一种基于条件生成对抗网络的图像描述生成方法与流程
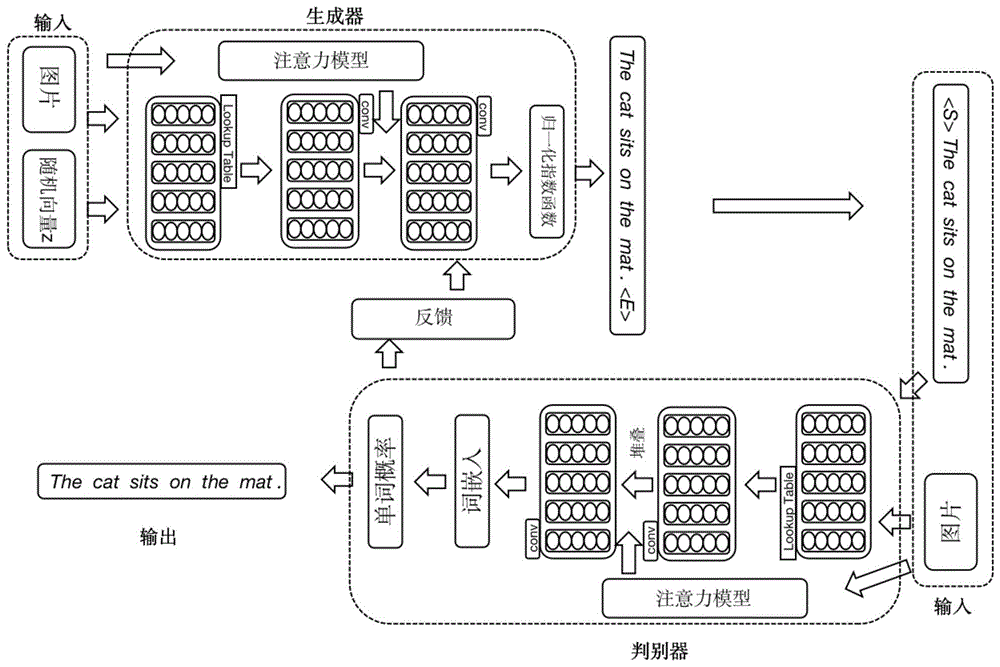
本发明涉及计算机视觉领域的多媒体大数据处理与分析,特别涉及一种条件生成对抗的图片描述生成方法,跨越了计算机视觉和自然语言处理两个领域。
背景技术:
随着网络共享技术的发展,网络上有越来越多的图片能够被实时分享和接收。如何用机器来理解图像所表示的内容,并将其输出为一个语句连贯、语义正确的句子成为一个重点研究问题。近些年随着深度学习方法的快速发展,得益于深度特征对图像内容的精确表达,使用机器来自动生成描述取得了重大进展。但是这些方法在训练过程中存在梯度消失和图片特征在网络中有损失,生成的描述在语义丰富程度和内容准确性上依然存在缺陷,无法得到很好的效果。
技术实现要素:
为了克服已有的图片描述生成技术的对训练数据要求高、生成描述单调、描述不够真实等不足,本发明提供一种鲁棒性较好、对训练数据要求较低的基于条件生成对抗训练的图像描述生成方法。
本发明解决其技术问题所采用的技术方案是:
一种基于条件生成对抗网络的图像描述生成方法,所述方法包括以下步骤:
步骤一、网络构建,过程如下:
步骤1.1:该条件生成对抗网络框架由一个生成模型和一个判别模型两部分组成,生成模型和判别模型结构类似,但是参数独立训练更新;
步骤1.2:生成模型的第一层为嵌入层,输出一个三维特征向量;
步骤1.3:生成模型的嵌入层后接一个全连接层;
步骤1.4:生成模型的第三层为一个全连接层;
步骤1.5:生成模型的第三个全连接层后接relu激活函数
步骤1.6:生成模型后接一个glu模块,包含三层卷积层;
步骤1.7:生成模型经过三层卷积层后通过一个全连接层;
步骤1.8:生成模型再经过最后一个全连接层将维度扩展;
步骤1.9:将生成模型的输出结果作为判别模型的输入;
步骤1.10:判别模型的第一层为嵌入层,把输入维度扩展;
步骤1.11:判别模型的嵌入层后接一个全连接层,输出一个三维特征向量;
步骤1.12:判别模型的第三层为一个全连接层;
步骤1.13:判别模型的第三个全连接层后接relu激活函数
步骤1.14:判别模型后接一个glu模块,包含三层卷积层;
步骤1.15:判别模型经过三层卷积层后通过一个全连接层;
步骤1.16:判别模型再经过最后一个全连接层改变输出维度;
步骤1.17:判别模型把计算出的描述句子相似性得分反馈到生成模型中;
步骤二、数据集预处理;
步骤三、网络训练,过程如下:
步骤3.1:用随机权值初始化生成模型和判别模型参数;
步骤3.2:训练生成模型;
步骤3.3:训练判别模型;
步骤3.4:用rmsprop下降算法最小化损失函数;
步骤四、精度测试,过程如下:
步骤4.1:将预处理好的测试数据集送入最优生成器模型;
步骤4.2:生成器针对给定的图片,通过生成模型生成对应的描述语句;
步骤4.3:比较问询图片的真实描述语句和生成器返回的描述语句的相关度,根据图像描述中的评价准则计算所有问询图片生成的描述语句;
步骤4.4:在测试数据上进行验证,生成测试图片的描述语句;
经过上述步骤的操作,即可实现对测试图片的描述生成。
进一步,所述步骤二中,数据预处理的过程如下:
步骤2.1:数据集中数据包含训练图片和图片的描述句子两部分,将图片提取特征输入到网络中;
步骤2.2:用在imagenet上预训练好的vgg模型来提取图片特征;
步骤2.3:将图片以特征向量的形式输入对抗网络中。
再进一步,所述步骤3.2中,训练生成模型的过程如下:
步骤3.2.1:对于生成模型,不给他输入真实的句子描述,将一个与真实描述同纬度的随机噪声向量作为句子描述输入生成模型;
步骤3.2.2:将vgg网络提取出来的图片特征和随机向量送入一起生成模型;
