者序号之间具备预设的对应关系,因此可以仅对查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配,避免了数据的全量匹配,提高了数据匹配的效率。
例如,对于序号为000的查询哈希桶和源哈希桶,可以将两者内的数据进行数据匹配;对于序号为001的查询哈希桶和源哈希桶,可以将两者内的数据进行数据匹配,以此类推,对于序号为063的查询哈希桶和源哈希桶,可以将两者内的数据进行数据匹配。
可以理解的是,关于数据匹配的过程可以是对数据进行比对的过程,如果源数据与查询数据一致,则可以确定该源数据与该查询数据相匹配。
在本发明一个具体应用场景中,对数据供方或数据需方的存量id进行数据分片时,为防止每个哈希桶内的数据量太大,可以根据存量id总数据量的大小动态控制哈希桶的个数。存量id的大小在50g-200g左右,可以选取每个哈希桶的容量大小为1g-2g,哈希桶的数量在100左右。根据这样的标准,每个哈希桶内的数据量既不会太大造成单个数据分片匹配数据过慢,也保证哈希桶内的数据量不能太小造成哈希桶数过多,导致产生过多进程数,使数据匹配进程太多,影响匹配效率。
本发明一个优选实施例中,可以选取xxhash算法对源数据以及查询数据进行哈希运算。其中,xxhash算法可以满足随机性的要求,也可以满足计算速度的要求。
在本发明一个具体实施例中,图1所示步骤s103可以包括以下步骤:分别将各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配,以得到多个桶匹配结果;将所述多个桶匹配结果进行合并,以得到所述匹配结果。
本实施例中,由于每对查询哈希桶与源哈希桶的数据匹配是独立进行的,因此可以分别得到多个独立的桶匹配结果。其中,桶匹配结果的数量与查询哈希桶(或者源哈希桶)的数量相同。
进一步而言,多个桶匹配结果可以分别保存在不同的文件中。
为了方便匹配结果的查看,可以将多个桶匹配结果进行合并。合并的具体方式可以是将多个桶匹配结果所在的文件合并为一个汇总文件。或者,也可以通过递归合并的方式依次将两个桶匹配结果所在的文件汇总成一个更大的文件,直至最终生成一个汇总文件。
在本发明一个具体实施例中,图1所示步骤s103可以包括以下步骤:采用多个进程分别将各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配。
具体实施中,如果采用单进程对多对查询哈希桶和源哈希桶内的数据进行匹配的速度往往不能满足实时性的需求,由此,可以采用多进程对每对查询哈希桶和源哈希桶内的数据进行单独匹配,每个进程之间不共享数据。
本实施例中,每个进程可以负责一对查询哈希桶与源哈希桶内数据的匹配,而多个进程之间是可以并行处理的,因此,多个进程负责的多对查询哈希桶与源哈希桶内数据的匹配可以同时进行,进一步提升数据匹配的效率。
请参照图2,与图1所示实施例不同的是,在步骤s101之前还可以包括以下步骤:步骤s201:接收来自所述数据供方的源数据;
步骤s102可以包括以下步骤:步骤s202:从所述数据需方的服务器获取所述查询数据,并对所述查询数据进行哈希运算。
本发明实施例的数据匹配方法可以由数据需方的前置机来执行。
具体实施中,数据需方的前置机可以预先将查询数据执行哈希运算。数据供方将源数据发送给数据需方的前置机。数据需方的前置机可以接收来自数据供方的源数据,并逐条对源数据执行哈希运算,将哈希运算后的源数据放入源哈希桶中,以用于在步骤s103中进行数据匹配。
具体地,源数据可以包括源数据id与标签数据,数据需方可以对源数据id进行哈希运算。
需要说明的是,源数据除了包括源数据id与标签数据之外,还可以包括其他任意可实施的类型的数据;同理,查询数据除了包括查询数据id与标签数据之外,也可以包括其他任意可实施的类型的数据,本发明实施例对此不作限制。
请参照图3,与图1所示实施例不同的是,在步骤s101之前还可以包括以下步骤:步骤s301:接收来自所述数据需方的查询数据;
步骤s101可以包括以下步骤:步骤s302:从所述数据供方的服务器获取所述源数据,并对所述源数据进行哈希运算。
本发明实施例的数据匹配方法可以由数据供方的前置机来执行。
具体实施中,数据供方的前置机可以预先将源数据执行哈希运算。数据需方将查询数据发送给数据供方的前置机。数据供方的前置机可以接收来自数据需方的查询数据,并逐条对查询数据执行哈希运算,将哈希运算后的查询数据放入查询哈希桶中,以用于在步骤s103中进行数据匹配。
在本发明一个具体实施例中,图1所示数据匹配方法还可以包括以下步骤:对所述匹配结果进行统计分析,以得到各个查询哈希桶内的查询数据与其对应的源哈希桶内的源数据的匹配分布。
具体实施中,对所述匹配结果进行统计分析可以是对每对源哈希桶和查询哈希桶内的相匹配的数据量以及匹配完成所花费的时间等进行统计。
进一步而言,还可以将统计分析的结果以可视化的方式进行展示。
通过对源哈希桶和查询哈希桶内的匹配结果以及时间进行统计,可以得到所有数据分片的匹配分布情况,通过匹配结果的分析,可以对每对数据分片的匹配结果有直观的感受。进而能够根据通过可视化的结果,对哈希桶的分配策略进行优化。
请参照图4,本发明实施例还公开了一种数据匹配装置。数据匹配装置40可以包括第一哈希模块401、第二哈希模块402和数据匹配模块403。
其中,第一哈希模块401用以对数据供方所提供的源数据进行哈希运算,以得到多个源哈希桶,每个源哈希桶具备序号,每个源哈希桶包括多个源数据;第二哈希模块402用以对数据需方的查询数据进行哈希运算,以得到多个查询哈希桶,每个查询哈希桶具备序号,每个查询哈希桶包括多个查询数据;数据匹配模块403用以分别将各个查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配,以得到匹配结果,其中,所述查询哈希桶的序号与其对应的源哈希桶的序号之间具备对应关系。
本发明实施例通过对数据供方提供的源数据以及数据需方的查询数据进行哈希运算,可以分别将源数据以及查询数据按照其数据特征划分至源哈希桶以及查询哈希桶。由于具备相同数据特征的源数据和查询数据被分配的哈希桶的序号相对应,因此可以仅对查询哈希桶内的查询数据与查询哈希桶对应的源哈希桶内的源数据进行数据匹配,避免了数据的全量匹配,提高了数据匹配的效率。
关于所述数据匹配装置40的工作原理、工作方式的更多内容,可以参照图1至图3中的相关描述,这里不再赘述。
本发明实施例还公开了一种存储介质,其上存储有计算机指令,所述计算机指令运行时可以执行图1、图2或图3中所示方法的步骤。所述存储介质可以包括rom、ram、磁盘或光盘等。所述存储介质还可以包括非挥发性存储器(non-volatile)或者非瞬态(non-transitory)存储器等。
本发明实施例还公开了一种终端,所述终端可以包括存储器和处理器,所述存储器上存储有可在所述处理器上运行的计算机指令。所述处理器运行所述计算机指令时可以执行图1、图2或图3中所示方法的步骤。所述终端包括但不限于手机、计算机、平板电脑等终端设备。
虽然本发明披露如上,但本发明并非限定于此。任何本领域技术人员,在不脱离本发明的精神和范围内,均可作各种更动与修改,因此本发明的保护范围应当以权利要求所限定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!