应用专利数据库的研发辅助系统及其方法与流程
本发明涉及一种研发辅助系统及其方法,特别是根据专利分类号或技术元素信息建立关联规则并获得相应的关联规则强度,用以产生有助于研发的建议。
背景技术:
近年来,随着智慧财产权的普及与蓬勃发展,各种以专利数据库为基础的相关应用便如雨后春笋般出现,如:专利地图分析、专利数据挖掘及专利价格鉴定等等。
一般而言,传统专利数据库的运用大多朝向巨量分析的视觉化、机器学习、深度学习、语意分析的研究方向发展。然而,对于大数据的数据挖掘来说,信息科学在专利数据库的运用上,大多朝向企业并购与智慧资本的高度需求来加以呈现,鲜少关注在研发体系的实质应用。另一方面,视觉化软体呈现专利数据的美化与互动性,往往对研发人员的参考意义不大。再者,企业智慧财产权(intellectualproperty,ip)的发展大多由法务领域的人员主导与管理,针对其领域的需求大多限制在专利检索的比对性,所以专利分析跨越至研发人员的需求往往无法在一般的企业中被彰显出来,因此,也限制了专利分析的完整发展,导致研发人员无法将专利分析融入开发的工作流程中,例如:无法从专利分析中得到组合不同技术的点子,或是在遭遇竞争对手的专利阻碍时,无法获得用于无效比对推论的前案建议,故具有应用专利数据库辅助研发的实用性不佳的问题。
有鉴于此,便有厂商提出应用人工智慧建立技术功效矩阵图的技术,提供研发者了解技术聚集点以及技术空白点,进而规避技术热点而发现新的研发方向。然而,此方式需要耗费大量的计算机运算能力,而且无法呈现不同技术的结合可能性及关联性,所以容易导致研发者在单一技术手段中钻牛角尖,对研发者而言获得的帮助十分有限,难以直接根据技术功效矩阵图来思考出具可专利性的技术,或是做为专利无效推论的论证基础,因此仍然无法有效解决应用专利数据库辅助研发的实用性不佳的问题。
综上所述,可知先前技术中长期以来一直存在应用专利数据库辅助研发的实用性不佳的问题,因此实有必要提出改进的技术手段,来解决此问题。
技术实现要素:
本发明公开一种应用专利数据库的研发辅助系统及其方法。
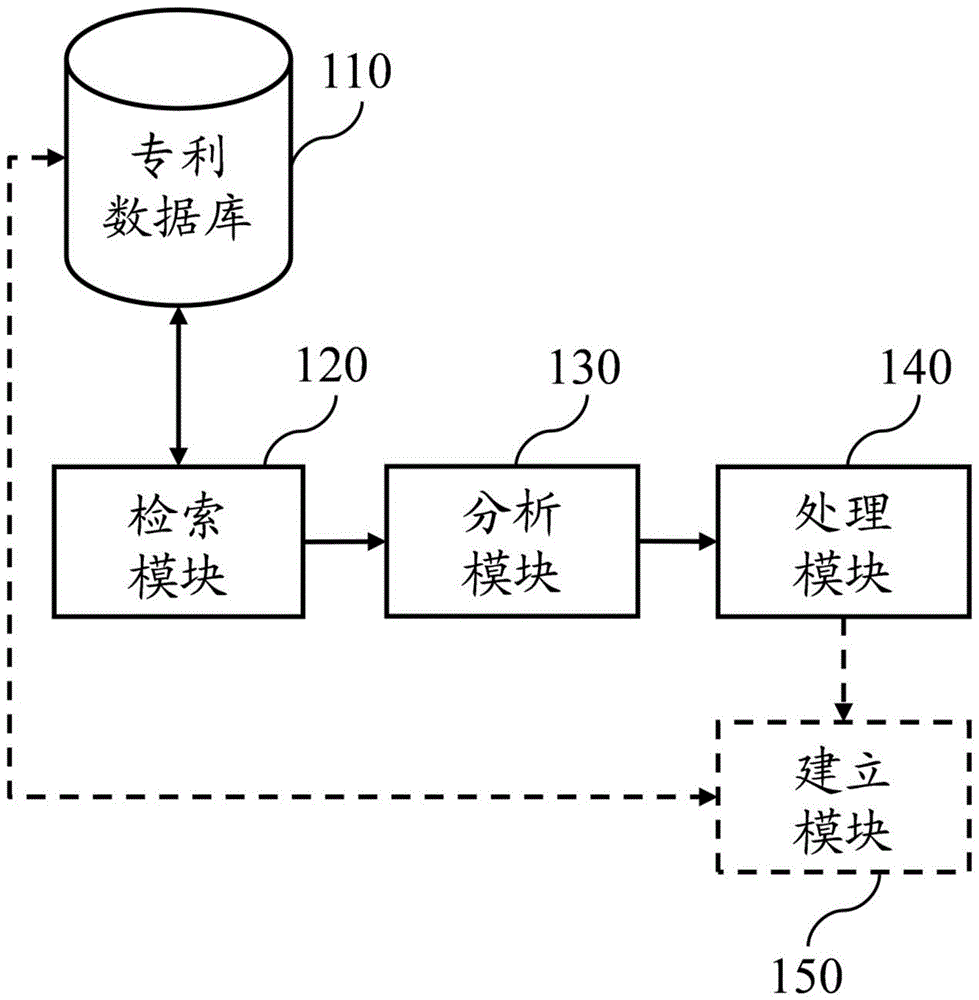
首先,本发明公开一种应用专利数据库的研发辅助系统,此系统包含:专利数据库、检索模块、分析模块及处理模块。其中,专利数据库用以储存专利文件,每一专利文件皆包含专利分类号;检索模块用以提供键入检索条件,并且将键入的检索条件传送至专利数据库以进行专利检索,查询出符合检索条件的专利文件;分析模块用以载入查询出的专利文件,并且以关联规则演算法分析载入的专利文件的专利分类号,以及根据分析结果建立关联规则,每一关联规则包含至少二个专利分类号及一个关联规则强度;处理模块用以选择关联规则强度为弱的关联规则,将其中的专利分类号进行组合以输出为衍生专利建议,以及选择关联规则强度为强的关联规则,将其中的专利分类号进行组合以输出为专利无效推论建议。
另外,本发明公开一种应用专利数据库的研发辅助方法,其步骤包括:在专利数据库中储存专利文件,每一专利文件皆包含专利分类号;提供键入检索条件,并且将键入的检索条件传送至专利数据库以进行专利检索,查询出符合检索条件的专利文件;载入查询出的专利文件,并且以关联规则演算法分析载入的专利文件的专利分类号,以及根据分析结果建立关联规则,每一关联规则包含至少二个专利分类号及一个关联规则强度;以及选择关联规则强度为弱的关联规则,将其中的专利分类号进行组合以输出为衍生专利建议,以及选择关联规则强度为强的关联规则,将其中的专利分类号进行组合以输出为专利无效推论建议。
接着,本发明公开一种应用专利数据库的研发辅助系统,此系统包含:专利数据库、检索模块、分析模块、关联模块及处理模块。其中,专利数据库用以储存专利文件;检索模块用以提供键入检索条件,并且将键入的检索条件传送至专利数据库以进行专利检索,查询出符合检索条件的专利文件;分析模块用以载入查询出的专利文件,并且对载入的每一专利文件的内容分别进行自然语言处理及语意分析,以及根据文字挖掘分别产生对应每一专利文件的技术元素信息;关联模块用以执行关联规则演算法以分析所有产生的技术元素信息,并且根据分析结果建立多个关联规则,其中,每一关联规则包含至少二个技术元素信息及一个关联规则强度;处理模块用以选择关联规则强度为弱的关联规则,将其中的技术元素信息进行组合以输出为具有可专利性的研发建议,以及选择关联规则强度为强的所述关联规则,将其中的技术元素信息进行组合以输出为专利无效推论建议。
