一种基于特征选择和参数优化的冰球赛况预测方法与流程
本发明属于大数据处理技术,尤其涉及一种冰球比赛结构预测技术,具体地说是一种基于特征选择和参数优化的冰球赛况预测方法。
背景技术:
随着信息技术的发展,竞技体育比赛数据的数据维度和数据量呈指数级增长。在冰球运动中,进攻位同时也为防守位,相较于其他运动,更强调人员配合和分工协作。进攻位置的战术布局、攻防转换都对比赛有着至关重要的影响,因而周边数据的有效性、对比标本的数据量都对赛事预测有直接性的影响;准确的赛况预测更能使得团队规避风险、取长补短,对实战具有极大的帮助。同时基于大数据分析的技术和战术安排、培训训练、可以为选手、教练员提供数据支持,使其训练更为高效。在进行冰球赛事统计时,不仅需要考虑球员的出场位置、防守成功率、进攻得分率;还需考虑周边数据的有效性和足够的对比标本(包括球员流动、联盟交换以及不同组合搭配的影响)。因此,数据量相当庞大且数据维度高。
数据量级越大,预测结果越真实准确。但是,大量的数据也会导致比赛数据的样本呈现离散性、随机性和独立性,加深筛选有效特征的困难程度,增加处理时间。
以经验预测法、指数平滑法、灰色预测法为代表的传统预测算法是根据数据的直接特性分析数据,算法思路简单,具有局限性,通常适合小样本数据的预测。针对冰球赛事预测这一问题,影响其预测结果的随机因素复杂,且呈现非线性关系,传统预测方法难以满足其需要。
支持向量机(SVM)可以有效平衡学习结果的准确性,具有良好的泛化能力;为分类预测问题提供了很好的解决思路。同时由于支持向量机也基于统计学理论,可以解决线性可分问题和线性不可分问题;在处理非线性和高维数据的分类问题方面具有明显的优势。已有的支持向量机方法是将原低维、非线性问题映射到高维特征空间转化成一个二次寻优的问题,但其在解决多分类问题上也存在着处理方式单一的缺点。为了更为高效的利用其优点对冰球比赛进行准确预测,需要对算法进行结合,改进和提高。
技术实现要素:
发明的目的是针对冰球赛况数据量相当庞大且数据维度高,计算复杂,以及基于支持向量机的预测模型的惩罚因子C和核函数参数g对其泛化能力影响较大、参数难以调节的问题,发明一种基于特征选择和参数优化的冰球赛况预测方法。
本发明的技术方案是:
一种基于特征选择和参数优化的冰球赛况预测方法,其特征是它包括如下步骤:
步骤1:对获取的待预测的冰球比赛数据进行数据标准化处理,即通过函数变换使数据映射到特定区间;
步骤2:对进行数据标准化处理的冰球比赛数据集再使用基于稀疏表达思想和用L1 范数最小化优化方法,获得冰球数据特征的稀疏表示重构系数,并将原始特征和重构特征的误差作为该特征的稀疏分数;
步骤3:计算待处理的冰球比赛数据集中拉普拉斯改进标准分类特征与每个特征变量的相关性;
步骤4:根据步骤2和步骤3计算得到冰球比赛关键特征的稀疏分数以及分类类别与特征的相关关系,分析特征的稀疏分数与该特征和类别的相关性之间的相互关系提出冗余特征,实现特征选择;
步骤5:通过混合GAPSO算法优化支持向量机的惩罚因子C以及核函数参数g,实现支持向量机的参数优化;
步骤6:采用K折交叉验证,输出冰球比赛预测准确率。
其中:
步骤2中计算冰球比赛数据集中各个特征的稀疏分数包括如下步骤:
