一种基于知识图谱的信息资源查询推荐方法和系统与流程
本发明涉及知识图谱及推荐技术领域,具体涉及一种基于知识图谱的信息资源查询推荐方法和系统。
背景技术:
近年来,信息技术的蓬勃发展带动了各行各业信息化的步伐,互联网、物联网、云计算等等逐渐融入人们的日常生活中,由此带来的是爆炸式增长的数据。庞大的信息资源库为用户提供了丰富的信息的同时也带来了资源过载的问题,这使用户在检选感兴趣的信息资源上耗费大量时间。而根据用户的历史行为数据进行个性化查询推荐,可以有效缓解资源过载的问题。
推荐系统是当前应对信息过载的有效手段之一,它根据用户的历史行为分析用户的喜好,主动投其所好,例如用户在各种决策过程中购买哪种物品、阅读哪条新闻、听哪首音乐。
协同过滤算法是最早提出的,同时也是研究与应用最多的一种推荐技术,它依赖于用户的行为,关注用户与项目的关联,主要分为两种不同算法,分别是基于用户的算法和基于项目的算法。基于用户的协同过滤基本原理就是寻找具有相似行为的用户,为用户推荐与其兴趣相投的用户所喜爱的资源;基于项目的协同过滤推荐旨在为用户推荐和他曾经感兴趣的项目具有相似性的项目,相似并非指项目内容的相似,而是利用用户对项目的评价或者行为,挖掘项目之间的相似度。但协同过滤算法过于依赖用户行为,导致当系统存在新用户或者新项目时,推荐将无从依据。除此之外,在实际生活中项目有上千万种,与用户产生交互的项目往往占少数,仅通过用户对项目的行为来挖掘相似项目会导致协同过滤算法的效果较差。针对这个问题,目前大多数研究的做法是引入辅助信息作为推荐算法的输入。
而知识图谱包含了丰富的语义信息,旨在以结构化的形式来表示真实世界中的实体或概念以及它们之间的关联关系,其本质是一张巨大的语义网络图,将海量知识以更直观的方式展示在用户面前,由节点和边构成,其中节点代表实体或者概念,边代表实体间的关系或者实体的属性。知识图谱引入了更多的语义关系,提供了不同的关系连接种类,将知识图谱引入推荐系统中,能充分利用知识图谱中丰富的语义信息,从而可以深层次地发现用户兴趣,避免推荐结果局限于单一类型,提高了推荐系统精准性、多样性和可解释性,从而提高用户对推荐结果的满意度。
目前已有一些基于知识图谱的推荐方法的研究,比如基于路径的推荐方法,需要构造连接两个实体的一条特定的路径,但手动构造路径的方法在实践中难以到达最优;基于图算法的推荐方法直观利用知识图谱是语义网络图的特点,利用随机游走等算法对图中节点进行采样,但图算法可移植性差、计算复杂度高,当面临大型知识图谱时,很难做到实时计算。
技术实现要素:
发明目的:针对现有技术的缺陷和不足,本发明提供一种基于知识图谱的信息资源查询推荐方法,兼顾知识的内在联系和用户兴趣,根据用户输入查询的资源名称,快速高效地向用户推荐与查询内容相关并且符合用户兴趣的信息资源。
技术方案:根据本发明的第一方面,提供一种基于知识图谱的信息资源查询推荐方法,所述方法包括以下步骤:
(1)利用知识图谱表示学习方法将知识图谱映射至低维稠密的向量空间中,实现对知识图谱中的信息资源的向量化语义表示;
(2)根据用户历史行为,计算用户对信息资源的兴趣度;
(3)结合用户对信息资源的兴趣度与信息资源的向量化语义表示,构建用户兴趣模型;
(4)根据用户查询的信息资源,计算该信息资源与其他信息资源的相似度,取相似度top-m的信息资源形成候选资源集;
