一种基于策略价值网络和树搜索增强的命名实体识别方法与流程
本发明涉及信息处理领域,特别涉及一种基于策略价值网络和树搜索增强的命名实体识别方法。
背景技术:
命名实体识别应用非常广泛,主要方法可以分为基于统计的方法和基于神经网络的方法。前者例如最大熵马尔科夫模型(memm)和条件随机场(crf),这类方法大多需要耗费大量的人力去构建手工特征。后者是目前的主流方法,代表模型有双向长短期记忆网络(blstm)。为了进一步建模输出标签序列的全局性,解决标签偏置的问题,双向长短期记忆网络加条件随机场的模型(blstm+crf)取得了较好的效果。近年来,深度学习的发展大大增强了强化学习的表达能力,并且已经在游戏、围棋等方面取得了甚至超越人类的水平。本文将命名实体识别的标注过程建模为马尔科夫决策过程,提出了一种基于策略价值网络和树搜索增强的命名实体识别方法,称之为mm-ner。
技术实现要素:
为了解决现有的技术问题,本发明提供了一种基于策略价值网络和树搜索增强的命名实体识别方法,方案如下。
第一部分:对马尔科夫决策过程进行建模。
第二部分:设计策略价值网络。
步骤一:利用词向量将当前状态下的上下文进行表示,并依次输入门控循环单元和全连接层得到状态的语义表示。
步骤二:将步骤一的语义表示进行softmax操作,得到策略分布。
步骤三:将步骤一的语义和当前动作的one-hot表示在点乘后经过sigmoid函数得到当前状态下标注的期望评估值。
第三部分:在马尔科夫决策过程建模和策略价值网络的基础上,进行蒙特卡洛树搜索。
一次完整的树搜索主要包括以下三步:
步骤一:选择:从当前根节点开始,依次选择最优的子节点,直到达到叶子结点。
步骤二:评估和拓展:扩展叶子节点,从扩展出来的叶子结点中选择一个节点c开始,使用随机策略选择节点继续进行游戏。若游戏没有结束,则继续扩展叶子结点。
步骤三:回溯和更新:根据步骤二的结果更新从r到c的节点,例如访问次数。
附图说明
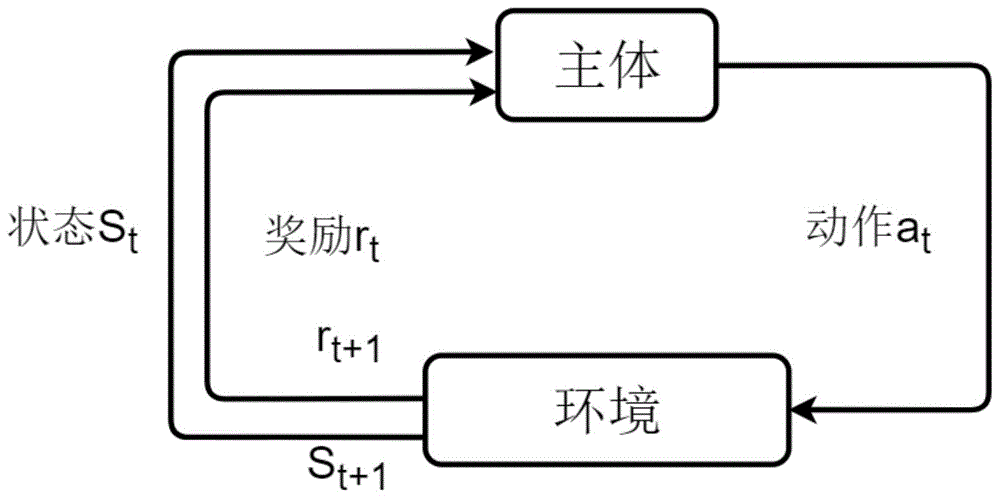
图1是本发明提供的马尔科夫决策过程示意图。
图2为gru内部结构图。
图3是本发明提供的蒙特卡洛树搜索示意图。
图4是本发明提出的基于策略价值网络的模型框架图
图5是本发明提供的模型损失函数示意图。
具体实施方式
接下来将对本发明的实施方案作更详细的描述。
首先介绍本发明的第一部分:马尔科夫决策过程建模。
强化学习是机器学习中另一个重要的学习范畴,主要通过主体以试错的机制来与环境进行交互,最终实现最大化累计奖励的目标。强化学习的马尔科夫决策过程主要包含五大要素:状态、动作、转移概率、奖励和衰减因子。图1给出了马尔科夫决策过程的示意图。假设x={x1,x2,…,xm}是需要标注的词序列,z={z1,z2,…,zm}对应是真实标签序列,其中m为序列的长度,马尔科夫决策过程的设计过程如下:
步骤s1:状态:定义t时刻的状态(s)为如下的三元组。
其中
步骤s2:在每个时刻t,
步骤s4:奖励:奖励函数设置为标签级别的f1值,与评价指标中基于实体级别的f1值有所不同。
步骤s5:衰减因子:本发明中令衰减因子为0。
接下来介绍本发明的第二部分:基于上述马尔科夫决策过程建模下的策略价值网络的设计。
步骤s1:将当前状态下的上下文进行词向量表示后依次输入门控循环单元和全连接层得到状态的语义表示。
步骤s2:将步骤二的语义表示进行softmax操作,得到策略分布。
步骤s3:类似地将步骤二的语义和当前动作的独热编码在进行点乘操作后经过sigmoid函数得到当前状态下标注的期望评估值。
下面对第二部分的每个步骤进行具体的说明:
步骤s1:单词向量化。本发明可以利用任意一种预训练好的词向量,建立词语到词向量编号的映射字典,将文本中各个词语映射为相应的词语编号。建立词向量矩阵,每一行行号对应相应的词语编号,每一行代表一个词向量。假设中文词语共有n个,那么词向量矩阵可以表示为一个n*d的矩阵,其中d表示词向量的维度,每一个词语都可以用一个d维的向量进行表示,即ei。拼接词向量得到句子表示。对于输入文本,假设该句话中一共有n个词语,每一个词语都由一个d维的向量表示,将该句中的所有词语的词向量拼接,可以得到编码器的输入矩阵,输入矩阵可以表示为x。
其中,xi表示文本中第i个单词的词向量,n表示文本长度即文本中词语个数,