步骤2.1:对待处理的冰球比赛数据集,使用基于稀疏表达思想和用L1范数最小化优化方法以获得数据特征的稀疏表示重构系数。具体而言,对于一个给定的冰球比赛数据集其中xi∈Rd,令数据矩阵X=[x1,x2,…,xn]∈Rd×n中的每列作为该数据集的特征向量。用公式对所有数据向量Xi计算基于稀疏表示的重构系数si;其中,X′是X不包含xi的数据矩阵。n维系数向量 si=[si1,…,sii-1,0,sii+1,…,sin]T,通常sii=0,因为在计算重构稀疏si时,没有将 xi包含在X里面。同时,sij,j≠i则表示数据向量xj对于重构xi所做的贡献。
步骤2.2:用对每个特征在整个冰球比赛数据集样本上的重构误差求和,获得在整个冰球比赛数据集上的各个特征的稀疏表示保留能力即特征的稀疏分数;其中,用于表示第r维的原始特征xir与该特征基于重构系数矩阵得到重构特征之间的误差累加结果,用Var(X(r,:))表示第r维特征的方差。
步骤2.3:将特征的稀疏分数S(r)按照升序排列。
步骤3的计算方法为:对待处理冰球赛事数据集,计算其分类类别与特征变量的相关性C(i):
subject.to.k=1,2,…,d
t=1,2,…,d
Np≥1
式中,Np表示分类类别为p的样本个数;Nn表示分类类别不是p的样本个数;表示所有冰球比赛样本中的第i维特征变量的均值;表示冰球比赛数据样本集中的分类类别为p的第i维特征变量的均值;表示冰球比赛数据样本集中的非类别p的第i维特征变量的均值;xk,ip表示第i维特征变量中第k个类别p样本的值;xt,ip表示第i维特征变量中第t个非类别p样本的值。
此时,冰球赛事中分类特征与特征变量相关性C(i)的计算结果是d维向量,当分类类别与特征之间相关关系越强时,计算得出的C(i)就越大;当分类类别与特征关系为弱相关或不相关时,计算得出的C(i)就越小,因此将相关性按照降序排列。
步骤4的特征选择方法是:根据步骤2和步骤3得到冰球比赛数据特征的稀疏分数以及分类类别与特征的相关关系(简称相关性),分析特征的稀疏分数与该特征和类别的相关性之间的相互关系。考虑特征的稀疏分数和相关性可能出现会极小值和极大值的4种情况。具体如表4.1所示,Small是指该指标计算结果很小。对于冰球比赛中选取的分类特征的稀疏分数S(r)来说,若某一特征的稀疏分数较小,表示该特征具有更好的稀疏表示保留能力。对于相关性C(i)来说,表示特征与类别几乎为不相关;反之,Big是指计算数值很大,对于S(r)来说,若某一特征稀疏分数较大表明该特征稀疏表示保留能力较差,认为该特征是不好的特征;对于特征相关性C(i)来说,表示分类类别与该特征的关系是强相关关系。
表4.1稀疏分数和相关性的相互关系
情况1:该特征的稀疏保留能力较差,但是特征与类别的相关性较强,考虑保留;
情况2:该特征的稀疏保留能力以及特征与类别的相关性都较差,考虑剔除该特征;
情况3:该特征的稀疏保留能力较强,特征与类别的相关性也较强,考虑保留;
情况4:该特征的稀疏保留能力较强,但是特征与类别的相关性较差,考虑保留。
步骤5的参数优化方法步骤为:
步骤5.1:初始化冰球比赛原始种群及GA、PSO相关参数如:最大进化代数maxgen、种群最大数量sizepop、遗传算法中的交叉概率pCrossover、变异概率pMutation;粒子群算法中粒子局部搜索能力c1,全局搜索能力c2、交叉验证次数以及输出结果C,g的变化范围cbound、gbound等参数。根据初始化的C,g的范围确定染色体的个数,然后使用R=unidrnd(N,m,n)产生一组只有0或1的离散均匀随机整数,使用二进制编码生成GA种群,解码GA种群产生PSO种群并初始化PSO粒子速度和位置。
