一种基于生成对抗网络的多域图像风格迁移方法与流程
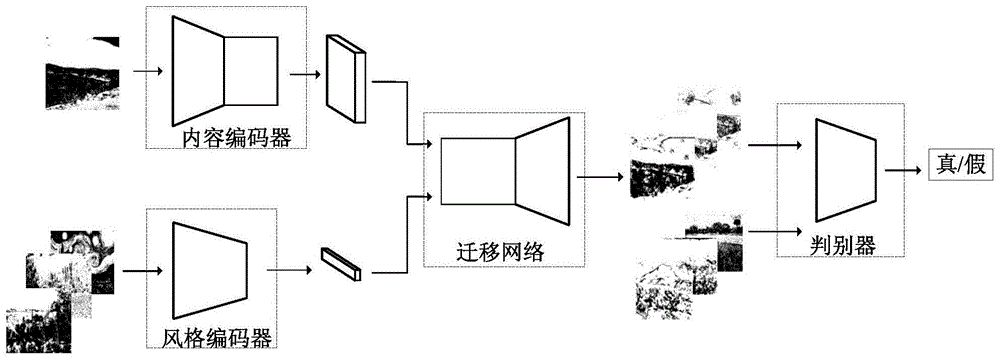
本发明属于计算机视觉领域,涉及一种基于生成对抗网络的多域图像风格迁移方法。
背景技术:
近年来,由深度学习引领的人工智能技术,开始广泛地应用于各个领域。其中,深度学习与艺术的碰撞,引起了研究者们的高度关注。以相关技术为基础的各种图像处理软件和应用也吸引了海量的用户。其中最核心的就是基于深度学习的图像风格迁移。深度学习可以捕获一个图像的内容并将其与另一个图像的风格相结合,这种技术就称为风格迁移。
风格迁移问题源于非照片般逼真的渲染(kyprianidisje,collomossej,wangt,etal.stateoftheart:ataxonomyofartisticstylizationtechniquesforimagesandvideo.tvcg,2013.),并且与纹理合成和转移密切相关(efrosaa,freemanwt.imagequiltingfortexturesynthesisandtransfer.insiggraph,2001.)。一些早期方法包括线性滤波器响应的直方图匹配和非参数采样。这些方法通常依赖于低级统计信息,并且通常无法捕获语义结构。
gatys等人首次通过匹配dnn的卷积层中的特征统计来展示令人印象深刻的样式迁移结果(gatysla,eckeras,bethgem.imagestyletransferusingconvolutionalneuralnetworks.incvpr,2016.)。li和wand在深度特征空间中引入了基于马尔可夫随机场(mrf)的框架来强制执行局部模式(lic,wandm.combiningmarkovrandomfieldsandconvolutionalneuralnetworksforimagesynthesis.incvpr,2016.)。ruder等人通过施加时间约束来改善视频风格迁移的质量(ruderm,dosovitskiya,broxt.artisticstyletransferforvideos.ingcpr,2016)。
gatys等人的框架基于缓慢优化过程,该过程迭代地更新图像来最小化由损失网络计算的内容损失和风格损失。即使使用现代gpu,也可能需要几分钟才能收敛。因此,移动应用中的设备上处理太慢而不实用。常见的解决方法是使用前馈神经网络来替换优化过程,该网络是训练来最小化相同目标损失的(johnsonj,alahia,fei-feil.perceptuallossesforreal-timestyletransferandsuper-resolution.ineccv,2016.)。这些前馈式传输方法比基于优化的替代方案快三个数量级,为实时应用打开了大门。
ulyanov等人提出了改善生成样本的质量和多样性的方法(ulyanovd,vedaldia,lempitskyv.improvedtexturenetworks:maximizingqualityanddiversityinfeed-forwardstylizationandtexturesynthesis.incvpr,2017.)。然而,上述前馈方法在每个网络都与固定风格相关联的意义上受到限制。为了解决这个问题,dumoulin等人引入了一个能够编码32种风格及其插值的网络(dumoulinv,shlensj,kudlurm.alearnedrepresentationforartisticstyle.iniclr,2017)。但是,上述方法无法适应训练期间未观察到的任意风格。