接下来,本发明公开一种应用专利数据库的研发辅助方法,其步骤包括:在专利数据库中储存专利文件;提供键入检索条件,并且将键入的检索条件传送至专利数据库以进行专利检索,查询出符合检索条件的专利文件;载入查询出的专利文件,并且对载入的每一专利文件的内容分别进行自然语言处理及语意分析,以及根据文字挖掘分别产生对应每一专利文件的技术元素信息;执行关联规则演算法以分析所有产生的技术元素信息,并且根据分析结果建立多个关联规则,其中,每一关联规则包含至少二个技术元素信息及一个关联规则强度;以及选择关联规则强度为弱的关联规则,将其中的技术元素信息进行组合以输出为具有可专利性的研发建议,以及选择关联规则强度为强的关联规则,将其中的技术元素信息进行组合以输出为专利无效推论建议。
本发明所公开的系统与方法如上,与先前技术的差异在于本发明是通过载入与检索条件相符的专利文件,并且直接根据专利分类号或产生对应各专利文件的技术元素信息,结合关联规则演算法对载入的专利文件进行分析,以便建立包含专利分类号或技术元素信息,以及包含关联规则强度的关联规则,接着选择关联规则强度为弱/强的关联规则,将其包含的专利分类号或技术元素信息进行组合以输出能够辅助研发的建议。
通过上述的技术手段,本发明可以达成提高应用专利数据库辅助研发的实用性的技术功效。
附图说明
图1为本发明应用专利数据库的研发辅助系统的系统方块图。
图2为本发明应用专利数据库的研发辅助方法的方法流程图。
图3为本发明应用专利数据库的研发辅助系统的另一系统方块图。
图4为本发明应用专利数据库的研发辅助方法的另一方法流程图。
图5a为应用本发明产生衍生专利建议的示意图。
图5b为应用本发明产生研发建议的示意图。
图6a为应用本发明产生专利无效推论建议的示意图。
图6b为应用本发明产生专利无效推论建议的另一示意图。
【附图标记列表】
110、310专利数据库
120、320检索模块
130、330分析模块
140、350处理模块
150、360建立模块
340关联模块
511、551、611、651输入区块
521、561第一显示区块
522、562第二显示区块
530、570、630、670建议区块
620、660显示区块
具体实施方式
以下将配合附图及实施例来详细说明本发明的实施方式,通过对本发明如何应用技术手段来解决技术问题并达成技术功效的实现过程能充分理解并据以实施。
在说明本发明所公开的应用专利数据库的研发辅助系统及其方法之前,先对本发明所自行定义的名词作说明,本发明所述的关联规则强度是指在同一关联规则中的相关联元素(即:「专利分类号」或「技术元素信息」)彼此之间的连结强弱,如:强连结或弱连结,举例来说,当这些元素频繁出现的次数大于某一预设值可代表关联规则强度为强,或称之为强连结;反之则代表关联规则强度为弱,或称之为弱连结。在数据挖掘的领域之中,关联规则(associationrule)分析是最常被使用的方法,其方法则大致是『if前项antecedent(s)then后项consequent(s)』的概念,目的在于找出数据库中数据间彼此的关联性。本发明所述的技术元素信息中记录了技术元素,如:技术名称、技术分类或技术领域等等。举例来说,「类神经网络」、「影像处理」或「信息安全」等等,皆可称之为技术元素,而记载技术元素的信息即为技术元素信息,广义而言,专利分类号也可视为技术元素。
以下配合附图对本发明应用专利数据库的研发辅助系统及其方法做进一步说明,请先参阅图1,图1为本发明应用专利数据库的研发辅助系统的系统方块图,此系统包含:专利数据库110、检索模块120、分析模块130及处理模块140。其中,专利数据库110用以储存专利文件,每一专利文件皆包含专利分类号。在实际实施上,专利数据库110可以是各国家/地区的专利专责机构所设置的专利数据库,也可以是民间单位、组织或个人所自行建立的专利数据库,假设是自行建立的专利数据库,其中储存的专利文件可直接向各国家/地区的专利专责机构定期购买及更新。特别要说明的是,每一篇专利文件所标注的专利分类号,是专利专责机关的专业审查委员在核准专利申请之前,所界定的完整技术方案的总结技术元素,也就是说,是通过审查委员的专业总结出所涉及的不同技术组合。因此,只要得知专利分类号,无须浏览整篇专利便可快速且精确地得知专利所属的技术领域。以美国专利公告号us9,038,127为例,其所属技术为信息安全,特别是针对政策及防止未经授权使用数据(包含防止盗版、侵犯隐私或未经授权的数据修改),因此,审查委员将其专利分类号标注为「726/1」及「726/26」,用以与其所属技术相互呼应,故每一个专利分类号皆可视为一个单独的技术元素,当专利文件同时具有多个专利分类号时,可视为该专利由多个技术元素组合而成。