步骤5.2:计算两个种群个体适应度:将支持向量机的分类正确率R作为GA和PSO 种群个体的个体适应度。
步骤5.3:比较GA和PSO种群最优解产生总体最优解,若满足终止条件,跳转至步骤5.5结束参数寻优。否则,如果PSO最优解的适应度比GA高,则将PSO的适应度作为总体最优解并且赋值给基因算法中最差的染色体;如果PSO最优解的适应度比GA低,则将GA中适应度最高的染色体作为总体最优解并且赋值给PSO算法中最差的粒子。
步骤5.4:对GA种群进行选择父代种群的操作,然后进行交叉操作和变异操作;PSO 种群则更新速度和位置,根据Metropolis准则判断是否接受粒子的更新后速度和位置。返回至步骤5.2。
步骤5.5:终止条件判断:达到收敛精度或者迭代次数达到maxgen,输出C,g。
本发明的有益效果是:
本发明针对冰球比赛赛况复杂、强调配合,赛况预测需大量对比标本以及对数据有效性要求高的实际情况,通过特征选择和数据优化的算法对原始数据集进行处理,保留相关性的较大的特征,并进一步优化ISSFS模型结构,有效提升预测结果的准确性。
本发明的特征选择采用稀疏表示的思想和L1范数最小化的方法,并将冰球比赛样本分类类别与样本特征之间得相关信息加入到特征选择过程,得到特征选择子集。基于稀疏分数和相关性分析的特征选择算法通过构造冰球比赛数据集的稀疏表示进而重构系数矩阵,然后计算各特征的稀疏分数,并对其排序,将特征稀疏和分类类别与特征的相关程度综合得出最佳特征子集,使算法具有更好的特征判别和信息保留能力。由于算法中的相关性的计算,利用了样本类别信息,所以该算法是一种有监督的特征选择方法,可以在各种分类、预测问题的研究中应用。通过使用特征选择算法对影响比赛赛况的因素进行特征选择降维,简化ISSFS预测模型的输入,降低ISSFS模型运行时间;综合利用粒子群算法的快速收敛能力和基因算法的局部搜索能力的混合GAPSO算法优化支持向量机的参数,可以提高预测模型的预测准确率与稳定性。
本发明通过特征选择算法能提升冰球比赛预测模型的运行速度与效率,并提升冰球赛况预测的准确性。
附图说明
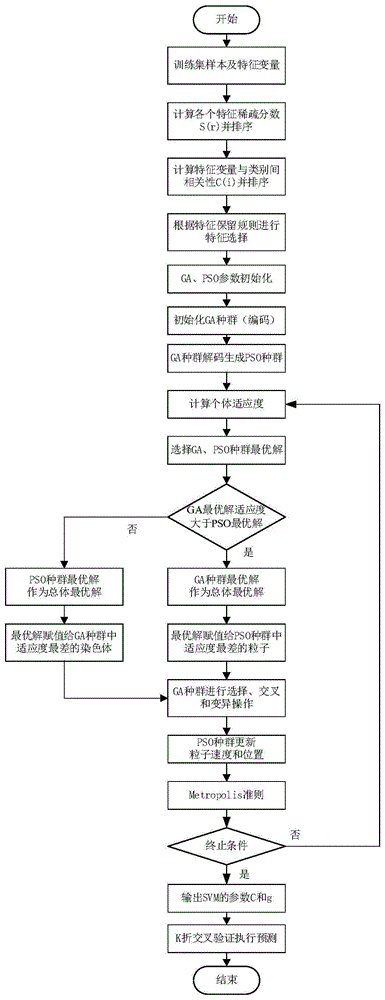
图1为基于特征选择和参数优化的冰球赛况预测方法的流程图。
具体实施方式
下面结合附图和实施例对本发明作进一步的说明,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
如图1所示。
一种基于特征选择和参数优化的冰球赛况预测方法,具体包括如下步骤:
步骤1:对获取的待预测的冰球比赛数据进行数据标准化处理,即通过函数变换使数据映射到特定区间;
步骤2:对进行数据标准化处理的冰球比赛数据集再使用基于稀疏表达思想和用L1 范数最小化优化方法,获得冰球数据特征的稀疏表示重构系数,并将原始特征和重构特征的误差作为该特征的稀疏分数;
计算冰球比赛数据集中各个特征的稀疏分数包括如下步骤:
步骤2.1:对待处理的冰球比赛数据集,使用基于稀疏表达思想和用L1范数最小化优化方法以获得数据特征的稀疏表示重构系数。具体而言,对于一个给定的冰球比赛数据集其中xi∈Rd,令数据矩阵X=[x1,x2,…,xn]∈Rd×n中的每列作为该数据集的特征向量。用公式对所有数据向量Xi计算基于稀疏表示的重构系数si;其中,X′是X不包含xi的数据矩阵。N维系数向量 si=[si1,…,sii-1,0,sii+1,…,sin]T,通常sii=0,因为在计算重构稀疏si时,没有将 xi包含在X里面。同时,sij,j≠i则表示数据向量xj对于重构xi所做的贡献。