最近,chen和schmidt引入了一种前馈方法,可以通过风格交换层传输任意风格(chentq,schmidtm.fastpatch-basedstyletransferofarbitrarystyle.arxivpreprintarxiv:1612.04337,2016.)。在给定内容和风格图像的特征激活的情况下,风格交换层以逐个补丁的方式用最接近匹配的风格特征替换内容特征。然而,他们的风格交换层创造了一个新的计算瓶颈:对于512*512的图片来说,超过95%的计算花费在风格交换上。
风格迁移的另一个核心问题是使用何种风格损失函数。gatys等人的原始框架通过匹配由gram矩阵捕获的特征激活之间的二阶统计来匹配风格。
其他提出的有效的损失函数,例如mrf损失,对抗性损失,直方图损失以及通道均值和方差之间的距离。注意,所有上述损失函数旨在匹配风格图像和合成图像之间的一些特征统计。
近几年,生成对抗网络(generativeadversarialnetworks,gans)被逐渐应用到图像风格迁移问题上,并且已在风格迁移问题上取得了显著的成绩。如cyclegan利用两组生成器和判别器,通过循环一致性损失,有效地学习了源域和目标域之间的映射和逆映射,并在风格迁移问题上取得了不错的成绩(zhujy,parkt,isolap,etal.unpairedimage-to-imagetranslationusingcycle-consistentadversarialnetworks.iniccv.2017,2242-2251.)。
但是,cyclegan存在一个重要的问题,就是输出缺乏多样性,只能模拟确定的分布。而在处理多域风格迁移问题时,需要为每对图像域单独地构建和训练模型。因此,针对这一问题,最近的一些研究提出了几个新的方法和模型。anoosheh等人则在cyclegan的基础上提出了combogan,一种多分量图像转换模型和训练方案,它的资源消耗以及训练所需的时间与域的数量呈线形比例(anoosheha,agustssone,timofter,etal.combogan:unrestrainedscalabilityforimagedomaintranslation.incvpr.2018,783-790.)。
针对上述问题,本发明提出了一种基于gan的多域图像风格迁移方法,用于实现图像从源域到多个目标域的风格迁移。该网络设计了一个专家风格网络,通过一组双向重构损失,来抽取输入的不同目标域的图像中包含各自域独特信息的风格特征编码。同时通过一个迁移网络,结合自适应实例标准化(adaptiveinstancenormalization,adain),将抽取到的风格特征编码与源域图像的语义信息重新组合,生成新的图像,从而实现图像从源域到多个目标域的风格迁移。实验表明模型能够有效地将任意照片的内容与众多艺术品的风格相结合,产生新的图像。
技术实现要素:
在风格迁移任务中,关键的两点是如何有效地学习到图像的风格信息,以及如何有效地将风格信息融合到图像的语义信息中。针对这两个问题,本发明提出一种基于gan的多域图像风格迁移方法,用于实现图像从源域到多个目标域的风格迁移。该方法充分发挥了gan的优势,借助一组双向重构损失和自适应实例标准化,成功地将照片的内容与众多艺术品的风格相结合,产生新的图像。
本发明的技术方案:
一种基于生成对抗网络的多域图像风格迁移方法,包括如下步骤:
步骤一图像的预处理:通过python的图像处理模块,对真实图像xi,i=1,2,...,n进行统一的处理,并把它们缩放为统一的像素大小。特别注意的是,将真实图像x1称为真实的源域图像,将真实图像xi,i=2,...,n称为真实的目标域图像。
步骤二提取语义内容:将真实的源域图像x1输入到内容编码器ec中。ec通过解码真实的源域图像x1,抽取出在迁移过程中共享的语义内容,即内容特征c1=ec(x1)。
步骤三提取风格特征:将真实图像xi,i=1,2,...,n分别输入到风格编码器es中。es通过解码图像,抽取出包含各个域独特信息的风格特征si=es(xi),i=1,2,..,n。