(5)计算候选资源集中的信息资源与用户的相似度,从候选资源集中筛选出相似度top-n的信息资源形成推荐列表。
进一步地,所述步骤1包括:
(11)从知识图谱中选取指定数量的三元组(h,r,t),称之为正例三元组,其中h、t分别代表头实体、尾实体,r表示两个实体间的关系;
(12)利用负采样算法替换正例三元组的头实体或者尾实体,得到负例三元组;
(13)利用表示学习模型迭代训练正例三元组和负例三元组至收敛,得到实体的向量表示vi={v1,v2……,vm},其中m表示维度。
进一步地,所述步骤12包括:
(121)在关系r的所有三元组中,统计每个头实体相应的尾实体的平均个数,记为tph;统计每个尾实体相应的头实体的平均个数,记为hpt;
(122)对于一个正例三元组(h,r,t),抽取实体来替换头实体h和尾实体t,以p的概率替换头实体,以1-p的概率替换尾实体,生成负例三元组,其中替换概率p的计算公式为:
进一步地,所述步骤2包括:
(21)收集包含用户行为的日志,包括用户浏览的资源名称、资源内容长度、浏览时长;
(22)根据是否点击浏览、浏览时间、浏览速度建立多元线性方程,计算用户对资源的兴趣度。
进一步地,所述步骤22包括:
(221)用户点击浏览某条信息资源i,记其点击兴趣度为ci;
(222)根据用户对资源i的浏览时长ti和用户的平均浏览速度计算其浏览兴趣度ri:
其中t1表示用户对资源i的最少浏览时间,t2表示用户对资源i的最大浏览时间,s为用户的平均浏览速度,
(223)综合点击兴趣度和浏览兴趣度,得到用户对资源i的兴趣度ii=ω1ci+ω2ri,其中ω1、ω2代表点击兴趣度与浏览兴趣度在计算总兴趣度时所占的权重,且ω1+ω2=1。
进一步地,所述步骤3中用户兴趣模型为:
进一步地,所述方法在步骤1后还包括:根据信息资源的向量计算资源间的距离,根据距离判断其相似度,将相似的信息资源实体聚集形成一个簇,相异的信息资源实体划分到不同的簇中。
进一步地,所述步骤4中通过余弦距离计算两个资源之间的相似度,所述步骤5中通过余弦距离计算信息资源与用户兴趣之间的相似度。
根据本发明的第二方面,提供一种基于知识图谱的信息资源查询推荐系统,所述系统包括:
数据预处理模块,用于利用知识图谱表示学习模型将知识图谱嵌入低维向量空间,通过学习获得实体、关系及属性的向量化表示;
用户兴趣模型构建模块,用于对用户行为进行分析,了解用户的兴趣,构建用户兴趣模型;以及
查询推荐模块,用于根据用户输入查询的资源获取候选资源集,在候选资源集中筛选出贴近用户兴趣的资源进行推荐。
有益效果:本发明基于知识图谱表示学习的推荐方法把知识图谱作为一个语言丰富、逻辑推理能力强的数据集融入到传统的推荐算法中,利用表示学习将知识图谱的每个实体和关系表示为稠密低维实值向量,降低知识图谱的高维性,使得在低维向量空间中,可以高效计算实体间的语义联系,减少由于引入知识图谱带来的额外计算负担,从而增强知识图谱应用的灵活性。具体体现在:
1、充分利用了知识图谱中丰富的语义信息,弥补传统协同过滤算法未考虑被推荐项目的语义信息的缺陷。利用知识图谱表示学习把知识库中的实体、关系映射到低维稠密的向量空间中,完成对实体和关系的语义表示,显著提升了计算效率,可以通过余弦距离度量实体之间的语义相似度,同时一个实体有一个稠密向量与之相应,也缓解了数据稀疏的问题。
2、在模型训练过程中,采用伯努利负采样算法,该算法通过设置不同的更换头实体或尾实体的概率有效避免引入错误的负例三元组。
