一种面向云际环境的时空数据索引方法与流程
本发明涉及一种索引方法,尤其涉及一种面向云际环境的时空数据索引方法。
背景技术:
在车联网应用中,通过车辆配备的gps、obd设备来持续收集以位置为核心的各类数据,并由此积累了海量的历史时空数据,轨迹数据是其中重要的一类。考虑到海量存储和高插入速率的要求,一般选择使用hbase来存储轨迹数据,主键是车辆标识+时间戳。使用这种模式存储轨迹数据,可以方便地获取车俩在某一个时间段内的轨迹数据,然而当应用需要查询某个时间段内某一空间区域内所有的车辆轨迹点时(时空范围查询),则需要以过滤方式扫描全表来获取最后的结果。虽然可以通过mapreduce并行化过滤操作,但这仍然是一个批处理耗时操作。为了及时获得查询结果,需要构建行之有效的时空数据索引来支持时空范围查询。
上述问题拓展到云际环境时则进一步复杂化了。云际计算(jointcloudcomputing)是以云服务提供者之间开放协作为基础,通过多方云资源深度融合,方便开发者通过“软件定义”的方式定制云服务、创造云价值,实现“服务无边界、云间有协作、资源易共享、价值可转换”的新一代云计算模式,推动互联网从信息传递网络进一步向价值传递网络演进。在云际环境下,海量历史时空数据分布在不同的云中,每个云中只存储了整体时空数据的一个子集,其只能反映部分环境特征,因此针对任何一个云的时空范围查询获得的结果都不能完整反映现实环境特征,因此应用有必要获取对整体时空数据的时空范围查询结果。同时考虑到目前云端并没有成熟的时空数据存储解决方案,这些数据通常是存储在云端的nosql数据库中,其没有原生支持这类时空查询操作。学术界目前没有跨云时空范围查询的直接研究成果出现。云际环境主要带来了两个限制:1.云之间存在安全性问题,意味着不同云各自掌管自身的数据,在云间难以迁移数据;2.时空数据的规模则不仅限制了在云间迁移数据的可能性,同样也限制了在云内重新分布数据的可能性,即在云内把时空数据以利于时空查询的方式重新分布的代价略大。
目前并没有一种技术可以解决云际环境下时空数据的跨云时空范围查询问题。在单云环境下,md-hbase是一种海量空间数据管理系统,其可以用来存储海量空间数据并进行空间范围查询。md-hbase是一种适用于多维数据的存储系统。在存储层,md-hbase使用z-ordering技术把多维数据映射为一维数据,并以该一维数据作为主键把多维数据存储在hbase中。使用z-ordering技术使得在多维空间上接近的数据在一维空间也接近,表现为在hbase存储时这些数据位置也相近。在索引层,md-hbase使用quad-tree和kd-tree实现了两种多维索引,支持多维数据的范围查询和最近邻查询。索引层的作用在于保证查询时减少falsepositive查找。md-hbase的缺点在于索引层和存储层维护一致性复杂,并且考虑到时空数据是一种特殊的多维数据,时间维度没有界限并不能应用z-ordering技术降维,只能把时间维度单独处理,此时时间维度没有索引而导致查询效率低下。
以上可以考虑为现有技术中单云环境下的一种解决方法,而当时空数据分布在云际环境时,md-hbase则不能有效解决跨云的时空范围查询问题,其不足主要有两点:1.其是面向多维数据的存储和查询的系统,时空数据是特殊的多维数据因此不能直接使用该系统;2.md-hbase在存储数据时要求按照设计的主键规则重新分布数据,而在云际环境中存在安全性和数据规模的限制,难以在云间迁移数据,同时也不允许在云内重新分布数据。
技术实现要素:
本发明提出一种面向云际环境的时空数据索引。减少存储成本、支持跨云时空范围查询、优化查询效率是本发明的目标。
本方法相对于目前单云下的解决技术具有如下的特点和优势:
(1)云内节点存储的时空数据,采用先时间划分后空间划分的方式对时空数据建立局部索引,在进行时空查询时可以先对时间剪枝再对空间剪枝,有效提高了时空范围查询的效率。
(2)以二级索引的方式支持跨云时空范围查询,避免了海量数据的重复存储,减少了存储成本。
(3)在云际间的节点上建立一个全局索引,存储云内各节点局部索引的索引摘要,在查询时先经过全局索引过滤出可能参与查询的节点,再到相应的云内节点的局部索引查询数据,有效避免了falsepositive查询。
附图说明