检索模块120用以提供键入检索条件,并且将键入的检索条件传送至专利数据库110以进行专利检索,以便查询出符合检索条件的专利文件。在实际实施上,使用者键入的检索条件可包含关键字(如:单字、专利分类号、公告号等等)、逻辑运算分子(如:「and」、「or」、「not」等等)及指定检索栏位(如:「@ti」、「/ttl」等等)。举例来说,所述检索条件可为:「物联网anda63f13/32」、「(网络)@ti」、「ttl/network」等等。特别要说明的是,不同的专利数据库110可能使用不同的方式来指定检索栏位,例如:以「@」或「/」来指定检索栏位,其中,以中文专利数据库为例,假设检索条件为「(网络)@ti」,其代表将关键字「网络」的指定检索栏位设为标题;以英文专利数据库为例,假设检索条件为「ttl/network」,其代表将关键字「network」的指定检索栏位设为标题。另外,所述专利分类号可包含美国专利分类号(u.s.patentclassification,upc)、国际专利分类号(internationalpatentclassification,ipc)、合作专利分类号(cooperativepatentclassification,cpc)及日本fi-f-term等等,并且可具有大类(class)及小类(subclass)等层级。
分析模块130用以载入查询出的专利文件,并且以关联规则演算法分析载入的专利文件的专利分类号,以及根据分析结果建立关联规则,每一关联规则包含至少二个专利分类号及一个关联规则强度。在实际实施上,所述关联规则演算法可为应用在数据挖掘的apriori演算法,并且同时搭配多维分析或时序分析以对载入的专利文件的专利分类号进行分析。具体而言,apriori演算法是挖掘高频项目集的布林值关联规则中最具代表性的演算法,随后发展的不同关联规则演算法大多以apriori演算法为基础。其主要概念是在大量的数据集(如:专利文件)中,利用项目集(如:专利分类号)来建立关联规则,并计算每一个候选项目出现的数目,依据所设定的最小支持度为门槛,来衡量候选项目的关联规则是否显著。举例来说,假设有4笔专利文件,每一笔专利文件包含的专利分类号以字母示意如下:
专利文件一,其包含专利分类号a、c、d。
专利文件二,其包含专利分类号b、c、e。
专利文件三,其包含专利分类号a、b、c、e。
专利文件四,其包含专利分类号b、e。
在使用apriori演算法建立关联规则时,会进行高频项目集的集合的搜寻与删除,其步骤如下:
(1)将数据转换为代码或布林值表示的离散数据,在以累进搜寻的方式,从基层的单项专利分类号组合开始建立1-项目集的集合,经第一次扫描后可得c1并计算出各项目集所对应的支持度(以此例而言,1-项目集:{a}至{e},其对应的支持度依序为:0.5、0.75、0.75、0.25、0.75)。接下来比较所得的支持度与所定的支持度门槛s来决定高频项目集,假设支持度门槛s为0.5,那么项目集{d}将因为其支持度仅0.25而被排除,故得到高频1-项目集有{a}、{b}、{c}及{e},将其记为l1。
(2)将高频1-项目集组合成6个2-项目集并记为c2;接着,同样计算其支持度(以此例而言,2-项目集:{a,b}、{a,c}、{a,e}、{b,c}、{b,e}、{c,e},其对应的支持度依序为:0.25、0.5、0.25、0.5、0.75、0.5)。接着,同样根据支持度门槛s决定高频项目集,排除支持度为0.25的项目集{a,b}及{a,e},得到高频2-项目集有{a,c}、{b,c}、{b,e}、{c,e},将其记为l2。
(3)继续累进搜寻,确认包含三个项目的项目集是否也符合高频项目集的特性,由于l2中各项目集在累进搜寻后,仅能找到一个3-项目集,即{b,c,e},故将其记为c3。此处,因为项目集{a,c,e}中的子项目集{a,e}并非高频项目集,所以不须将项目集{a,c,e}列于c3中,而项目集{b,c,e}的子项目集{b,c}、{b,e}、{c,e}皆为高频项目集,所以项目集{b,c,e}也有机会成为高频项目集。接着,计算出其支持度为0.5后,由于未低于支持度门槛s,故得到高频3-项目集为{b,c,e},并记为l3。
