一种新型的基于GRU注意力机制的答案选择模型的制作方法
本发明涉及自然语言处理领域,即一种用于问答系统答案选择模型中选择最优回复的算法。
背景技术:
答案选择(answerselection,as)是问答系统设计中一个重要子任务,它的功能是对于一个给定的问题能够从一系列候选回复中选出一个最佳的答案。在对话过程中答案选择的准确性对问答系统的性能起着关键性的影响。在过去几年中,answerselection被广泛关注。其中,用神经网络模型解决答案选择任务取得了巨大的成功。但是通过循环神经网络生成语义向量的时候是对问题和答案单独编码的,忽略掉了答案中与问题有联系部分的信息,导致生成的答案语义向量不仅丢失了有用信息并且参杂一些无用的噪声。后来将注意力机制引入问答模型中,端到端的注意力机制,在该问题上取得了最好的结果。端到端的attention计算了答案和问题之间的词语权重。然而,由于rnn算法用于处理时序特征的特点,隐含状态迭代更新,因此t时刻隐藏状态包含t时刻以及t时刻之前的所有隐藏状态的信息。加入问题的注意力信息目的是用于找出候选答案中包含信息最多的部分,因此越靠后的隐藏状态越容易被选择。综上所述,传统的attention机制更加偏向于后面的状态特征。后来有人提出内部注意力机制,通过把注意力机制作用到gru网络内部的‘门’上同样可以达到对信息进行筛选和过滤的目的,从而避免出现权重分配偏差问题。我们把传统的注意力机制模型称为oarnn,把注意力机制作用在‘门’上的模型称为iarnn-gate。iarnn-gate没有对输入信息进行筛选,这会导致在候选输出隐藏状态中包含较多的噪声,只通过gru内部的一个更新门难以将噪声全部去除。
技术实现要素:
本发明旨在至少解决上述技术问题之一。
为此,本发明的目的在于提出一种新型的基于gru的注意力机制的答案选择模型,该模型考虑在循环神经网络内部新增一个‘门’,即输入门。并把注意力向量作为这个‘门’的输入,通过这个新增的‘门’来对输入信息进行筛选,保留有用的信息,然后把进过筛选的输出作为新的输入。在question-encoder模块的gru网络中加入输入门相当于为gru网络添加了自注意能力,能够让输入的问句通过自身来对问句中的细粒度信息进行筛选、过滤,使得最后得到的语义表示中关键信息的比重更大,语义表示更准确,而这个语义表示又要作为注意力向量来对候选答案中的信息进行筛选,因此使得对候选答案的筛选更加精确。在answer-encoder模块中,将候选答案输入到输入门之后经过内部注意力机制的gru网络,改进后的模型,在insuranceqa数据集上取得了很好的效果。
为了实现上述目的,本发明的技术方案为:
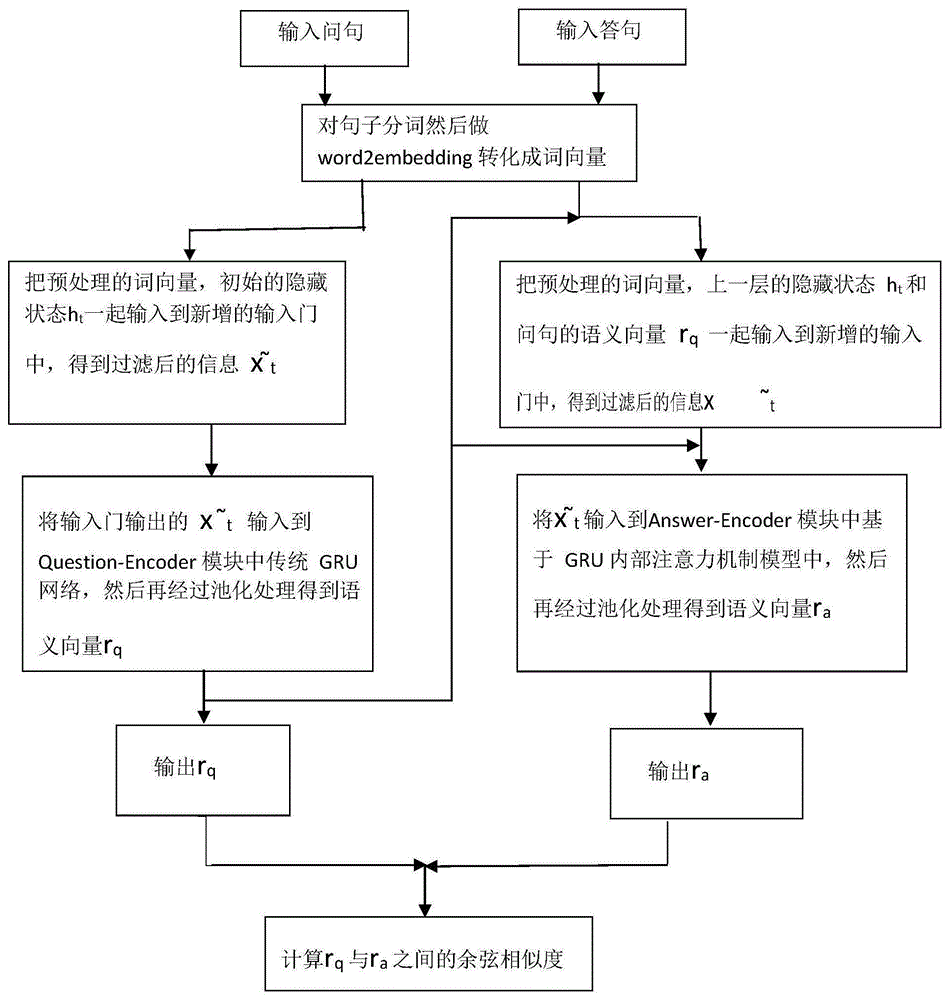
一种新型的基于gru注意力机制的答案选择模型,包括如下步骤:
s1.问句xt经过输入门ft来对输入进行信息筛选和过滤,将过滤的信息输入到gru网络中;
s2.过滤后的信息经过gru网络和池化后产生一个语义向量rq,把这个语义向量rq作为attention向量;
s3.把候选答句xt、上一时刻的隐藏状态ht-1和注意力向量rq输入到输入门ft中,得到输出
s4.经过输入门的信息输入到gru网络,引入上面的attention向量rq,通过重置门rt和更新门zt,得到输出ht。
s5.候选答句经过gru网络池化层后同样的得到一个语义向量ra;
s6.计算问句的rq和答句的ra之间的余弦相似度;
s7.选择相似度最大的候选答案作为最后的的回复。