3、在分析用户历史行为的基础上构建用户兴趣模型,将用户兴趣映射至低维向量空间中,使得用户兴趣和信息资源成为向量空间中的点,通过计算资源与资源、用户与资源之间的距离可知其相似度,计算过程简明。
4、将知识图谱表示学习与用户兴趣模型相结合来为用户提供个性化服务,兼顾知识的内在联系和用户兴趣,根据用户输入查询的资源名称,向用户推荐与查询内容相关并且符合用户兴趣的信息资源,使得个性化查询推荐更具专业性及针对性。
附图说明
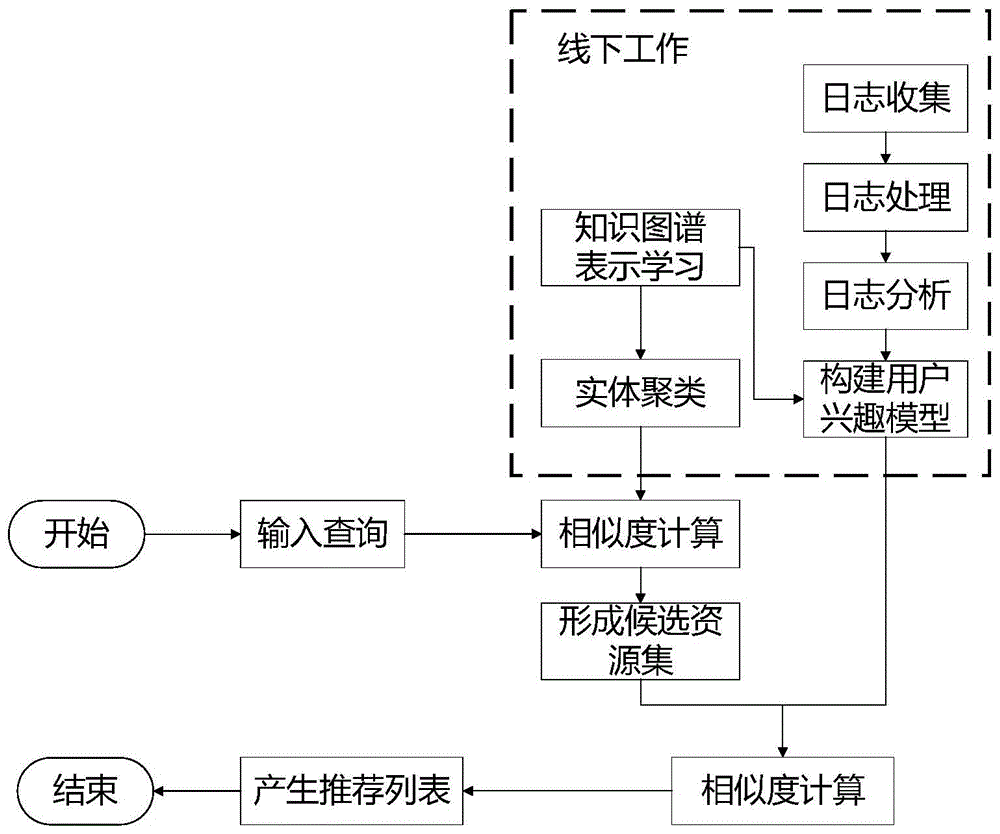
图1为根据本发明实施例的推荐方法整体流程图;
图2为为根据本发明实施例的日志预处理结果图;
图3根据本发明实施例的用户兴趣模型构建流程图;
图4为根据本发明实施例的推荐系统模块图。
具体实施方式
下面结合附图对本发明的技术方案作进一步说明。应当了解,以下提供的实施例仅是为了详尽地且完全地公开本发明,并且向所属技术领域的技术人员充分传达本发明的技术构思,本发明还可以用许多不同的形式来实施,并且不局限于此处描述的实施例。对于表示在附图中的示例性实施方式中的术语并不是对本发明的限定。
在一个实施例中,以水利信息资源查询推荐为例,在查询推荐过程中引入水利领域知识图谱作为辅助信息,利用知识图谱表示学习方法将知识图谱中的实体、关系映射到低维稠密的向量空间中,实现对实体和关系的语义表示,弥补传统推荐算法未考虑语义信息的缺陷。然后,在分析用户浏览行为和浏览内容的基础上,构建低维的用户兴趣模型。最后,将知识图谱和用户兴趣模型相结合,构建基于水利领域知识图谱的信息资源查询推荐系统,实现根据用户的查询精准推荐符合用户兴趣的水利信息资源。
图1为基于水利领域知识图谱的信息资源查询推荐方法的流程图,如图1所示,该方法的实现过程包括以下步骤:
步骤1,利用知识图谱表示学习模型将知识图谱映射至低维稠密的向量空间中,实现对知识图谱中的水利信息资源的向量化语义表示。
知识图谱以信息资源作为其概念实体节点,以信息资源的相关属性信息作为其特征标签节点,两个节点的边代表了实体之间的关系或实体的属性。利用三元组表示即为(h,r,t)或(e,a,v),其中(h,r,t)中的h、t分别代表头实体、尾实体,r表示两个实体间的关系,(e,a,v)中的e代表实体,a、v代表实体的属性和属性值。
具体而言,步骤1包括:
步骤1.1,从知识图谱中选取一定数量的三元组(h,r,t),称之为正例三元组,例如水利领域知识图谱中的三元组(岩滩水库,工程规模,大1型);
步骤1.2,利用负采样算法替换正例三元组的头实体或者尾实体,生成负例三元组,即错误的正例三元组,具体步骤为:
步骤1.2.1,在关系r的所有三元组中,统计每个头实体相应的尾实体的平均个数,记为tph;统计每个尾实体相应的头实体的平均个数,记为hpt;
例如,对于存在3个三元组(h1,r,t1),(h1,r,t2),(h2,r,t3)的知识图谱,h1对应的尾实体个数为2,h2对应的尾实体个数为1,则
步骤1.2.2,定义替换概率公式
步骤1.2.3,对于一个正例三元组(h,r,t),抽取知识图谱中的实体来替换正例三元组中的头实体h或者尾实体t,从而产生一个新的三元组,这个三元组被认为是负例三元组。以p的概率替换头实体,以1-p的概率替换尾实体,从而打破正例三元组,生成负例三元组。