(4)接着,利用找到的高频3-项目集{b,c,e}来建立关联规则,在此例中可建立12种可能的关联规则,并依序计算这些规则所对应的支持度与提升度,如下表所示:
其中,支持度(support)代表前项(x)和后项(y)同时出现的概率,其数学式表示为:
接下来,可根据支持度及提升度至少其中之一,从中找出显著的关联规则(如:支持度大于0.5或提升度大于1),并且将显著的关联规则的关联规则强度均设为强(或称之为强连结),以及将非显著的关联规则的关联规则强度均设为弱(或称之为弱连结)。换句话说,所述关联规则强度可依据查询出的专利文件的数量、同时存在相应关联规则所包含的专利分类号的专利文件数量等等来产生相应的强度,假设专利文件的数量为1024笔,关联规则包含的专利分类号为「705」及「2」,则此关联规则的关联规则强度可计算在这1024笔专利文件中,每一笔专利文件同时存在专利分类号「705」及「2」的数量有多少,数量越多代表关联规则强度越强,反之数量越少代表关联规则强度越弱,也就是说,同一关联规则所包含的专利分类号的组合,其同时出现在同一专利文件中的笔数与关联规则强度成正相关。
要补充说明的是,在实现apriori演算法时,技术元素的关联没有一般商场购物篮分析的前项与后项之分,其关联的项目都是实现方案的手段,没有先后之分,除非是明确设定研发人员熟悉的技术元素为前项,来窥探要关联哪一种技术元素为后项的推论(提升度越高的关联规则越好,因为其意味着前项的出现对后项的出现有促进作用),因此,以上例而言,可将「若b则c」及「若c则b」视为同一条关联规则;将「若b则e」及「若e则b」视为同一条关联规则;以及将「若c则e」及「若e则c」视为同一条关联规则,总共得到9种可能的关联规则。另外,若要针对某一专利做无效推论的证据查找的话,则要选择关联规则强度为强的关联规则。反之,若要针对某一技术的创新元素做搜集的话,则离群值的关联规则(或称之为分群的关联规则)的可视化就变得极有意义,因为在庞大专利数据无法人工审阅的情况下,可以直观的探索可组合的异业元素,这是在以往的商场购物篮分析不被采纳的分析方法,因为在传统的关联规则分析中,这些关联规则被视为噪声(noise)而排除。
处理模块140用以将关联规则强度为弱的关联规则中的专利分类号进行组合以输出为衍生专利建议。举例来说,假设关联规则强度为弱的关联规则中,其包含的专利分类号为「e03d」及「h05k」,那么,可将这二个专利分类号的组合作为衍生专利建议,换句话说,衍生专利建议中可以建议研发者在专利分类号「e03d」及「h05k」所各自代表的技术的组合基础上,思考相关的技术或进一步改良的技术手段,此方式容易引导研发者,思考出具有可专利性的技术手段,因为关联规则强度为弱,代表结合这二个技术的专利文件较少,所以在此基础上进行技术思考比较不会与先前技术重复。另一方面,专利审查委员在进行专利审查时,也不容易找到可以用来驳回申请的对比前案,所以能够有效提升专利获准的机率。在实际实施上,所述衍生专利建议可嵌入与组合后的专利分类号相符的专利文件,例如:复制专利文件并合并至衍生专利建议,或以超连结方式将专利文件的号码、名称及储存路径嵌入衍生专利建议。
另外,在实际实施上,本发明的系统还可包含建立模块,用以将每一关联规则的专利分类号作为检索条件,以便自专利数据库110下载相符的专利文件,并且根据不同专利分类号对这些专利文件进行分类及储存以形成技术元素库。换句话说,每一个专利分类号所对应的技术皆可视为技术元素,所述技术元素库中包含多个技术元素,每一个技术元素又具有对应的专利文件。在实际实施上,所述技术元素库会将每一种技术所属的前案专利文件分别收纳在固定的数据夹(folder)之中,例如:以专利分类号作为数据夹名称。如此一来,在尔后需要参考类似的技术元素的前提下,可以直接在不同定义的数据夹中搜寻所有应用元素的不同技术手段与不同的应用场景,而不需要再从专利数据库110反复检索或浪费其它的调研工作。
