基于真实人脸图像的虚拟面部建模方法与流程
本发明涉及三维建模技术领域,特别涉及一种基于真实人脸图像的虚拟面部建模方法。
背景技术:
随着科技的不断发展,人们对于生活质量有着更高的追求,交流型机器人的出现让人们眼前一亮。而vr技术的兴起,则使其更具体验感与科技感,体验者在佩戴vr设备后,能够在计算机生成的模拟环境中,与虚拟机器人亲切互动。虚拟机器人的未来市场已经开始向主持行业,迎宾行业等渗透,预计在不久的将来,虚拟机器人将广泛的应用于各类服务业当中。
unity3d是使用最为广泛的支撑虚拟交互的平台,为了使交互更真实,导入unity3d中的人物模型的仿人性能也成为人们关注的一个重点。而其中最关键的则是面部建模,只有3d模型对真实人物面部的还原度高,辨识度高,才能使体验者在虚拟交互过程中具有沉溺感和满足感。
目前,各类3d人物模型的面部建模都是通过3dsmax,zbrush等建模软件完成,所建立人物模型的面部与真人的面部相差度较高,并且建模存在耗用时间长,成本高等问题。
技术实现要素:
有鉴于此,本发明的目的是提供一种基于真实人脸图像的虚拟面部建模方法,以解决现有技术中采用3d软件建立虚拟人物头部模型的面部,存在所建虚拟面部与真人的面部相差度较高、建模耗时长等技术问题。
本发明基于真实人脸图像的虚拟面部建模方法,包括以下步骤:
一)制作头部模型,其又包括如下步骤:
a)采集真人面部的正面照片,利用insight3d将真人面部的正面照片转换为3d头部模型;
b)在insight3d中将3d头部模型的人面部分与3d头部模型的其余部分分离,并将分离出的人面部分进行平滑化,做成椭球面;
二)制作面部表情动作贴图集,具体操作步骤如下:
1)拍摄与虚拟人物所需面部表情相应的真人面部表情动作视频;
2)利用视频编辑软件,对表情动作视频进行逐帧截取,获取表情图片;
3)在insight3d中对步骤b)中分离出来的椭球面进行展uv操作,将三维面部模型转换为平面图片;
4)将步骤3)中获取的面部uv展开图导入到photoshop软件中,再将步骤2)中获取的某种表情动作视频的所有表情图片逐张贴合在面部uv展开图上,然后导出贴图,得到一种表情动作贴图集;
5)重复步骤4)得到虚拟人物所需面部表情的所有表情动作贴图集;
三)在unity3d中,使用unity3d自带的帧动画机将获得的各种表情动作贴图集制作成相应的表情动画;
四)制作表情动画控制器,具体步骤如下:
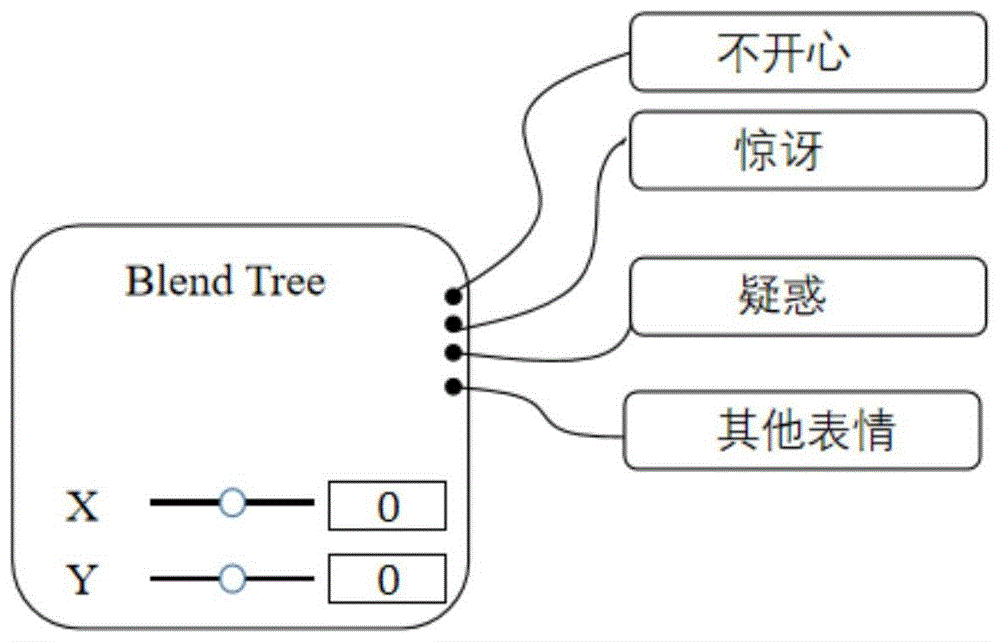
a)将步骤一)中制得的人面部分与其余部分相分离的3d头部模型导入到unity3d中,选中分离出来的椭球面状的面部模型,选择create添加animatorcontroller动画控制器;
b)在动画控制器中选择createstate中的子选项fromnewblendtree创建状态树,将状态树的状态blendtype改为2dfreeformdirectional,并将其parameters改为x和y;
c)在blendtree的motion中选择添加与制作好的表情动画数量相等的motion,并逐个导入表情动画;其中x,y为每个表情动画的坐标位置。