步骤2.2:用对每个特征在整个冰球比赛数据集样本上的重构误差求和,获得在整个冰球比赛数据集上的各个特征的稀疏表示保留能力即特征的稀疏分数;其中,用于表示第r维的原始特征xir与该特征基于重构系数矩阵得到重构特征之间的误差累加结果,用Var(X(r,:))表示第r维特征的方差。
步骤2.3:将特征的稀疏分数按照升序排列。
步骤3:计算待处理的冰球比赛数据集中拉普拉斯改进标准分类特征与每个特征变量的相关性;
对待处理冰球赛事数据集,计算其分类类别与特征变量的相关性C(i):
subject.to.k=1,2,…,d
t=1,2,…,d
Np≥1
式中,Np表示分类类别为p的样本个数;Nn表示分类类别不是p的样本个数;表示所有冰球比赛样本中的第i维特征变量的均值;表示冰球比赛数据样本集中的分类类别为p的第i维特征变量的均值;表示冰球比赛数据样本集中的非类别p的第i维特征变量的均值;xk,ip表示第i维特征变量中第k个类别p样本的值;xt,ip表示第i维特征变量中第t个非类别p样本的值。
此时,冰球赛事中分类特征与特征变量相关性C(i)的计算结果是d维向量,当分类类别与特征之间相关关系越强时,计算得出的C(i)就越大;当分类类别与特征关系为弱相关或不相关时,计算得出的C(i)就越小,因此将相关性按照降序排列。
步骤4:根据步骤2和步骤3计算得到冰球比赛关键特征的稀疏分数以及分类类别与特征的相关关系,分析特征的稀疏分数与该特征和类别的相关性之间的相互关系提出冗余特征,实现特征选择;考虑特征的稀疏分数和相关性可能出现会极小值和极大值的4种情况。具体如表4.1所示,Small是指该指标计算结果很小。对于冰球比赛中选取的分类特征的稀疏分数S(r)来说,若某一特征的稀疏分数较小,表示该特征具有更好的稀疏表示保留能力。对于相关性C(i)来说,表示特征与类别几乎为不相关;反之,Big是指计算数值很大,对于S(r)来说,若某一特征稀疏分数较大表明该特征稀疏表示保留能力较差,认为该特征是不好的特征;对于特征相关性C(i)来说,表示分类类别与该特征的关系是强相关关系。
表4.2稀疏分数和相关性的相互关系
情况1:该特征的稀疏保留能力较差,但是特征与类别的相关性较强,考虑保留;
情况2:该特征的稀疏保留能力以及特征与类别的相关性都较差,考虑剔除该特征;
情况3:该特征的稀疏保留能力较强,特征与类别的相关性也较强,考虑保留;
情况4:该特征的稀疏保留能力较强,但是特征与类别的相关性较差,考虑保留。
步骤5:通过混合GAPSO算法优化支持向量机的惩罚因子C以及核函数参数g,实现支持向量机的参数优化,具体包括如下步骤:
步骤5.1:初始化冰球比赛原始种群及GA、PSO相关参数如:最大进化代数maxgen、种群最大数量sizepop、遗传算法中的交叉概率pCrossover、变异概率pMutation;粒子群算法中粒子局部搜索能力c1,全局搜索能力c2、交叉验证次数以及输出结果C,g的变化范围cbound、gbound等参数。根据初始化的C,g的范围确定染色体的个数,然后使用R=unidrnd(N,m,n)产生一组只有0或1的离散均匀随机整数,使用二进制编码生成GA种群,解码GA种群产生PSO种群并初始化PSO粒子速度和位置。