与现有技术相比,本发明的有益效果是:
1)本发明提供的方法,通过在gru内部新增加一个门,对输入信息进行筛选和过滤,保留有用信息且去除多余的噪声,提出了一种新的注意力机制。
2)本发明提供的方法,通过使用这种新增加一个输入门的gru内部注意力机制对问答系统中的答案选择模型做出了改进,精确度比原来iarnn-gate模型在insuranceqa数据集中提高了2.1个百分点。
3)本发明提供的方法,可应用于电商平台的智能客服系统下,在精确度、算法稳定度等方面有较大的改进提高,能够更好地适用于实际工程工作中。
附图说明
图1根据本发明实施例的一种新型的基于gru注意力机制的答案选择模型的流程
图2根据本发明一个实施例的循环神经网络rnn的结构示意图
图3根据本发明一个实施例的传统gru的结构示意图
图4根据本发明一个实施例的基于内部注意力机制的gru的结构(iarnn-gate)示意图
图5根据本发明一个具体实施例的一种新型基于gru的注意力机制的答案选择模型在question-encoder端的网络结构示意图
图6根据本发明一个具体实施例的一种新型基于gru的注意力机制的答案选择模型在答句的answer-encoder端的网络结构示意图
具体实施方式
附图仅用于示例性说明,不能理解为对本专利的限制;
以下结合附图和实施例对本发明做进一步的阐述。
实施例1
图1是根据本发明一个实施例的循环神经网络rnn的结构示意图。循环神经网络可以表示成一种函数,普通形式的神经网络可以分为输入层、隐藏层以及输出层。隐藏层无论内部有几层,在整体上都可以抽象成一个大的隐藏层。隐藏层同样可以表示为一个函数的形式,这个函数以输入层的数据作为自变量,通过计算得到输出因变量。输出层同样是一个函数,它以隐藏层的因变量输出作为自变量输入。rnn在许多自然语言处理任务中都有重要的应用,rnn在语言模型、文本生成、机器翻译、语言识别和图像描述生成等任务中都取得了很不错的效果。
根据图1的结构示意图,循环神经网络在t时刻从输入层输入xt之后,隐藏层的值更新为st,同时输出ot,其中,st的值不仅取决于xt,同时还与st-1有关。循环神经网络中t时刻的隐藏状态和输出的计算公式如下:
ot=g(vst)
st=f(uxt+wst-1)(1)
图2是根据本发明一个实施例的传统gru的结构示意图。gru(gatedrecurrentunit)是lstm网络的一个改进模型,gru网络将lstm中的遗忘门和输入门组成了一个新的门—更新门,同时还把细胞状态和隐藏状态结合在一起传输。gru模型比标准的lstm模型要简单,而且效果也很好。它可以解决rnn网络中的长依赖问题。
根据图2的结构示意图,图中的zt和rt分别表示更新门和重置门。更新门用于筛选出前一时刻的状态信息中有用的部分输入到当前状态中,更新门的值越大说明前一时刻的状态中有越多的信息进到当前时刻。重置门用于筛选出前一状态中信息写入到当前的候选状态
rt=σ(wxrxt+whrht-1)
zt=σ(wxzxt+whzht-1)
yt=σ(wo·ht)
图3是根据本发明的一个实施例的基于内部注意力机制的gru的结构(iarnn-gate)示意图。此模型的answer-encoder模块中,通过把注意力机制作用到gru网络内部的‘门’上可以达到对信息进行筛选和过滤的目的,从而避免出现权重分配偏差问题。
根据图3的结构示意图,基于内部注意力机制的gru的结构(iarnn-gate),相对于传统的gru模型,此模型在question-encoder模块生成的语义向量rq当作注意力向量来对重置门和更新门的输出rt和zt进行改进,基于内部注意力机制的gru(iarnn-gate)网络的前向传播公式如下:
rt=σ(wxrxt+whrht-1+mqrrq)
zt=σ(wxzxt+whzht-1+mqzrq)
yt=σ(wo·ht)
本发明提出的方法具体步骤如下:
a)问句经过输入门ft之后得到
其中,步骤a)的具体做法为:
实验之前首先对问题和答案进行数据清洗,生成神经网络能够使用的数据,即将问题和候选答案切分成单词,然后采用word2vec对切割后的单词训练生成词向量。
将输入信息xt和前一个隐藏状态ht-1经过一个σ门函数,得到输入门ft用来更新输入信息。将前一时刻的隐藏状态引入到输入信息中,可以去除输入信息中的无用信息并且保留有关信息,涉及到的公式如下:
ft=σ(wxfxt+whfht-1+bf)
其中,wxf、whf和bf为网络参数,原来的网络结构相比较,在question-encoder端新增一个输入‘门’,对输入信息进行初步筛选,相当于为gru网络添加了自注意能力,在经过gru网络内部又通过一个更新们来对网络中的信息进行筛选,这相当于对输入信息进行了双重筛选,使得本发明提出的模型能更准确的生成的语义表示。
b)输入
其中,步骤b)的具体做法为:
把问句经过输入门由公式(4)得到输出
其中,rq,i表示rq的第i个元素,yt,i表示yt的第i各元素;
c)答句经过问句模块的输入门
其中,步骤c)的具体做法为:
实验之前首先对答句进行数据清洗,生成神经网络能够使用的数据,即将答句切分成单词,然后采用word2vec对切割后的单词训练生成词向量。
然后将经过分词和词嵌入后的答句xt,输入到本模型中新加的输入门
其中
d)把
其中,步骤d)的设计的公式为:
其中mqrrq表示两个矩阵相乘,rt⊙ht-1表示两个矩阵的点乘操作。
e)gru网络的输出ht经过池化层后得到一个语义向量ra。
其中,步骤e)的具体做法为:
把gru网络的输出ht输入池化层,利用平均池计算出问题的表示,根据公式(5),得到一个语义向量ra。
f)计算问句的rq和答句的ra之间的余弦相似度。
其中,步骤f)的具体做法为:
计算rq与ra之间的余弦相似度,计算公式如下:
θqa越大,表示向量rq与ra之间夹角越小,说明问句与答句的语义越相近;θqa越小,表示向量rq与ra之间夹角越大,说明问句与答句的语义相差越大。
假设q代表问句,a+代表正例答案,a-代表负例答案,本模型的目标函数如下:
其中,n表示所有负例答案的集合,m表示边界,cos表示计算得分的余弦相似度函数
实施例
本发明对上述方法基于gru内部的注意力机制模型进行了精确度比较与分析实验,具体如下:
本次实验采用insuranceqa数据集和wikiqa数据集。
首先使用insuranceqa数据集,insuranceqa数据集分为训练集、验证集和测试集三部分,其中测试集分为两个小测试集(test1和test2)。每部分都是相同的组成格式:每个问题-答案对由1个问题和11个答案组成,其中11个答案包括1个正确答案和10个干扰答案。在模型训练阶段,对于训练集中的每一个问题,随机从相应的10个干扰答案中选择一个作为训练时的干扰答案;在测试阶段,会计算每一个问题和它对应的11个答案之间的相似度得分。实验之前首先对问题和答案按字切词,然后采用word2vec对问题和答案进行预训练得到100维的词向量。