接着,请参阅图2,图2为本发明应用专利数据库的研发辅助方法的方法流程图,其步骤包括:在专利数据库110中储存专利文件,每一专利文件皆包含专利分类号(步骤210);提供键入检索条件,并且将键入的检索条件传送至专利数据库110以进行专利检索,查询出符合检索条件的专利文件(步骤220);载入查询出的专利文件,并且以关联规则演算法分析载入的专利文件的专利分类号,以及根据分析结果建立关联规则,每一关联规则包含至少二个专利分类号及一个关联规则强度(步骤230);以及将关联规则强度为弱的关联规则中的专利分类号进行组合以输出为衍生专利建议(步骤240)。通过上述步骤,即可通过载入与检索条件相符的专利文件,直接根据专利分类号结合关联规则演算法对载入的专利文件进行分析,用以建立包含专利分类号及关联规则强度的关联规则,以及从关联规则强度为弱/强的关联规则中,将其包含的专利分类号进行组合以输出成为衍生专利建议/专利无效推论建议。
另外,在步骤240之后,还可将关联规则的专利分类号作为检索条件,并且自专利数据库110下载与检索条件相符的专利文件,以及根据不同的专利分类号对下载的专利文件进行分类及储存以形成技术元素库(步骤250)。
接着,请参阅图3,图3为本发明应用专利数据库的研发辅助系统的另一系统方块图,此系统包含:专利数据库310、检索模块320、分析模块330、关联模块340及处理模块350。其中,专利数据库310及检索模块320与图1的专利数据库110及检索模块120雷同,故在此不再重复赘述。
分析模块330用以载入查询出的专利文件,并且对载入的每一专利文件的内容分别进行自然语言处理及语意分析,以及根据文字挖掘分别产生对应每一专利文件的技术元素信息。在实际实施上,在产生技术元素信息的过程中,还可通过专有名词数据库或专利分类数据库进行辅助查询,用以撷取出与技术元素信息相应的专有名词的技术领域或专利分类说明来作为技术元素信息。举例来说,在对专利文件的内容进行自然语言处理及语意分析后,可得知内容中词汇是属于主词、副词、名词、形容词或介词等等,接着,可直接将名词的部分作为技术元素信息,甚至可搭配专有名词数据库或专利分类数据库进行辅助查询,以便筛除非技术性的名词,并且保留具技术性的名词(即:专有名词)及获得其所属的技术领域;或是将专有名词数据库或专利分类数据库中的数据作为文字挖掘的比对样本来产生技术元素信息;或是从专利分类数据库中查到包含此名词的专利分类说明,所述专利分类说明可包含专利分类号及其说明。此时,即可将上述查到的专有名词及其所属技术领域,甚至是专利分类号及其说明等,一并作为相应专利文件所对应的技术元素信息,例如:技术元素信息可记录为「专有名词:类神经网络;所属技术领域:网络」或「专有名词:类神经网络;所属技术领域:网络;专利分类号及其说明:类神经网络做影像数据处理g06t、g10l25/30使用类神经网络分析语音或音讯」。
关联模块340用以执行关联规则演算法以分析所有产生的技术元素信息,并且根据分析结果建立多个关联规则,其中,每一关联规则包含至少二个技术元素信息及一个关联规则强度。此关联模块340相较于图1的分析模块130,两者的差异仅在于关联模块340是基于分析模块330所产生的技术元素信息产生关联规则,而图1的分析模块130则是基于专利分类号产生关联规则。也就是说,关联模块340以关联规则演算法对载入的专利文件所对应的技术元素信息进行分析,进而产生包含技术元素信息及关联规则强度的关联规则;而图1的分析模块130则是以关联规则演算法对载入的专利文件的专利分类号进行分析,进而产生包含专利分类号及关联规则强度的关联规则。
处理模块350用以选择关联规则强度为弱的关联规则,将其中的技术元素信息进行组合以输出为具有可专利性的研发建议,以及选择关联规则强度为强的关联规则,将其中的技术元素信息进行组合以输出为专利无效推论建议。举例来说,假设在关联规则强度为弱的关联规则中,其包含的技术元素信息为「类神经网络」及「几何属性分析」,那么,可将这二个技术元素信息的组合作为研发建议,换句话说,研发建议中可以建议研发者在「类神经网络」及「几何属性分析」所各自代表的技术的组合基础上,思考相关的技术或进一步改良的技术手段,此方式容易引导研发者,思考出具有可专利性的技术手段,因为关联规则强度为弱,代表结合这二个技术的专利文件较少,所以在此基础上进行技术思考比较不会与先前技术重复。另一方面,专利审查委员在进行专利审查时,也不容易找到可以用来驳回申请的对比前案,所以能够有效提升专利获准的机率。在实际实施上,所述研发建议可嵌入与技术元素信息相符的专利文件,例如:复制相符的专利文件并合并至研发建议,或以超连结方式将相符的专利文件的号码、名称及储存路径嵌入研发建议。接下来,假设在关联规则强度为强的关联规则中,其包含的技术元素信息为「类神经网络」及「深度学习」,那么,可将这二个技术元素信息的组合作为专利无效推论建议,因为关联规则强度为强代表同时包含这二个技术元素信息的专利文件的数量众多,所以容易从中找到对比的前案专利文件,有利于后续作为举发系争专利的证据与论述上的辩证支持,进而提高撤销系争专利的专利权的机率。稍后将配合附图详细说明产生专利无效推论建议的方式。