步骤3.2.3:生成模型对输入的句子描述经过嵌入层和全连接层获得句子特征向量;
步骤3.2.4:将提取出来的图片特征经过全连接层和嵌入层,转换为与句子特征向量同维度;
步骤3.2.5:将句子特征和图片特征进行拼接,共同输入到glu模块训练;
步骤3.2.6:将得到的向量通过两个全连接层得到生成句子描述特征向量;
步骤3.2.7:利用归一化指数函数将相似度转换为单词被选中的概率,生成描述语句。
更进一步,所述步骤3.3中,训练判别模型的过程如下:
步骤3.3.1:将生成器生成的描述句子和该图片特征作为判别器输入;
步骤3.3.2:判别模型对输入的句子描述经过嵌入层和全连接层获得句子特征向量;
步骤3.3.3:将句子特征和图片特征拼接,共同输入到glu模块;
步骤3.3.4:将得到的向量通过两个全连接层得到生成句子描述特征向量;
步骤3.3.5:利用归一化指数函数将相似度转换为单词被选中的概率,生成描述语句;
步骤3.3.6:计算生成的句子描述和真实句子描述的真实性比较,得到一个句子得分,反馈给生成模型,作用于接下来生成模型对描述的生成。
本发明的有益效果主要表现在:本发明提出一种基于条件生成对抗的图像描述生成方法。在输入一张图片,并不给出该图片描述的情况下,生成模型和判别模型通过最大化最小化对抗训练来提高双方的性能:生成模型能够生成该图片的描述句子,判别模型能够最大程度的判断生成器输出的描述句子与真实句子描述是否相似。该方法解决了深度学习中面临的训练过程中需要大量有标注信息的问题,同时也是条件生成对抗网络在生成图像描述任务中的一次成功实现。
附图说明
图1是本发明用到的基于生成对抗网络的图像描述生成模型框架示意图。
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1,一种基于条件生成对抗网络的图像描述生成方法,所述方法包括条件生成对抗训练网络的构建、数据集预处理、网络训练和评价指标测试四个过程。
本实施案例中的图片来自mscoco数据集,包含训练集,验证集和测试集。在训练集上训练模型,并在测试集和验证集上验证训练结果。基于条件生成对抗网络的图像描述生成方法框架如图1所示,操作步骤包括网络的构建、数据集预处理、网络训练和图片检索测试四个过程。
所述基于条件生成对抗网络的图像描述生成方法包括以下步骤:
步骤一、网络构建,过程如下:
步骤1.1:该条件生成对抗网络框架由一个生成模型和一个判别模型两部分组成,生成模型和判别模型结构类似,但是参数独立更新;
步骤1.2:生成模型的第一层为嵌入层,神经元个数设为512,权值为w_1,定义为浮点型变量,无偏置;
步骤1.3:生成模型的第二层为全连接层,神经元个数设为512,权值为w_2,定义为浮点型变量,无偏置;
步骤1.4:生成模型的第三层为全连接层,神经元个数为512,权值为w_3,定义为浮点型变量,无偏置,后接relu激活函数;
步骤1.5:生成模型的第三层后接一个glu模块,该模块含三层卷积层,神经元个数为512,权值为w_4,卷积核大小为5,步长为1,零填充设置为2,定义为浮点型变量,无偏置;
步骤1.6:生成模型的卷积层后接一个全连接层,神经元个数为256,权值为w_5,定义为浮点型变量,无偏置;
步骤1.7:生成模型s的最后一层为全连接层,神经元个数为9221,权值为w_6,定义为浮点型变量,无偏置;
步骤1.8:判别模型的第一层为嵌入层,神经元个数设为512,权值为w_7,定义为浮点型变量,无偏置;
步骤1.9:判别模型的第二层为全连接层,神经元个数设为512,权值为w_8,定义为浮点型变量,无偏置;
步骤1.10:判别模型的第三层为全连接层,神经元个数为512,权值为w_9,定义为浮点型变量,无偏置,后接relu激活函数;