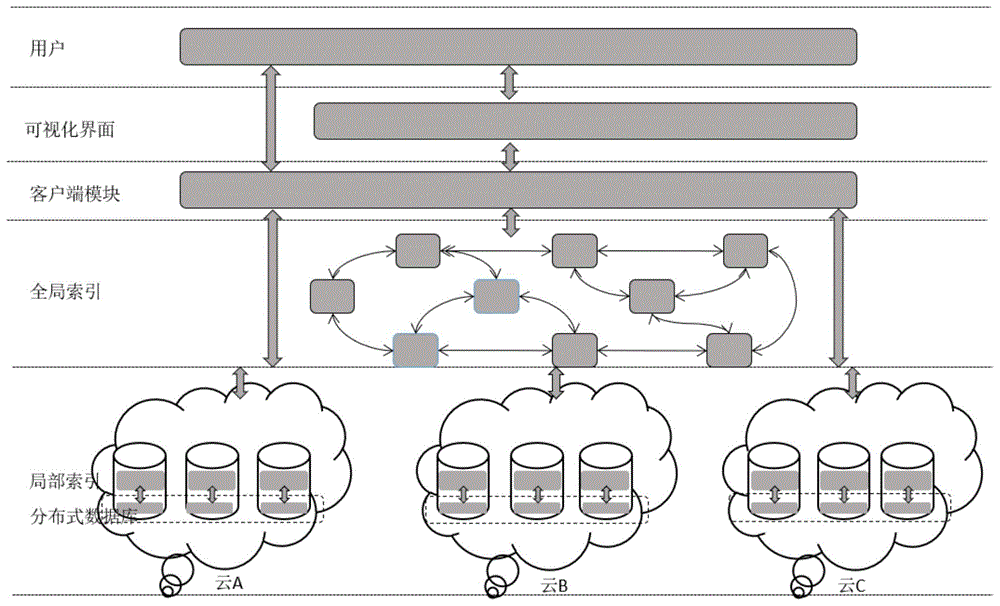
图1为本发明中面向云际环境的时空数据索引系统的结构;
图2为本发明中使用的三种空间填充曲线;
图3为本发明中空间填充曲线为z曲线的一阶到三阶形式;
图4为本发明中局部索引扩展和收缩过程;
图5为本发明中全局索引的baton网络
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
为实现上述发明目的,本发明提供了一种面向云际环境的时空数据索引方法,其使用的系统包括以下几个模块:
可视化界面方便用户进行跨云时空范围查询,并把查询结果展示在地图之上。用户也可以直接使用客户端模块的api来进行跨云时空范围查询。
客户端模块封装了云际环境下时空数据索引的跨云时空范围查询接口,通过先与全局索引交互过滤出可能参与查询的节点,再向这些节点的局部索引请求数据,最后汇总结果返回。
全局索引模块中,云中的每一个节点均有一个该实例。在云际环境下,全局索引实例被组织在一个overlay网络中,其负责接收局部索引发布的索引摘要,并且按照一定的规则选择存储在某一个全局索引实例中;同时其负责接收上层的查询请求,过滤出可能包含查询所需数据的云内节点。
局部索引模块中,云内的每一个节点均有一个该实例。局部索引主要负责索引云内节点本地存储的时空数据,并对外提供时空范围查询的接口以及发布索引摘要。同时局部索引还负责记录查询信息,并定期根据查询信息动态地调整局部索引需要发布的索引摘要范围。
本发明使用轨迹数据格式的时空数据,其数据模型为一个n元组:r=<devicesn,x,y,timestamp,clusterid,attrs),其中前5个为核心属性,devicesn是设备标识,timestamp是该条记录产生时的时间戳,x和y则分别代表该条记录的经纬度,clusterid则代表该记录所属的云标识,主要目的是用来区分不同的云,attrs则代表其余所有的属性。局部索引将基于x、y和timestamp这三个属性来构建。
时空数据是一种特殊的多维数据,特别是考虑到时间维度连续,空间维度有限的特性。现有的一些多维数据索引结构如r-tree以及kd-tree等被设计为索引单节点上的多维数据,能较好地完成范围查询的需求。局部索引需要发布其索引摘要到全局索引中,其设计受到全局索引设计的影响,因此没有使用传统的多维数据索引结构来索引节点存储的时空数据,而是选择采用先划分时间再使用ub-tree的方式索引空间数据的方案,使得局部索引的索引摘要可以发布到全局索引中且可供查询。
本发明将节点本地存储的时空数据先对时间分片后再使用ub-tree来索引空间维度,而ub-tree采用降维方法,把多维数据降为一维数据后再存储在b+-tree中。降维方法就是使用空间填充曲线来完成的,一般来说空间填充曲线分为三种,分别是z曲线、hilbert曲线和gray曲线。
空间填充曲线是一种可以将d维的数据空间填充满的曲线。通过既定的填充规则,其可以通过有限次数的逼近操作把d维空间切分成许多体积微小的网格,最后始终能够发现一条连续的空间填充曲线通过所有的网格而不重叠。因此空间填充曲线是一种把d维数据空间上的数据映射到一维空间的一种函数,并且这种函数关系可以保存一部分原始数据在d维空间的局部性,即在原始空间相邻的点映射为一维的点后也尽可能相邻。
以二维空间映射到一维空间为例,三种空间填充曲线的填充图如图2所示。在保存局部性方面,z曲线和hilbert曲线的效果都不错,然而存在对角线,z曲线保存局部性的效果则略逊于hilbert曲线,而且z曲线的映射函数更为简单,同时没有旋转和反射等操作,导致z值的计算较为容易。因此本发明选择使用z曲线。
d维空间rd到1维空间r的一一映射关系,即rd→r被定义为z曲线。如果p∈rd的话,那么z(p)∈r,则称z(p)为点p的z值。
下图表示了1到3阶的z曲线是如何映射的。从图中可以归纳出,m阶的z曲线会将每个维度切分为2m份,d维空间映射到一维空间的z值与此相关。若点p在d维空间上的十进制坐标形式为p=(p1,p2,…,pd)10,那么在m阶曲线下,其二进制形式可以描述为p=(x1x2…xm,…,y1y2…ym)2,二进制的每一位表示了对坐标轴的一次分割。