步骤四生成图像:将抽取出的内容特征c1和抽取出的风格特征si输入到迁移网络t中,迁移网络将内容特征与风格特征重新组合,生成新的图像,该图像具有真实的源域图像x1的内容特征和真实图像xi,i=1,2,...,n的风格特征。同时,我们从高斯分布中随机采样风格特征sri,同样将内容特征c1和随机采样来的风格特征sri输入到迁移网络t中,生成新的图像。
步骤五判别图像:将步骤四中生成的两种新的图像均输入判别器d进行判别,判别器将区分输入图像是真实图像,还是风格迁移后的图像。
步骤六计算损失函数:为了学习风格编码器es、内容编码器ec和迁移网络t,我们使用一组双向重构损失,即自重构损失
其中,i=2,..,n,x1是真实的源域图像,p(x1)是x1的分布,c1是内容特征,p(c1)是c1的分布,sri是随机采样的风格特征,q(sri)是sri的分布,服从高斯分布。
此外,我们使用生成对抗损失
其中,i=2,..,n,si是抽取出的风格特征,p(si)是si的分布,xi是真实的目标域图像,p(xi)是xi的数据分布,d(xi)表示判别真实图像。
步骤七网络优化及参数调整:模型通过一个联合损失函数l(ec,es,t,d),采用adam优化算法,更新ec,es,t和d的网络参数。
其中,λ1,λ2,λ3,λ4为超参数。
步骤八重复t次步骤二至步骤七。
步骤九测试阶段,将真实的源域图像x1输入内容编码器,将任意的真实的目标域图像xi输入风格编码器,经过迁移网络t转换后,即可得到具有源域内容与目标域风格的图像。
本发明的有益效果:基于gan的多域图像风格迁移方法充分发挥了gan的优势,借助一组双向重构损失和自适应实例标准化,该模型能够稳定地进行训练,并成功地将照片的内容与众多艺术品的风格相结合,产生新的图像。
附图说明
图1是基于生成对抗网络的多域图像风格迁移方法示意图;
图2是风格编码器的结构示意图;
图3是迁移网络的结构示意图;
图4基于生成对抗网络的多域图像风格迁移方法的结果样例。其中(a)和(d)是提供内容的真实的源域图像,(b-1)、(b-2)、(b-3)和(e-1)、(e-2)、(e-3)分别是提供风格的真实的目标域图像,(c-1)、(c-2)、(c-3)和(f-1)、(f-2)、(f-3)分别是结合了对应内容和风格的迁移结果。
具体实施方式
本发明提供一种基于生成对抗网络的多域图像风格迁移方法。所论述的具体实施例仅用于说明本发明的实现方式,而不限制本发明的范围。下面结合附图对本发明的实施方式进行详细说明,具体包括以下步骤:
1.图像的预处理:以将照片转换到具有莫奈、浮世绘和梵高风格的迁移任务为例。从真实数据分布xi,i=1,2,3,4中采样得到真实图像xi,其中,我们将真实图像x1称为真实的源域图像,即像素大小为256*256的真实场景的照片;将真实图像xi,i=2,3,4称为真实的目标域图像,即像素大小为256*256的莫奈、浮世绘和梵高的作品。使用python的图像处理模块,对真实的源域图像x1和真实的目标域图像xi,i=2,3,4进行统一的处理,同时对图像像素值进行了归一化处理。
2.提取语义内容:将归一化好的真实的源域图像x1输入到内容编码器ec中。ec通过解码x1,抽取出在迁移过程中,在不同域之间保持不变的语义内容,即内容特征c1=ec(x1),包含对象的类别、形状和空间布局等公共信息。
3.提取风格特征:将真实的源域图像x1和真实的目标域图像xi,i=2,3,4分别输入到风格编码器es中。es通过解码真实图像,抽取出包含各个域独特信息,如颜色和纹理的风格特征si=es(xi),i=1,2,..,n。我们将风格特征的大小设置为8维。