步骤1.3,利用表示学习模型迭代训练正例三元组和负例三元组至收敛。
表示学习模型通过不断迭代来更新模型中的参数,即损失函数,经过多次迭代后损失收敛,即求得损失函数的最小值,实体向量、关系向量和属性向量循环收敛至最优,损失函数定义如下:
其中(h,r,t)表示正例三元组,(h′,r,t′)表示负例三元组,γ为设定的边际值,符号[]+是合页损失函数。‖h+r-t‖即表示头实体h和关系r的向量之和与尾实体t向量的差的距离,在模型中对于一个正例三元组,期望‖h+r-t‖的值越小越好,对于负例三元组则期望‖h′+r-t′‖的值越大越好,这样在实验中可以通过训练模型区分正负样本。
为了加快收敛,对数据进行初始化和归一化处理。首先将实体、关系的向量进行均匀分布初始化:
k表示指定的向量维度,初始化后,进行归一化处理:
在每一次的迭代过程中,都需要先对实体向量进行归一化处理。模型训练过程中如果对所有三元组都进行迭代训练那么代价是非常大的,因此为了加快收敛,采用小批量梯度下降算法作为模型的训练算法,即在每一次迭代时,从水利领域知识图谱中选取小批量的训练三元组作为参考进行训练,来确定模型的更新方向,然后通过一个学习速率恒定的梯度步骤来更新参数,即损失函数。
模型训练至收敛时,知识图谱中的实体能被映射至低维空间中的相应位置,使得具有相同属性或者相同关系的实体距离相近,模型训练结束。得到实体的向量表示vi={v1,v2……,vk}。
步骤2,对信息资源进行聚类。
根据信息资源的向量,计算资源间的余弦距离,判断其相似度,将相似的信息资源实体聚集起来形成一个簇,而相异的信息资源实体被划分到不同的簇中,相似的信息资源即具有相同属性或相同关系的信息资源,而相异的信息资源即不存在或存在较少相同属性或相同关系的信息资源。经过聚类后,相似的信息资源实体聚成一个簇,为后续步骤中候选资源集的筛选减少了计算量,有效提高效率。
步骤3,根据用户历史行为,计算用户对信息资源的兴趣度,具体步骤如下:
步骤3.1,收集包含用户行为的日志,包括用户浏览的资源名称、资源内容长度、浏览时长等信息;
实施例中使用日志组件进行日志记录,利用js埋点技术收集用户浏览水利信息资源的行为数据。日志中包含了系统的运行情况,如数据库的连接状况,系统的错误信息,如服务器或程序内部的错误,以及用户自定义的日志输出内容,例如程序的调试信息,用户的行为数据等。根据需求,需要对系统日志进行过滤处理,得到仅包含用户行为数据的日志。
图2为经过预处理后的日志,其中_ip即为用户的ip地址,此为用户的唯一标识;_url为当前的url地址;_refer为用户上一个访问的url地址;_millisecond为用户进入页面的毫秒数,此为long型的从1970.1.1开始的毫秒数,方便计算时间间隔;_id为用户所浏览的水利信息资源的唯一标识;_name为水利信息资源的名称;_length为信息资源的内容长度,其表示的是信息资源摘要信息的长度。
步骤3.2,从点击浏览、浏览时长、浏览速度三个方面出发,以多元线性方程为基础,将用户兴趣度抽象成数字,计算用户对资源的兴趣度。具体步骤为:
步骤3.2.1,用户点击浏览某条信息资源i时,记其点击兴趣度为ci;
用户对资源只有两种操作,点击和未点击,将用户的点击兴趣度定义为:
从图2日志可知用户点击浏览“丹江口水电站”这条水利信息资源,记ci=1。
步骤3.2.2,根据用户浏览时间、浏览速度计算其浏览兴趣度ri,其中浏览速度可根据浏览时长和资源内容长度计算;