要补充说明的是,在图3所示的系统中,同样可以包含建立模块360。其与图1的建立模块150相同,都是根据载入的专利文件的专利分类号,将载入的专利文件进行分类及储存以形成技术元素库。
接下来,请参阅图4,图4为本发明应用专利数据库的研发辅助方法的另一方法流程图,其步骤包括:在专利数据库110中储存专利文件(步骤410);提供键入检索条件,并且将键入的检索条件传送至专利数据库110以进行专利检索,查询出符合检索条件的专利文件(步骤420);载入查询出的专利文件,并且对载入的每一专利文件的内容分别进行自然语言处理及语意分析,以及根据文字挖掘分别产生对应每一专利文件的技术元素信息(步骤430);执行关联规则演算法以分析所有产生的技术元素信息,并且根据分析结果建立多个关联规则,其中,每一关联规则包含至少二个技术元素信息及一个关联规则强度(步骤440);以及选择关联规则强度为弱的关联规则,将其中的技术元素信息进行组合以输出为具有可专利性的研发建议,以及选择关联规则强度为强的关联规则,将其中的技术元素信息进行组合以输出为专利无效推论建议(步骤450)。上述步骤与图2所示意的步骤大同小异,主要差异在于图2的步骤是直接使用专利文件中的专利分类号进行关联处理,而图4则是通过步骤430产生的技术元素信息进行关联处理。至于步骤410及步骤420则与图2」的步骤210及步骤220雷同;步骤440及步骤450则与图2的步骤230及步骤240大同小异,其差异仅在于步骤440及步骤450是针对技术元素信息进行处理,而步骤230及步骤240则是针对专利分类号进行处理。
以下配合图5a至图6b以实施例的方式进行如下说明,请先参阅图5a,图5a为应用本发明产生衍生专利建议的示意图。假设研发者为虚拟现实(virtualreality,vr)或增强现实(augmentedreality,ar)的技术背景,并且欲在此技术的基础上进行创新思考。研发者可在输入区块511中键入检索条件,如:「aclm/"virtualreality"」或「aclm/"augmentedreality"」。此时,检索模块120会将研发者键入的检索条件传送至专利数据库110进行专利检索,并查询出符合的专利文件。接着,分析模块130从专利数据库110载入这些被查询出的专利文件,并且使用关联规则演算法,如:apriori演算法,针对这些专利文件的专利分类号进行关联分析。在实际实施上,由于专利分类号为多阶层数据,所以可以仅针对单一阶层,如:大类,或是同时针对多阶层,如:大类及小类(或称之为次类),用以分别进行巨观或微观的关联分析。以针对大类为例,使用关联规则演算法分析后,可产生相应的关联规则,所述关联规则可以图形化方式呈现在第一显示区块521,其中,线条两端是关联规则中相关联的专利分类号(在此例中为大类),而线条的粗细则代表关联规则强度,举例来说,粗线条代表高度关联,也就是说粗线条两端的大类,其对应的关联规则强度为强,同时也代表这两个大类是常被运用的技术元素组合。另外,除了上述单独分析大类之外,在实际实施上,也可使用相同方式同时分析大类及小类,用以产生相应的关联规则,并且同样以图形化的方式呈现在第二显示区块522。值得一提的是,在第二显示区块522中出现许多分群的关联规则,例如:「709/227、709/217」、「705/26.1、705/27.1、705/2」、「703/2、703/1」等等,这些分群的关联规则可以视为「分群创新元素关联规则」,也就是说,这些关联规则中的专利分类号,其代表的技术是非常适合作为被结合的技术元素(例如:适合异业结合的技术元素)。最后,处理模块140会将关联规则强度为弱的关联规则中的专利分类号进行组合以输出为衍生专利建议,其输出方式可为建立档案或直接显示在建议区块530。此时,研发者即可浏览建议区块530中显示的衍生专利建议,例如,从中思考如何结合虚拟现实、电脑与数字处理系统的多电脑传输,特别是远端数据存取(美国专利分类号:709/217)及电脑至电脑的会话/连接建立(美国专利分类号:709/227)等技术,以便产出具有可专利性的技术。