一种区域视频人体动作行为实时识别方法与流程
本发明涉及视频监控设备中目标人员检测的技术,涉及一种区域视频人体动作行为实时识别方法。
背景技术:
在视频监督领域,准确而快速的对监控视频进行智能分析一直是一个技术难点。视频监督即借助计算机强大的数据处理能力过滤掉视频画面无用的或干扰信息,自动识别并掌握不同人物的动作、行为特性,抽取视频源中关键有用信息,快速准确的定位事故现场,判断监控画面中的异常情况,并以最快和最佳的方式发出警报或触发其它动作,从而有效实现事前预警、事中处理、事后及时取证的功能。与一般的分类问题不同,在视频监督过程中,由于场景的多变,场景中人、事、物的多变,以及视觉任务的多变,导致视频督察的难度相当的大,是一个亟需解决的问题。
视频监督过程中,如果画面中在某一时刻或者某一时间段出现了不符合常理的动作、行为,则判定为该时刻或时间段的工作区域出现问题,这称为全局监督。而在全局监督的基础上,对于同一个画面会同时出现不同事件的情况,不仅监测出是否有异常动作、行为发生,而且粗略计算出事件的位置,称为局部监督。本发明中对人员入侵、超时审讯和人员密度的监督属于全局监督,人员进入和人员离岗则属于局部监督。
视频监督的主要目的是对视频中的画面进行连续的监测,判断监控画面中的异常情况,快速准确的定位不符合规范的动作、行为的位置,并以最快和最佳的方式发出警报。由于需要进行快速准确的提示和预警,因此对算法的计算速度和准确度要求很高。
技术实现要素:
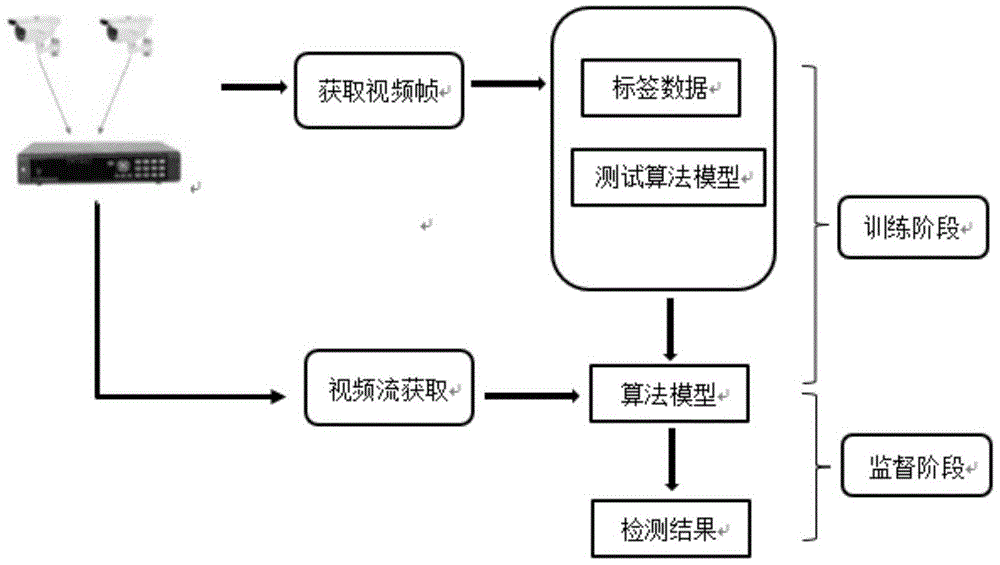
为了解决上述技术问题,本发明提出了一种区域视频人体动作行为实时识别方法。当输入一个视频流时,通过opencv技术将视频流提取成多个视频帧图像,针对输入的视频帧图像获取多尺度特征图,同时在不同的特征图上面进行预测,在不同的特征层的特征图上的每个像素点同时获取6个不同的默认候选框,将其与真实的目标边界框进行匹配。然后将匹配成功的候选框结合起来,通过非极大值抑制算法(nms)得到最具代表性的结果,以加快目标检测的效率。
本发明提出一种区域视频人体动作行为实时识别方法,可以快速的准确的对视频进行监督,适用于公共场所、公司家庭等多种应用场景,可以根据具体的需求进行相应的调整,其特征在于,包括以下步骤:
步骤1:使用opencv技术读取实时rtsp视频流,获取多帧视频图像,对每帧图像标出检测物体的目标的真实边界框及类别作为标签,以构建训练数据;
步骤2:将训练数据集输入到多目标检测网络模型中进行训练,以目标损失最小为优化目标,通过使用自适应矩估计优化方法得到优化后超参数,通过以上训练过程就完成了训练后的多目标检测网络模型;
步骤3:将测试视频图像输入训练后的多目标检测网络模型获得检测结果,根据检测结果返回异常信息,由此异常信息触发警报;
作为优选,步骤1中所述多帧图像为:
datai,i∈[1,k]
其中,k为视频流中图像帧的数量;
第i帧图像u行v列像素为:
datai(u,v),u∈[1,h],v∈[1,w]
其中,h为一帧图像中行的数量,w为一帧图像中列的数量;
对对每帧图像标出检测物体的目标的真实框及类别具体为:
目标的真实边界框为:truthboxj=[txj,tyj,twj,thj],j∈[1,k]
其中,txj表示第j帧图像中目标物的真实边界框在左上角的像素横坐标,tyj表示第j帧图像中目标物的真实边界框在左上角的像素纵坐标,twj表示第j帧图像中目标物的真实边界框的宽度,thj表示第j帧图像中目标物的真实边界框的高度;
类别为cati:cati∈[1,c],c表示总的类别数量;
步骤1中所述标签为:
labeli={truthboxi,cati},i∈[1,k]
其中,labeli第i帧图像的标签;
步骤1中所述训练数据集为:
train_datai={datai,labeli},i∈[1,k],k<=k,train_datai∈datai
作为优选,步骤2中所述多目标检测网络模型过程可表示为:
y=f(datai,w)
其中,datai表示输入一帧图像,w表示函数f中的超参数,y表示网络输出,即输入一帧图像中目标检测物的预测目标框boxi以及类别cati,输出结果y*可具体表示为:
步骤2中所述将训练数据集train_datai输入到多目标检测网络模型中进行训练具体为:
步骤2.1,网络采用vgg16作为基础模型,采用大小分别是(38,38),(19,19),(10,10),(5,5),(3,3),(1,1)的六个不同的卷积核,通过卷积操作提取出不同大小的特征图,即多尺度特征图
步骤2.2,在h*w大小的特征图xi的每个像素点(u,v)上生成m个固定的边界框即defalutbox,每张特征图共有m*h*w个defalutbox,表示为集合db,defaulboxi∈db,表示db中第i个defaultbox,i∈[1,m*h*w]
对于每个defaulboxi都需要通过卷积操作预测c个类别分数和4个偏移量即offset,所以这个特征图共有(c+4)*m*h*w个输出;
其中,c*m*h*w是置信度输出,表示每个defaulboxi的置信度,也就是类别的概率,数量4*m*h*w是位置输出,表示每个defaulboxi的坐标(cxi,cyi,wi,hi);
所述defalutbox生成规则:
以特征图xi上每个像素点的中点为中心(offset=0.5),生成大小有六种不同长宽比的defalutbox;
所述defalutbox的最小边长为:min_size;(对应六种不同大小的卷积核,min_size依次设为30,60,111,162,213,264)
所述defalutbox的最大边长为:
设置一个扩大率ratio,会生成2个长方形,长为:
而每个xi对应defalutbox的min_size和max_size由以下公式决定,其中m=6表示六种不同大小的defaultbox,
使用不同的ratio值,[1,2,3,1/2,1/3],通过下面的公式计算defaultbox的宽度w和高度h:
步骤2.3,将步骤2.2生成的边界框defaulboxi与真实的边界框truthboxi=[txi,tyi,twi,thi]匹配,符合匹配条件的边界框defaulboxi是有限的;
所述匹配的策略为:
truthbox的集合tb,truthboxj∈tb,表示tb中第j个truthbox,其中j<k,k是labeli的数量
defaultbox的集合db,defaulboxi∈db,表示db中第i个defaultbox.i∈[1,m*h*w]
在db中寻找一个defaulboxi,使其能与tb中truthboxj有最大的iou值,这样就能保证truthbox至少有一个defaulboxi与之匹配;
之后将剩余还没有配对的defaulboxj(i≠j,且j∈[1,m*h*w])与任意一个truthboxi尝试配对,只要两者之间的iou大于匹配阈值α=0.5,就认为匹配;
配对到truthbox的所述defaulboxi就是正样本,没有配对的defaultbox就是负样本;
图片上被标记的各种分类,所述defaultbox和truthbox相互匹配后得到的结果;
通过计算每个defaulboxi和每个truthboxj的交并比iou,筛选出最大值,就可以知道每个truthbox应该匹配哪个defaulboxi,而对于iou>α=0.5的defaulboxi则被认为是真正匹配框truthbox;
其中,交并比iou表示的是预测的边界框defaulboxi和真实的边界框truthboxj的交集和并集的比值,即:
步骤2.4,将生成的所有defaulboxi集合起来,通过非极大值抑制模块,输出最终后的defaulboxi的集合,这样每个truthboxi对应的所有的defaulboxi就是最终的检测结果;
所述非极大值抑制的具体实现步骤为:
步骤2.4.1将所有边界框defaulboxi的iou得分排序,选中iou得分最高及其对应的defaulboxi;
步骤2.4.2遍历其余的defaultbox,如果和当前iou得分最高的边界框defaulboxi的重叠面积大于阈值α(α=0.5),就将上一步的defaulboxi删除。
步骤2.4.3从未处理的defaultbox中继续选一个iou得分最高的,重复步骤2.4.1以及步骤2.4.2,直至遍历完db中所有边界框;
步骤2中ssd网络模型的目标损失分为两部分:相应的defaultbox与目标类别的置信损失confidenceloss以及相应的位置回归,具体为:
其中,n是匹配到truthbox的defaulboxi的数量,n=0时,损失函数为0,
优化求解方法:
自适应矩估计adam是一种不同参数自适应不同学习速率方法,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,改善网络的训练方式,来最小化损失函数;
多目标检测网络模型使用自适应矩估计方法adam优化损失函数l(x,c,s,g),找到局部最优值使其达到最小;
优化输出结果:
min(l(x,c,l,g))得到局部最小值,以及这时y*=f(datai,w*)中的超参数w*;
作为优选,步骤3中所述异常信息包括以下四个方面:
人员入侵:在视频图像中固定入侵区域边界框rbox[rx,ry,rw,rh],判断bbox[rx,ry,rw,rh]与ssd的预测目标框
进入:在视频图像中固定门的边界框mbox[mx,my,mw,mh],判断mbox[mx,my,mw,mh]与ssd的预测目标框
离岗:在视频图像中固定岗位位置边界框gbox[gx,gy,gw,gh],判断gbox[gx,gy,gw,gh]与ssd的预测目标框
超时谈话:从检测到人员进入门mbox[mx,my,mw,mh]开始计时,判断人员所在时间是否超过设定的某个计时时间,若超过,视为超时谈话;未超过,视为正常情况;
人员密度:检测到类别为人的目标预测框的数目即为人员密度。
本发明优点在于,可以准确而快速的对监控视频中的画面进行连续的监测,抽取视频中关键有用信息,自动识别并掌握监控设备区域视频内的五种情况信息(人员入侵、进入、离岗、超时谈话和人员密度),判断监控画面中的异常情况,快速准确的定位不符合规范的人员的位置,并以最快和最佳的方式发出警报信息,从而有效实现事前预警、事中处理、事后及时取证的功能。
附图说明
图1:是本算法的整体流程图;
图2:是本算法用于特征图提取阶段的网络结构图;
图3:是根据提取出的多尺度特征图进行预测。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明主要应用于办公场所、公共场所等安全监控,主要为了及时防范、处理突发公共事件。可具体应用于公司、小区住宅、商场、学校、医院等区域。公司应用此系统对员工的工作情况进行监控管理,小区住宅通过此系统实现对外来人员的监控,商场实现对客流量以及顾客人身安全的监控,学校应用此系统对学生异常行为进行监控。本发明的实施平台是通过计算机获取监控设备如摄像机的实时监控视频,并对其进行智能分析处理。
下面结合图1至图3介绍本发明的具体实施方式为:
步骤1:使用opencv技术读取实时rtsp视频流,获取多帧视频图像,对每帧图像标出检测物体的目标的真实边界框及类别作为标签,以构建训练数据;
步骤1中所述多帧图像为:
datai,i∈[1,k]
其中,k为视频流中图像帧的数量;
第i帧图像u行v列像素为:
datai(u,v),u∈[1,h],v∈[1,w]