用户浏览每个资源的时间越长,表明用户对该资源的兴趣度越高;反之时间越短,说明该用户对该资源的兴趣度越低。而在用户阅读的平均速度基本是稳定的情况下,用户浏览每个资源的速度越慢,说明其花费较多时间去阅读,可判断其对该资源的兴趣度越高;反之其兴趣度越低。将用户的浏览兴趣度定义为:
其中ti表示用户浏览资源i的时长,t1表示最少浏览时间,当ti<t1时,表示用户对该资源没有兴趣或是误点入资源详情页;t2表示最大浏览时间,当ti>t2时,认为用户有可能是在浏览过程中停留在该页面而去处理其他事情。为了避免这些情况影响用户兴趣度的计算,将这些的情况浏览兴趣度计为0。s为用户的平均浏览速度,由于不同的用户阅读能力不同,但其阅读速度是稳定的,依据用户的历史行为,根据下式计算得到用户的平均浏览速度:
其中l是用户浏览资源的总长度,t是用户浏览资源的总时间。
从图2日志可知该资源的内容长度“_length”为119字,而浏览时间可根据前后两次行为的时间差相减得到,浏览资源时间t约为35秒。例如,假设用户平均浏览速度s为7.5字/秒,计算得到浏览兴趣度ri为2.21。
步骤3.2.3,综合点击兴趣度和浏览兴趣度,用户对资源i的兴趣度定义为ii=ω1ci+ω2ri,其中ω1、ω2代表点击兴趣度与浏览兴趣度在计算总兴趣度时所占的权重,且ω1+ω2=1。
例如,ω1、ω2分别取值0.2、0.8,最终得到用户对该资源的综合兴趣度ii为1.97。
步骤4,结合用户对信息资源的兴趣度与信息资源的向量化语义表示,构建用户兴趣模型。
用户兴趣模型将用户兴趣表示为稠密低维实值向量,其维度与信息资源实体向量相同,目的就是将用户兴趣映射到实体所在的低维空间中,定义公式为u={u1,u2……,um}。
图3为用户兴趣模型构建流程,结合用户对信息资源i的兴趣度ii与信息资源i的向量化语义表示vi={v1,v2……,vm},构建用户兴趣模型,其公式为,
最终,知识图谱与用户兴趣都映射到低维空间中,使得用户兴趣和水利信息资源实体成为低维空间中的点,通过计算资源与资源、资源与用户之间的距离能判断其相似度。
步骤5,根据用户查询的信息资源,计算该信息资源与其他信息资源的相似度,取相似度top-m的信息资源形成候选资源集。
候选资源集是指相似信息资源的集合,是最终推荐列表内的信息资源的来源,它保证了最终推荐的信息资源与用户查询内容相关。在低维向量空间中,可通过余弦距离计算两个资源之间的相似度,计算公式为:
其中et是知识图谱中除了实体ei以外的其他实体,vi、vt代表实体ei和实体et的向量。经过计算获得与水利信息资源实体ei具有较高相似度的m个水利信息资源,形成候选资源集d={d1,d2,……,dm}。
步骤6,计算候选资源集中的信息资源与用户的相似度,从候选资源集中筛选出相似度top-n的信息资源形成推荐列表。
候选资源集是产生最终推荐列表的前提,其保证了推荐内容与查询内容相关,而要提供个性化推荐服务,还需要结合用户兴趣模型从候选资源集中筛选出贴近用户兴趣的资源,生成最终推荐列表。
在同一低维空间中,若用户与资源的距离相近,则表示用户对该资源的喜爱程度高;反之,若用户与资源相距较远,说明用户不关注该资源。利用余弦相似度公式计算用户与候选资源集中的水利信息资源的相似度,从候选资源集中筛选出与用户兴趣具有较高相似度的n个实体,产生top-n推荐。