步骤5.2:计算两个种群个体适应度:将支持向量机的分类正确率R作为GA和PSO 种群个体的个体适应度。
步骤5.3:比较GA和PSO种群最优解产生总体最优解,若满足终止条件,跳转Step5 结束参数寻优。否则,如果PSO最优解的适应度比GA高,则将PSO的适应度作为总体最优解并且赋值给基因算法中最差的染色体;如果PSO最优解的适应度比GA低,则将 GA中适应度最高的染色体作为总体最优解并且赋值给PSO算法中最差的粒子。
步骤5.4:对GA种群进行选择父代种群的操作,然后进行交叉操作和变异操作;PSO 种群则更新速度和位置,根据Metropolis准则判断是否接受粒子的更新后速度和位置。返回至Step2。
步骤5.5:终止条件判断:达到收敛精度或者迭代次数达到maxgen,输出C,g。
步骤6:采用K折交叉验证,输出冰球比赛预测准确率。
为了验证本发明中改进的ISSFS-N-HGAPSO-SVM算法的优越性能,将其与不适用任何改进的原始的GA-SVM算法进行20次重复实验得到其平均值并比较:
本发肯的赛况预测模型选取主客队本赛季常规数据12项作为输入。分别是:主客队积分(PTs)、主客队场均进球(GF)、主客队场均失球(GA)、主客队多打少成功率 (PP%),主客队少防多成功率(SH%)以及主客队争球胜率(OT%)。数据示例如表 5.1所示。
表5.1两队本赛季常规数据对比
主客队头号得分手12项数据作为模型的输入:主客队头号得分手总进球(G)、主客队头号得分手总得分(P)、主客队头号得分手场均进球(G/GP)、主客队头号得分手场均失球(P/GP)、主客队头号得分手射门成功率(s%)以及主客队头号得分手正负效率值(+/--)。数据示例见表5.2。
表5.2两队头号得分手数据对比
主客队头号后卫的12项数据作为模型的输入:主客队头号后卫总进球(G)、主客队头号后卫总得分(P)、主客队头号后卫场均进球(G/GP)、主客队头号后卫场均失球 (P/GP)、主客队头号后卫射门成功率(s%)以及主客队头号后卫正负效率值(+/--)。数据示例如表5.3所示。
表5.3两队头号后卫数据对比
主客队首发门将的12项数据作为模型的输入:主客队门将首发次数(GS)、主客队失球数(GA)、主客队场均失球(GAA)、主客队扑球率(Sv%)以及主客队零封次数 (SO)。数据示例见表5.4。
表5.4两队首发门将数据对比
以上共计48项数据是本发明的冰球赛况预测模型的输入特征x1,x2,...,x48。实验中,将算法设置种群最大的进化代数为200,种群最大数量为20,PSO的参数局部搜索能力初始c1为1.5,参数全局搜索能力c2初始为1.7,交叉验证次数为5;将每种算法都运行 20次,得出各算法的平均准确率和运行时间如表5.5所示。
表5.5改进后的算法预测准确率与运行时间对比表
比较可得,相比于原始算法其预测准确率增加14.4%,且耗时也有所减少,证明混合遗传粒子群参数优化算法的有效性。加入特征选择,使预测模型输入维度降低,即支持向量机在高维空间运行的复杂度降低可使运行时间有所降低;且由于特征选择算法在保证特征类别相关性的同时剔除冗余特征,可以有效提高冰球比赛预测模型的预测准确率。
本发明未涉及部分与现有技术相同或可采用现有技术加以实现。
- 还没有人留言评论。精彩留言会获得点赞!