在研发者思考的过程中,研发者还可同时在建议区块530中点选显示的专利公告号,以便开启对应的专利文件进行浏览。要补充说明的是,当涉及的技术元素(专利分类号;或称之为项目)数量过多时,还可尝试依专利文件公告的时间先后(技术发展进程),分别列为不同区段,由最近公告(即:第一区段)拆分至最早公告(第n区段)来加以分析且使用图形化方式呈现,例如,第一区(1~100笔)、第二区(101~200笔)、第三区(201~300笔)、并以此类推至第n区。如此一来,即可窥探技术元素在不同时间区间(如:发展期、成熟期及衰退期)的发展及其运用情况。
如图5b所示意,图5b为应用本发明产生研发建议的示意图。同样地,假设研发者为vr或ar的技术背景,并且欲在此技术的基础上进行创新思考。研发者可在输入区块551中键入检索条件,如:「aclm/"virtualreality"」或「aclm/"augmentedreality"」。此时,检索模块320会将研发者键入的检索条件传送至专利数据库310进行专利检索,并查询出符合的专利文件。接着,分析模块330载入这些被查询出的专利文件,并且对载入的每一专利文件的内容分别进行自然语言处理及语意分析,以及根据文字挖掘分别产生对应每一专利文件的技术元素信息,再由关联模块340执行关联规则演算法,如:apriori演算法,针对这些专利文件的技术元素信息进行关联分析,并且根据分析结果产生相应的关联规则,所述关联规则可以图形化方式呈现在第一显示区块561,其中,线条两端是关联规则中相关联的技术元素信息,而线条的粗细则代表关联规则强度,举例来说,粗线条代表高度关联,也就是说粗线条两端的技术元素信息,其对应的关联规则强度为强,同时也代表这两个技术元素信息是常被运用的技术元素组合。另外,倘若出现分群的关联规则(即:与第一显示区块561中的技术元素信息属于不同群组的关联),例如:「信息安全与人身安全的警报器」,其可如图5b所示意,独立显示在第二显示区块562中。所述分群的关联规则可以视为「分群创新元素关联规则」,也就是说,其代表的技术是非常适合作为被结合的技术元素(例如:适合异业结合的技术元素)。最后,处理模块350会将关联规则强度为弱的关联规则中的技术元素信息进行组合以输出为研发建议,其输出方式可为建立档案或直接显示在建议区块570。此时,研发者即可浏览建议区块570中显示的研发建议,从中思考如何结合虚拟现实、信息安全及人身安全的警报器等技术,以便研发出具有可专利性的技术。在研发者思考的过程中,研发者还可同时在建议区块570中点选显示的专利公告号,以便开启与上述技术相关的专利文件进行浏览。要补充说明的是,当涉及的技术元素(如:专有名词、技术领域、专利分类号等等;或称之为项目)数量过多时,还可尝试依专利文件公告的时间先后(技术发展进程)分别列为不同区段,由最近公告(即:第一区段)拆分至最早公告(第n区段)来加以分析且使用图形化方式呈现,例如,第一区(1~100笔)、第二区(101~200笔)、第三区(201~300笔)、并以此类推至第n区。如此一来,即可窥探技术元素在不同时间区间(如:发展期、成熟期及衰退期)的发展及其运用情况。
如图6a所示意,图6a为应用本发明产生专利无效推论建议的示意图。假设研发者遭遇到专利侵权诉讼或警告,可直接将系争专利的专利分类号作为检索条件键入输入区块611,此时,检索模块120会将研发者键入的检索条件传送至专利数据库110进行专利检索,并查询出符合的专利文件。接着,分析模块130载入这些被查询出的专利文件,并且使用关联规则演算法,如:apriori演算法,针对这些专利文件的专利分类号进行关联分析,并且根据分析结果产生关联规则。所述关联规则以图形化方式呈现在显示区块620,其中,线条两端是关联规则中相关联的专利分类号,而线条的粗细则代表关联规则强度,举例来说,粗线条代表高度关联(即:关联规则强度为强),反之则代表低度关联(即:关联规则强度为弱)。至此,上述流程与图5a的流程大同小异,差别仅在于是否同时分析大类及小类,在图6a中为了简化说明仅分析大类。接下来,处理模块140会从关联规则强度为强的关联规则中,将其包含的专利分类号进行组合以输出为专利无效推论建议,其输出方式可为建立档案或直接显示在建议区块630。