风格编码器es的结构如图2所示。首先是一个通道数为64,步长为2的卷积层,接着是3个下采样是平均池化层的残差块,通道数如图所示,其中激活函数均采用leakyrelu,其斜率设为0.2。之后是一个全局平均池化层(globalaveragepooling,gap),一个全连接层(fullyconnectedlayer,fc),最后输出一个8维的风格特征向量。
4.生成图像:将抽取出的内容特征c1和抽取出的风格特征si输入到迁移网络t中,迁移网络将内容特征与风格特征重新组合,生成新的图像x1→i=t(c1,si),该图像具有真实的源域图像x1的内容特征和真实图像xi,i=1,2,...,n的风格特征,大小为256*256。同时,我们从高斯分布中随机采样风格特征sri,同样将内容特征c1和随机采样来的风格特征sri输入到迁移网络t中,生成新的图像,大小同样为256*256。
受最近在标准化层中使用仿射变换参数来表示风格样式的工作的启发,我们在t的残差块中应用了adain层,通过风格特征来标准化内容特征,从而生成目标特征图。最后通过上采样将目标特征图解码得到输出图像。由于不同的仿射参数以不同的方式标准化特征统计,通过使用不同目标域中的图像作为输入,我们可以将源域中的图像转换为具有不同风格的图像。
迁移网络t的结构图如图3所示。首先是4层具有adain的残差块,之后是3层反卷积层,每层的通道数和步长如图所示。
5.判别图像:将步骤四中生成的两种新的图像均输入判别器d进行判别,判别器将区分输入图像是真实图像,还是风格迁移后的图像。我们采用wang等人提出的多尺度判别器(wangtc,liumy,zhujy,etal.high-resolutionimagesynthesisandsemanticmanipulationwithconditionalgans.incvpr.2018,8798-8807.)。通过3个结构相同的判别器d1,d2和d3在不同尺度对图像进行判别,来引导迁移网络t生成具有逼真的细节和正确的全局结构的图像。具体来说,将真实图像和生成的图像下采样2倍和4倍,以创建3个尺度的图像金字塔。然后训练判别器d1,d2和d3以分别在3个不同的尺度上区分真实图像和生成图像。
6.计算损失函数:为了学习风格编码器es、内容编码器ec和迁移网络t,我们使用一组双向重构损失,即自重构损失
对于从给定数据分布中采样的图像,我们应该能够在编码和解码之后重建它。因此,我们首先设计了一个自重构损失
其中,x1是真实图像,p(x1)是真实图像x1的分布。
对于给定的内容特征c和从先验分布中采样的风格特征sr,我们应该能够在解码和编码之后重构它们。因此,我们设计了一组内容特征重构损失
其中,i=2,..,n,c1是内容特征,p(c1)是内容特征的分布,sri是随机采样的风格特征,q(sri)是sri的分布,服从高斯分布。
内容重构损失鼓励转换后的图像保留输入图像的语义内容。而风格重构损失则鼓励图像和隐空间之间的可逆映射,同时,采用不同的风格特征编码有助于鼓励多样化的输出。
此外,我们使用生成对抗损失
其中,i=2,..,n,si是抽取出的风格特征,p(si)是si的分布,d(xi)表示判别真实图像。
7.网络优化及参数调整:所有网络模块,包括内容编码器、风格编码器、迁移网络和判别器,通过一个联合损失函数l(ec,es,t,d),采用adam优化算法,更新ec,es,t和d的网络参数,其中,学习率设置为0.0001,指数衰减率β1=0.5,β2=0.999。
其中,λ1,λ2,λ3,λ4为超参数,考虑到各损失项的数量级不同,为了使各项均发挥作用,我们将超参数进行了适当的设置:λ1=1,λ2=100,λ3=10,λ4=10。
8.重复t次步骤2至步骤7。
9.测试阶段,将真实的源域图像x1,如图4中的(a),输入内容编码器,将任意的真实的目标域图像xi,如图4中的(b-1),输入风格编码器,经过迁移网络t转换后,即可得到具有源域内容与目标域风格的图像,如图4中的(c-1)。
- 还没有人留言评论。精彩留言会获得点赞!