网格的次序可以通过z值来反映,根据网格的位置,可以计算出相应的z值,而根据z值也可以获得该z值对应的网格在空间中的位置。通过将网格坐标的二进制形式进行位交叉,可以在o(1)时间内计算得到z值。
以二维空间为例,对于图2中网格p=(3,4)10=(011,100)2,其z值为z(p)=z(0112,1002)=(011010)2=26,位交叉过程图3所示。
在云内,时空数据以devicesn+timestamp为rowkey存储在分布式数据库中,即时空数据已经按照既定的分区规则分布在云内的节点上。开源使用最广泛的分布式数据库是hbase,因此本发明均使用hbase数据库,但是整体方案也可以迁移到其它的分布式数据库,如cassandra等。hbase设计的rowkey能方便地获取设备在某一个时间段内的时空数据。但是使用这种方式来存储数据不利于典型的时空查询,例如rangequery和knnquery。考虑到时空数据经过数年的累积,已经达到了tb级别的规模,重复存储不仅带来了迁移的压力,其存储成本也不能简单忽略。本发明使用二级索引的方式支持典型的时空查询以避免迁移数据和重复存储数据,具体实现目标是时空范围查询。同时为了减少云内节点的falsepositive查询,把局部索引的索引摘要集合发布到全局索引中,查询时先经过全局索引剪枝过滤出可能参与查询的节点后,再向这些节点上的局部索引发起时空范围查询获取结果。
基于局部索引模块与全局索引模块的有机结合,本发明对时空数据进行时间划分,以一定时间为间隔,再使用ub-tree来索引该时间段内的空间数据。ub-tree使用的降维方法是z曲线。
局部索引的构建方式为以下步骤:
步骤1,获取到一条时空数据record=(rowkey,devicesn,x,y,timestamp,clusterid,attrs)。
步骤2,根据record.timestamp属性判断该记录应该插入哪一个时间段内的b+-tree。
步骤3,根据record.x和record.y属性,以及预定义的z曲线的阶数和维度,生成z值zvalue
步骤4,将(zvalue,rowkey)元组插入该时间段的b+-tree。
局部索引不仅需要负责索引存储在本地节点上的时空数据,同时还需要发布索引摘要到全局索引中。同时为了进一步减少falsepositive查询以及减少存储压力,局部索引还需要根据查询记录,定期动态地调整索引摘要发布的范围。
局部索引在索引时空数据时先对时间进行划分,再对每个时间段内的数据使用ub-tree来构建空间索引。ub-tree的核心是降维方法和底层的b+-tree。b+-tree中存储了大量的数据,索引摘要为描述该b+-tree所存数据的特征,是一个不相交范围的集合。一个z值如果存储在b+-tree中,那么它肯定在该集合包含的范围之内。反之则不然,一个属于集合范围内的z值则可能不存储在该b+-tree中。
以图4所示,一个b+-tree的索引摘要就是图中所有黑色节点表示的范围集合,一个节点的范围是以该节点为根的树的最小值和最大值,不同节点的范围必然是不相交的。从上到下表示了索引摘要的动态发布过程,左侧方框意味着收缩一个摘要范围,即把孩子节点表示范围集合收缩为一个父亲节点表示的范围。右侧方框意味着拓展一个范围,即把父亲节点表示的范围由几个孩子节点的范围集合替代。
索引范围的收缩主要是考虑到内存大小是受限的,同时在全局索引中存储索引摘要的数据结构实际上是一个动态数组,因此不能无限地拓展摘要。在需要时也有必要收缩摘要的范围。而索引摘要的拓展则主要是考虑到b+-tree是磁盘索引,每次查询是一个耗时的操作,有些节点不包含待查数据却参与了查询造成了性能的浪费,因此有必要减少类似的falsepositive查询。
索引发布模块在冷启动时选择发布到第二层节点,随后根据查询记录动态调整是否拓展到下一层。因此局部索引在接收上层的查询请求时,先经过索引发布模块,如果不在局部索引的索引摘要范围内,则不用查询b+-tree,否则查询b+-tree,索引发布模块则需要记录余下查询是否成功,并记录查询发生的时间点。系统需要定期检查索引摘要,如果一个索引摘要的falsepostive查询比值达到阈值,则需要把该索引摘要拓展到下一层。索引摘要的收缩则主要综合考虑冷却时间和拓展层数,如果一个索引摘要拓展层数多于设定的层数阈值并且查询间隔时间高于设定的间隔阈值,则收缩至上一层。