五)给3d头部模型装饰上头发配饰,对面部进行修饰。
六)编写脚本控制除面部以外的3d头部模型的位移,使其跟随面部位移做相对应的移动,具体步骤如下:
a)确定每个表情动画中各帧图片面部动作的大致角度,包括面部绕x轴的上下旋转角θk和面部绕y轴的左右旋转角
b)编写脚本,在脚本中定义两个容器,分别用于存放各帧图片面部动作的大致角度θk和
c)编写脚本控制除面部以外的3d头部模型旋转,使其旋转角度与表情动画中各帧图片面部动作角度θk和
本发明的有益效果:
本发明基于真实人脸图像的虚拟面部建模方法,其采用真实人的面部表情图像修饰所建立的3d虚拟头模的面部,使得所建立的虚拟人物头部模型的面部与真人的面部相识度极高;且建模过程不需要像现有采用3d软件建模时那样进行复杂的空间设计,建模耗时更短,成本更低。
附图说明
图1为表情状态blendtree结构图;
图2为3d头部模型以及将人面部分从3d头部模型中分离出来的示意图;
图3为椭球面状的人面部分其uv展开图;
图4为表情动作的连续帧贴图效果。
具体实施方式
下面结合附图和实施例对本发明作进一步描述。
本实施例基于真实人脸图像的虚拟面部建模方法,包括以下步骤:
一)制作头部模型,其又包括如下步骤:
a)采集真人面部的正面照片,利用insight3d将真人面部的正面照片转换为3d头部模型;
b)在insight3d中将3d头部模型的人面部分与3d头部模型的其余部分分离,并将分离出的人面部分进行平滑化,做成椭球面;本步骤在insight3d中的具体操作过程为:先选中头部模型,将模型转换为可编辑多边形,再选中头模面部部分,在编辑几何体的选项中选择分离选项,至此面部便于与头模其余部分分离;然后再选中面部部分,同样转换为可编辑多边形,并将其平滑化为椭球面状。
二)制作面部表情动作贴图集,具体操作步骤如下:
1)拍摄与虚拟人物所需面部表情相应的真人面部表情动作视频,如惊讶表情动作视频,大笑表情动作视频,说话表情动作视频等;
2)利用视频编辑软件,对表情动作视频进行逐帧截取,获取表情图片;本实施例中具体采用adobepremiere视频编辑软件获取表情图片,当然在不同实施例中还可采用其它现有的视频编辑软件;
3)在insight3d中对步骤b)中分离出来的椭球面进行展uv操作,将三维面部模型转换为平面图片;本步骤在insight3d中的具体操作过程为:选中面部模型,将其转换为可编辑多边形,然后在修改器列表中选择uvw展开;然后在“剥”选项中选择毛皮贴图,进而选择毛皮uv,开始松弛,直到将其松弛为平面图形,得到uv展开图并保存;
4)将步骤3)中获取的面部uv展开图导入到photoshop软件中,再将步骤2)中获取的某种表情动作视频的所有表情图片逐张贴合在面部uv展开图上,然后导出贴图,得到一种表情动作贴图集;
5)重复步骤4)得到虚拟人物所需面部表情的所有表情动作贴图集。
三)在unity3d中,使用unity3d自带的帧动画机将获得的各种表情动作贴图集制作成相应的表情动画。
四)制作表情动画控制器,具体步骤如下:
a)将步骤一)中制得的人面部分与其余部分相分离的3d头部模型导入到unity3d中,选中分离出来的椭球面状的面部模型,选择create添加animatorcontroller动画控制器;