此时,研发者即可浏览建议区块630中显示的专利无效推论建议,从而得知更多与系争专利直接相关的技术元素组合及其对应的专利文件,以此例而言,假设系争专利的专利分类号为345/619,代表系争专利所属技术领域为计算机图形处理和选择性视觉显示系统中的图形操作,而从专利无效推论建议中可得知其与影像分析技术(大类为382)结合的数量最多,因此可推论与系争专利直接相关的技术元素组合为影像分析技术,所以在查找对比前案时,可将影像分析技术作为限缩检索范围的依据,能够精准找到具有高度关联性的前案专利文件,用以作为举发系争专利时的证据与论述上的辩证支持。换句话说,在图5a所示意的建议区块530中,其显示的是衍生专利建议,在图6a所示意的建议区块630中,其显示的是专利无效推论建议,关联规则强度为强的关联规则,代表存在关联规则所包含的专利分类号的专利文件的数量也越多,故容易从中找到对比的前案专利文件,有利于后续作为举发系争专利的证据与论述上的辩证支持,进而提高撤销系争专利的专利权的机率。在实际实施上,在键入检索条件后,也可以将图5a所示意的衍生专利建议及图6a所示意的专利无效推论建议同时显示在同一个视窗中(图中未示)。
如图6b所示意,图6b为应用本发明产生专利无效推论建议的另一示意图。假设研发者遭遇到专利侵权诉讼或警告,可先审阅系争专利及其权利范围以判断出所属的技术领域,如:「virtualreality」,接着,可指定欲检索的栏位并将系争专利的技术领域作为关键字以产生检索条件(如:「aclm/"virtualreality"」,其中,「aclm/」为指定专利范围栏位;「virtualreality」为系争专利的技术领域),当在输入区块651键入检索条件后,检索模块320会将研发者键入的检索条件传送至专利数据库310进行专利检索,并查询出符合的专利文件。接着,分析模块330载入与检索条件相符的专利文件,并且对载入的每一专利文件的内容分别进行自然语言处理及语意分析,以及根据文字挖掘产生对应每一专利文件的技术元素信息。接下来,关联模块340执行关联规则演算法,如:apriori演算法,针对这些专利文件的技术元素信息进行关联分析,并且根据分析结果产生关联规则。所述关联规则以图形化方式呈现在显示区块660,其中,线条两端是关联规则中相关联的技术元素信息,而线条的粗细则代表关联规则强度,举例来说,粗线条代表高度关联(即:关联规则强度为强),反之则代表低度关联(即:关联规则强度为弱)。至此,上述流程与图5b的流程雷同。然而,不同的是,接下来处理模块350会从关联规则强度为强的关联规则中,将其包含的技术元素信息进行组合以输出为专利无效推论建议,其输出方式可为建立档案或直接显示在建议区块670。此时,研发者即可浏览建议区块670中显示的专利无效推论建议,从而得知在系争专利所属的技术领域中,哪些技术元素组合的专利文件数量最多。以此例而言,从显示区块660中可明显看出「语音或音讯」与「类神经网络」结合的数量最多(因为相连的线条最粗),因此可推论在查找对比前案时,从同时包含这两个技术元素的专利文件中比较容易找到适合的对比前案或其组合,用以作为举发系争专利时的证据与论述上的辩证支持。换句话说,在图5b所示意的建议区块570中,其显示的是具有可专利性的研发建议,在图6b所示意的建议区块670中,其显示的是专利无效推论建议,因为关联规则强度为强的关联规则,代表存在关联规则所包含的技术元素信息的专利文件的数量也越多,故容易从中找到对比的前案专利文件,有利于后续作为举发系争专利的证据与论述上的辩证支持,进而提高撤销系争专利的专利权的机率。同样地,在键入检索条件后,也可以将图5b所示意的研发建议及图6b所示意的专利无效推论建议同时显示在同一个视窗中(图中未示)。
综上所述,可知本发明与先前技术之间的差异在于通过载入与检索条件相符的专利文件,并且直接根据专利分类号或产生对应各专利文件的技术元素信息,结合关联规则演算法对载入的专利文件进行分析,以便建立包含专利分类号或技术元素信息,以及包含关联规则强度的关联规则,接着选择关联规则强度为弱/强的关联规则,将其包含的专利分类号或技术元素信息进行组合以输出能够辅助研发的建议,通过此技术手段可以解决先前技术所存在的问题,进而达成提高应用专利数据库辅助研发的实用性的技术功效。
虽然本发明以前述的实施例公开如上,然其并非用以限定本发明,任何熟习相像技艺者,在不脱离本发明的精神和范围内,当可作些许的更动与润饰,因此本发明的专利保护范围须视本说明书所附的权利要求书所界定者为准。
- 还没有人留言评论。精彩留言会获得点赞!