图4为基于知识图谱的信息资源查询推荐系统的模块图,包括数据预处理模块、用户兴趣模型构建模块、查询推荐模块,所述数据预处理模块包括知识图谱表示单元,利用知识图谱表示学习模型将知识图谱嵌入低维向量空间,通过学习获得实体、关系及属性的向量化表示;所述用户兴趣模型构建模块根据用户行为进行分析,了解用户的兴趣,构建用户兴趣模型;所述查询推荐模块主要是根据用户输入查询的资源,来获取候选资源集,在候选资源集中筛选出贴近用户兴趣的资源。
具体而言,知识图谱表示单元从知识图谱中选取一定数量的正例三元组(h,r,t),利用负采样算法替换正例三元组的头实体或者尾实体,生成负例三元组,利用模型迭代训练正例三元组和负例三元组至收敛,实现将知识图谱中的实体映射至低维空间中的相应位置,得到实体的向量表示vi={v1,v2……,vk}。
作为优选的实施方案,数据预处理模块还包括聚类单元,利用聚类方法对信息资源实体进行聚类。聚类单元根据信息资源的向量,计算资源间的余弦距离,判断其相似度,将相似的信息资源实体聚集起来形成一个簇,而相异的信息资源实体被划分到不同的簇中,相似的信息资源即具有相同属性或相同关系的信息资源,而相异的信息资源即不存在或存在较少相同属性或相同关系的信息资源。
用户兴趣模型构建模块包含日志收集单元、日志处理单元、日志分析单元、用户兴趣模型构建单元,其中日志收集单元收集包含用户行为的日志,包括用户浏览的资源名称、资源内容长度、浏览时长等信息;日志处理单元对系统日志进行过滤处理,得到仅包含用户行为数据的日志;日志分析单元从点击浏览、浏览时长、浏览速度三个方面出发,以多元线性方程为基础,将用户兴趣度抽象成数字,计算用户对资源的兴趣度;用户兴趣模型构建单元结合用户对信息资源的兴趣度与信息资源的向量化语义表示,构建用户兴趣模型。
查询推荐模块包含候选资源集单元、推荐列表单元,其中候选资源集单元通过余弦距离计算两个资源之间的相似度,取相似度top-m的信息资源形成候选资源集;推荐列表单元利用余弦相似度公式计算用户与候选资源集中的信息资源的相似度,从候选资源集中筛选出与用户兴趣具有较高相似度的n个实体,产生top-n推荐。
上述各模块中所涉及的具体计算公式可参照方法实施例中相应公式,此处不再赘述。
本发明提供了一种基于知识图谱的信息资源查询推荐方法和推荐系统,将知识图谱表示学习与用户兴趣模型相结合,实现根据用户的查询精准推荐符合用户兴趣的信息资源。知识图谱是语义丰富、逻辑能力强的数据集,包含了结构化和非结构化数据,深入知识的内在联系。本发明将内涵知识和用户偏好融合在一起,使得推荐算法更具权威性、专业性和针对性。并且,融合了知识图谱的推荐系统还可以提供解释,让用户或者系统设计者知道为什么推荐这些项目,有助于提高效率、说服力以及推荐系统的用户满意度。表示学习是指利用数字,如矩阵、向量,来表达现实世界的某种事物,这种表达方式有利于后续的分类或决策问题,使得后续任务可以事半功倍。同理,知识图谱表示学习旨在将实体和关系转化为低维空间中的向量,同时不改变知识图谱的内在结构。通过实体与关系向量化显著提升了计算效率,可以通过欧氏距离或余弦距离度量实体之间的语义相似度,同时一个实体有一个稠密向量与之相应,也缓解了数据稀疏的问题。
以上所述仅是本发明的优选实施方式,应当指出:对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!