在状态语义表示阶段,用一个门控循环单元编码文本信息,记为gru。循环神经网络可以很好的提取文本的上下文信息,循环神经网络可以关注到更长时间的依赖关系,更好的捕捉文章的整体信息。传统的循环神经网络会出现梯度消失及梯度爆炸的问题,而门控循环单元(gru)可以很好的解决这个问题。长短期记忆网络中利用输入门,更新门,重置门可以更有效的控制学习到长距离的依赖关系。
图2给出了gru的单元结构,时刻k时可以描述为:
zk=σ(wzxk+uzhk-1)(4)
rk=σ(wrxk+urhk-1)(5)
其中激活函数σ是sigmoid函数,更新门zk和重置门rk中的每个元素都在[0,1]中取值。
于是状态的语义表示为g(s):
g(s)=wgl(s)+bg(9)
步骤s2:将步骤s1的状态语义表示进行如下操作得到归一化的动作分布。
p(a|s)=softmax(upg(s))(10)
当
步骤s3:类似地,将步骤s1的状态语义表示和动作的one-hot表示在点乘后经过sigmoid函数得到当前状态下标注的期望评估值。
v(s)=σ(<wνg(s),at>)(12)
其中
下面对第三部分,利用策略价值网络进行蒙特卡洛树搜索的每个步骤进行具体的说明。其中模型框架图和蒙特卡洛树搜索示意图分别由图3和图4中所示。
在马尔科夫决策过程建模和策略价值网络的基础上,进行蒙特卡洛树搜索,蒙特卡洛树上的每个节点对应于mdp中的状态。算法的输入为当前的根节点sr,价值函数v和策略函数p。整个算法在迭代循环k次之后会为当前的根节点sr输出一个理论上更好的搜索策略π。令树上的每条边e(s,a)表示从状态s经过转移函数t(s,a)的过程,并且保存动作价值q(s,a),访问次数n(s,a)和策略网络输出的概率p(s,a)。在每一次迭代中,蒙特卡洛树搜索都会执行以下步骤:
步骤s1:选择:每次迭代都从根节点sr表示的状态开始,根据最大上限置信区间算法(ucb)依次选择最优的子节点,见公式(13),其中λ>0,为控制探索和利用的程度的参数:
而u的定义如下,u正比于策略网络的输出p(s,a),但反比与访问次数,目的就是为了鼓励主体去探索未了解的状态。
步骤s2:评估和拓展:在每一次遍历到叶子结点sl的时候,该节点(状态)会根据价值函数v(sl)(见公式(12))进行评估。模型使用价值函数v(sl)进行评估,而不是与环境进行rollout。紧接着,叶子结点sl会进行拓展,即从sl会拓展出可能的边,即根据公式(10)来初始化对应的每个候选动作a∈a(sl),并且令动作价值q(sl,a)=0,访问次数n(s,a)=0。在本文中,所有候选的动作(标签)都会进行拓展。
步骤s3:回溯和更新:在评估结束之后,遍历到的每一条边上的动作价值q(sl,a)和访问次数n(s,a)都会进行如下更新,同时保持策略网络输出的概率p(s,a)不变:
蒙特卡洛树搜索进行以上k次迭代之后,模型可以通过以下公式得到关于当前根节点sr的搜索策略π。
其中,n(sr,a)为从根节点sr开始的每一个边的访问次数。具体树搜索的伪代码如算法1:
对于x中的每一个位置,都利用策略函数p(a|s)和价值函数v(s)来进行蒙特卡洛树搜索,进而得到增强版的策略π。一个轨迹将在标完句子x的最后一个词之后结束,并且获得模型标注的序列(a0,a2,…,am-1)。将其与真实标注序列z对比,并计算标注准确度作为环境反馈给主体的奖励,记为r。r的取值可以是任何评价指标,例如准确度、精确度、召回率和f1值。本发明利用标签级别的f1值来作为奖励值。在每个时刻产生的数据
模型参数的优化通过随机梯度下降算法进行,优化器为adagrad。训练过程伪代码如算法2所示。
推断过程将根据算法3进行,其中推断过程的搜索次数可以与训练过程的搜索次数不相同,甚至为了保证时效性,可以采用argmax(p)或者argmax(v)进行推断。
以上结合附图对所提出的一种基于策略价值网络和树搜索增强的命名实体识别方法及各模块的具体实施方式进行了阐述。通过以上实施方式的描述,所属领域的一般技术人员可以清楚的了解到本发明可借助软件加必需的通用硬件平台的方式来实现。
依据本发明的思想,在具体实施方式及应用范围上均会有改变之处。综上所述,本说明书内容不应理解为对本发明的限制。
以上所述的本发明实施方式,并不构成对发明保护范围的限定。任何在本发明的精神和原则之内所作的修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!