步骤1.11:判别模型的第三层后接一个glu模块,该模块含三层卷积层,神经元个数为512,权值为w_10,卷积核大小为5,步长为1,零填充设置为2,定义为浮点型变量,无偏置;
步骤1.12:判别模型的卷积层后接一个全连接层,神经元个数为256,权值为w_11,定义为浮点型变量,无偏置;
步骤1.13:判别模型的最后一层为全连接层,神经元个数为9221,权值为w_12,定义为浮点型变量,无偏置;
步骤1.14:判别模型把计算出的生成描述句子与真实句子相似性得分以生成器损失函数权值的形式反馈到生成模型中;
步骤二、数据集预处理,过程如下:
步骤2.1:数据被分为训练集113287张图片,测试集5000张图片和验证集500张图片三部分,对数据进行预处理,将数据集中的句子单词都转换成小写字母,丢弃掉非字母数字字符;
步骤2.2:用在imagenet上预训练好的vgg模型,设定输出图片特征维度为4096维;
步骤2.3:用微调好的vgg网络模型提取训练集图片对应的特征向量,并将特征值再经过一个全连接层和一个嵌入层;
步骤三、网络训练,过程如下:
步骤3.1:用随机权值初始化生成模型和判别模型中的参数;为模型设置30个循环迭代,每次迭代完成后保存模型参数;
步骤3.2:训练生成模型;
步骤3.2.1:设定学习率为0.00005,经过15个循环学习率降低为原来的10%;
步骤3.2.2:将与图片描述句子相同维度的随机向量作为作为生成模型的句子输入送入到网络中;
步骤3.2.3:将提取的图片特征经过一个全连接层和嵌入层改变特征维度作为生成模型的图片输入,送入到网络中;
步骤3.2.4:确保图片特征向量的维度与经过第一个嵌入层后的句子特征向量维度相同,将两者拼接共同输入网络进行训练;
步骤3.2.5:生成模型利用三层glu模块对输入图像和句子进行训练,针对每一张图片,生成模型对其生成描述语句,利用归一化指数函数将单词概率相似度转换为单词被选中的概率,根据概率大小从数据集中选择相概率高最高的单词,作为生成器的输出;
步骤3.3:训练判别模型;
步骤3.3.1:设定学习率为0.00005,经过15个循环学习率降低为原来的10%;
步骤3.3.2:将生成器返回的描述句子作为判别器的输入,并将该描述句子代表的图片一同输入到判别器中;
步骤3.3.3:将描述句子经过一个嵌入层改变维度,然后与图片特征拼接共同输入到判别模型;
步骤3.3.4:判别模型利用三层glu模块对输入图像和句子进行训练,针对每一张图片,生成模型对其生成描述语句,利用归一化指数函数将单词概率相似度转换为单词被选中的概率,根据概率大小从数据集中选择相概率高最高的单词;
步骤3.3.5:将生成的描述语句与真实描述语句进行相关性评估,计算句子的得分,将判别器计算出的相似性得分反馈到生成器中,以损失函数权值形式直接作用于生成器的权值的优化;
步骤3.4:保存最优的生成器模型作为训练的输出;
步骤四、精度测试,过程如下:
步骤4.1:将预处理好的测试数据集图片送入最优生成器模型中;
步骤4.2:生成器针对给定的问询图片,对该图片生成描述语句;
步骤4.3:比较问询图片的真实描述语句和生成器返回的描述语句的相关度,根据图像描述中的评价准则计算所有问讯图片生成的描述语句;
步骤4.4:在测试数据上进行验证,生成测试图片的描述语句;
经过上述步骤的操作,即可实现对图片生成描述语句。
以上所述的具体描述,对发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施例,用于解释本发明,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!