实验建模生成输入数据。本次实验采用问答三元组的形式进行建模(q,a+,a-),q代表问题,a+代表正向答案,a-代表负向答案。insuranceqa里的训练数据已经包含了问题和正向答案,因此需要对负向答案进行选择,实验时我们采用随机的方式对负向答案进行选择,组合成(q,a+,a-)的形式。将问题和答案进行embedding(batch_size,sequence_len,embedding_size)表示。
然后根据传统的gru模型计算问题的特征rq,根据公式(4)和公式(6)分别question-encoder模块增加输入门、answer-encoder模块增加输入门。将加入自注意力机制的输入问题的特征rq和经过输入门的答案的输入根据公式(6)和公式(7)的计算出ra,采用max-pooling的方式获得最后的特征。最后根据问题和答案最终计算的特征,计算目标函数余弦相似度。
insuranceqa数据集上的参数设置如下:本实验的优化函数使用随机梯度下降(sgd),学习率设为动态学习速率,训练150轮,参数m是预定义的边距,本实验设置为0.2,batch_size为32,问题长度保持30字、答案100字,本实验在答案选择模型中所使用的循环神经网络均为双向网络,隐藏层的神经元个数rnn_size设置为201,字预训练采用100维。
通过上述参数的设置,本发明的算法和基于gru内部注意力机制算法在insuranceqa数据集上的对比结果如表1所示。
表1新型的基于gru注意力机制模型在insuranceqa数据集上的实验结果
在wikiqa数据集上的实验,该数据集同样被分为训练集、验证集和测试集三部分。wikiqa数据集上实验参数设置为:首先采用word2vec对问题和答案进行预训练得到100维的词向量;设置词向量在训练过程中可以不断更新;使用sgd算法作为优化算法;损失函数和insuranceqa数据集中使用的损失函数一样,其中的预定义边距m设置为0.1;学习率设为动态学习速率,训练150轮,batch_size为32,问题长度保持30字、答案100字,本实验在答案选择模型中所使用的循环神经网络均为双向网络,隐藏层的神经元个数rnn_size设置为201。由于wikiqa测试集中每个问题对应的正确答案不止一个,所以实验采用map(平均精度均值)和mrr(平均倒数排名)这两个评价指标来测试模型。
通过上述参数的设置,本发明的算法和基于gru内部注意力机制模型在wikiqa数据集上的实验结果如表2所示。
表2新型的基于gru注意力机制模型在wikiqa数据集上的实验结果
从表1中可以看出,对于insuranceqa的两个测试集,本文所提出的一种改进的基于gru内部注意力机制的模型在r10@1这一评价指标上比改进之前的模型提高了大约2.1%和大约1.8%。从表2中可以看出,对于wikiqa数据集,本文所提出的一种改进的基于gru内部注意力机制的模型,在map和mrr这两个评价指标上比改进前的模型提高了大约1.86%和大约1.91%。在insuranceqa数据集和wikiqa数据集上的测试结果表明改进后的模型确实起到实际效果,本专利中提出的改进的基于gru内部注意力机制模型对输入信息的筛选能力更强,能过滤更多的无用信息。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。对于所属领域的普通技术人员来说,在上述说明的基础上还可以做出其它不同形式的变化或变动。这里无需也无法对所有的实施方式予以穷举。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!