b)在动画控制器中选择createstate中的子选项fromnewblendtree创建状态树,将状态树的状态blendtype改为2dfreeformdirectional,并将其parameters改为x和y;
c)在blendtree的motion中选择添加与制作好的表情动画数量相等的motion,并逐个导入表情动画;其中x,y为每个表情动画的坐标位置。例如,伤心表情动画坐标位置为(0,0),大笑表情动画为(0,1),当表情动画的坐标位置由(0,0)向(0,1)移动时,人物模型表情就会由伤心逐渐转变为大笑。
五)给3d头部模型装饰上头发配饰,对面部进行修饰。
六)编写脚本控制除面部以外的3d头部模型的位移,使其跟随面部位移做相对应的移动,具体步骤如下:
a)确定每个表情动画中各帧图片面部动作的大致角度,包括面部绕x轴的上下旋转角θk和面部绕y轴的左右旋转角
b)编写脚本,在脚本中定义两个容器,分别用于存放各帧图片面部动作的大致角度θk和
c)编写脚本控制除面部以外的3d头部模型旋转,使其旋转角度与表情动画中各帧图片面部动作角度θk和
在具体实施中,还可通过对虚拟人系统编写语音控制脚本实现用语音控制3d头部模型的面部表情,具体实现方式如下:
1)在unity3d控制脚本中定义一个语音录入插件audiorecorder,通过语音录入插件audiorecorder判断外置麦克风是否有语音输入给虚拟人系统;
2)当有语音输入虚拟人系统时,通过百度语音识别接口对输入的语音进行识别,将外部输入语音转换为文本值;
3)将步骤2)中获取的文本值传到百度理解与交互技术平台(unit),通过unit预置的自然语言理解功能,对传入的文本值进行处置,并返回相应的答复内容,返回内容格式仍为文本形式。
4)根据返回的文本内容来确定表情状态,并向动画控制器输出控制指令,动画控制器执行相应的表情动作。例如返回的文本内容中包含字符串“大笑”,那么语音控制脚本就会向动画控制器发出控制命令,动画控制器就播放已经制作好的“大笑”表情动画,虚拟人物面部相应做出“大笑”表情动作。
同时在具体实施中,还可通过对虚拟人系统编写控制脚本控制面部说话表情。具体实施方式为在控制脚本中定义一个unity3d自带的语音播放插件audiosource,外部输入语音经过上述1)、2)、3)步骤后,虚拟人系统会返回一个文本格式的答复内容,经过百度语音合成接口合成后,将此答复内容由文本形式转换为语音形式,并由audiosource控制播放,将audiosource的状态与虚拟人说话的表情动画绑定,当语音播放时,即当audiosource处于isplaying的状态时,动画控制器同时播放说话表情动画,虚拟人面部即产生说话表情变化。
本实施例基于真实人脸图像的虚拟面部建模方法,其采用真实人的面部表情图像修饰所建立的3d虚拟头模的面部,使得所建立的虚拟人物头部模型的面部与真人的面部相识度极高;且建模过程不需要像现有采用3d软件建模时那样进行复杂的空间设计,建模耗时更短,成本更低。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
- 还没有人留言评论。精彩留言会获得点赞!