其中,h为一帧图像中行的数量,w为一帧图像中列的数量;
对对每帧图像标出检测物体的目标的真实框及类别具体为:
目标的真实边界框为:truthboxj=[txj,tyj,twj,thj],j∈[1,k]
其中,txj表示第j帧图像中目标物的真实边界框在左上角的像素横坐标,tyj表示第j帧图像中目标物的真实边界框在左上角的像素纵坐标,twj表示第j帧图像中目标物的真实边界框的宽度,thj表示第j帧图像中目标物的真实边界框的高度;
类别为cati:cati∈[1,c],c表示总的类别数量;
步骤1中所述标签为:
labeli={truthboxi,cati},i∈[1,k]
其中,labeli第i帧图像的标签;
步骤1中所述训练数据集为:
train_datai={datai,labeli},i∈[1,k],k<=k,train_datai∈datai
步骤2:将训练数据集输入到多目标检测网络模型中进行训练,以目标损失最小为优化目标,通过使用自适应矩估计优化方法得到优化后超参数,通过以上训练过程就完成了训练后的多目标检测网络模型;
步骤2中所述ssd网络模型过程可表示为:
y=f(datai,w)
其中,datai表示输入一帧图像,w表示函数f中的超参数,y表示网络输出,即输入一帧图像中目标检测物的预测目标框boxi以及类别cati,输出结果y*可具体表示为:
步骤2中所述将训练数据集train_datai输入到多目标检测网络模型中进行训练具体为:
步骤2.1,网络采用vgg16作为基础模型,采用大小分别是(38,38),(19,19),(10,10),(5,5),(3,3),(1,1)的六个不同的卷积核,通过卷积操作提取出不同大小的特征图,即多尺度特征图
步骤2.2,在h*w大小的特征图xi的每个像素点(u,v)上生成m个固定的边界框即defalutbox,每张特征图共有m*h*w个defalutbox,表示为集合db,defaulboxi∈db,表示db中第i个defaultbox,i∈[1,m*h*w];
对于每个defaulboxi都需要通过卷积操作预测c个类别分数和4个偏移量即offset,所以这个特征图共有(c+4)*m*h*w个输出;
其中,c*m*h*w是置信度输出,表示每个defaulboxi的置信度,也就是类别的概率,数量4*m*h*w是位置输出,表示每个defaulboxi的坐标(cxi,cyi,wi,hi);
所述defalutbox生成规则:
以特征图xi上每个像素点的中点为中心(offset=0.5),生成大小有六种不同长宽比的defalutbox;
所述defalutbox的最小边长为:min_size;
所述defalutbox的最大边长为:
设置一个扩大率ratio,会生成2个长方形,长为:
而每个xi对应defalutbox的min_size和max_size由以下公式决定,m=6表示六种不同大小的defaultbox
使用不同的ratio值,分别为[1,2,3,1/2,1/3],通过下面的公式计算defaultbox的宽度w和高度h:
步骤2.3,将步骤2.2生成的边界框defaulboxi与真实的边界框truthboxi=[txi,tyi,twi,thi]匹配,符合匹配条件的边界框defaulboxi是有限的;
所述匹配的策略为:
truthbox的集合tb,truthboxj∈tb,表示tb中第j个truthbox,其中j<k,k是labeli的数量
defaultbox的集合db,defaulboxi∈db,表示db中第i个defaultbox.i∈[1,m*h*w]
在db中寻找一个defaulboxi,使其能与tb中truthboxj有最大的iou值,这样就能保证truthbox至少有一个defaulboxi与之匹配;
之后将剩余还没有配对的defaulboxj(i≠j,且j∈[1,m*h*w])与任意一个truthboxi尝试配对,只要两者之间的iou大于匹配阈值α=0.5,就认为匹配;
配对到truthbox的所述defaulboxi就是正样本,没有配对的defaultbox就是负样本;
图片上被标记的各种分类,所述defaultbox和truthbox相互匹配后得到的结果;
通过计算每个defaulboxi和每个truthboxj的交并比iou,筛选出最大值,就可以知道每个truthbox应该匹配哪个defaulboxi,而对于iou>α=0.5的defaulboxi则被认为是真正匹配框truthbox;
其中,交并比iou表示的是预测的边界框defaulboxi和真实的边界框truthboxj的交集和并集的比值,即:
步骤2.4,将生成的所有defaulboxi集合起来,通过非极大值抑制模块,输出最终后的defaulboxi的集合,这样每个truthboxi对应的所有的defaulboxi就是最终的检测结果;
所述非极大值抑制的具体实现步骤为:
步骤2.4.1将所有边界框defaulboxi的iou得分排序,选中iou得分最高及其对应的defaulboxi;
步骤2.4.2遍历其余的defaultbox,如果和当前iou得分最高的边界框defaulboxi的重叠面积大于阈值α(α=0.5),就将上一步的defaulboxi删除。
步骤2.4.3从未处理的defaultbox中继续选一个iou得分最高的,重复步骤2.4.1以及步骤2.4.2,直至遍历完db中所有边界框;
步骤2中ssd网络模型的目标损失分为两部分:相应的defaultbox与目标类别的置信损失confidenceloss以及相应的位置回归,具体为:
其中,n是匹配到truthbox的defaulboxi的数量,n=0时,损失函数为0,
优化求解方法:
自适应矩估计adam是一种不同参数自适应不同学习速率方法,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,改善网络的训练方式,来最小化损失函数;
多目标检测网络模型使用自适应矩估计方法adam优化损失函数l(x,c,l,g),找到局部最优值使其达到最小;
优化输出结果:
min(l(x,c,l,g))得到局部最小值,以及这时y*=f(datai,w*)中的超参数w*;
步骤3:将测试视频图像输入训练后的多目标检测网络模型获得检测结果,根据检测结果返回异常信息,由此异常信息触发警报;
异常信息包括以下四个方面:
人员入侵:在视频图像中固定入侵区域边界框rbox[rx,ry,rw,rh],判断bbox[rx,ry,rw,rh]与ssd的预测目标框
进入:在视频图像中固定门的边界框mbox[mx,my,mw,mh],判断mbox[mx,my,mw,mh]与ssd的预测目标框
离岗:在视频图像中固定岗位位置边界框gbox[gx,gy,gw,gh],判断gbox[gx,gy,gw,gh]与ssd的预测目标框
超时谈话:从检测到人员进入门mbox[mx,my,mw,mh]开始计时,判断人员所在时间是否超过设定的某个计时时间,若超过,视为超时谈话;未超过,视为正常情况;
人员密度:检测到类别为人的目标预测框的数目即为人员密度。
图3是根据训练过程中对提取出的多尺度特征图
应当理解的是,本说明书未详细阐述的部分均属于现有技术。
应当理解的是,上述针对较佳实施例的述较为详细,并不能因此而认为是对本发明专利保护范围的限制,本领域的普通技术人员在本发明的启示下,在不脱离本发明权利要求所保护的范围情况下,还可以做出替换或变形,均落入本发明的保护范围之内,本发明的请求保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!