当局部索引收到一个时空范围查询时,首先提取出时间参数区间,根据时间参数区间判断哪些b+-tree需要参与查询,然后把空间参数区间转换成z值集合,从索引发布模块过滤掉部分无效z值,并使用z值集合获取到rowkey集合,更新索引发布模块的记录,最后从hbase中获取到相应的数据后并返回。
不过以此获得的数据中可能存在部分数据不在查询时间的区间内,此部分的数据则由给客户端模块负责过滤。
全局索引模块的主要功能是存储局部索引模块发布的索引摘要,并对外提供查询的接口,其核心思想是过滤出可能包含查询要求时空数据的节点,以便客户端模块可以向这些节点直接请求数据。索引摘要的形式是一个四元组tuple=<timeindex,left,right,ip>,其中timeindex表示的是时间序号,left和right则代表一个范围的左值和右值,ip则代表索引摘要来自哪个机器。对于全局索引的查询可以表示为query=<timeindex,left,right>,该查询返回一个ip的集合,代表集合内的机器可能包含查询要求数据,需要向这些节点发送请求获取数据。全局索引实例被组织在一个overlay网络中,由于p-tree路由表的更新策略不如baton,且其和p-grid都不是平衡树,因此在面对数据倾斜时性能较差。考虑这些因素后,本发明使用baton作为overlay网络。
baton(balancedtreeoverlaynetwork)把所有节点组织成一颗平衡树,每个节点负责存储属于某一个范围的数据,其不仅支持属性的点查询,同样也支持属性的范围查询。在一个有n节点的baton网络中,点查询和范围查询最多经过logn步就可以得到响应。
一个baton网络的结构如图5所示,baton网络在拓扑上是一颗平衡二叉树,树中的每一个节点对应overlay网络中的一个节点。每个节点都负责维护着level、number、parent、leftchild、rightchild、leftadjacent、rightadjacent、lower、upper等9个属性,同时还维护着一个左路由表和右路由表。其中,level代表该节点在baton中的层级,例如根节点的层级为0,以此类推;number则代表该节点在某一层是第几个节点,默认从1开始编号。层级l上最多有2l节点,不管节点是否真实存在,都默认从左到右编号;parent记录父节点的相关信息;leftchild和rightchild分别记录左孩子节点和右孩子节点的相关信息;leftadjacent和rightadjacent分别记录前驱节点和后继节点的相关信息,中序遍历该平衡树决定了前驱和后继的关系,因此第一个节点没有前驱节点,最后一个节点没有后继节点;lower和upper则表示该节点可以存储哪些信息,对于数据的键在[lower,upper)的范围内,应该存储在该节点。左右路由表则分别记录左右两个方向的详细节点信息,在插入数据和查询数据时需要根据左右路由表来判断请求下一跳应该交给哪一个节点来处理。
一个baton网络提供的核心api如下表所示:
表1batonapi
本发明需要插入的数据是一个四元组,其形式类似于四元组(timeindex,left,right,ip),元组核心是一个时间序号timeindex以及一个范围[left,right),将其插入baton网络并非不可行,例如以左值left或右值right作为key,根据baton网络的路由规则插入数据。但是这么做会使得查询的效率偏低,因为在考虑插入时只考虑一个点,而没有考虑范围长度的影响。参考相关设计,可以考虑为baton网络中的节点增加一个属性:子树范围,即以该节点为根的树管理的范围。在选择插入时考虑节点的子树范围是否包含了该范围。在原baton网络中,数据存储在一个动态数组中,考虑到插入的元组中有timeindex属性,因此使用哈希表和动态数组的组合来存储实际的数据。
局部索引发布的索引摘要是一个四元组tuple=<timeindex,left,right,ip>。其中timeindex表示该索引摘要的时间序号,left和right表示索引摘要范围的左值和右值,ip则表示该索引摘要来自哪一个机器。
以插入索引摘要tuple=<timeindex,left,right,ip>为例,索引摘要的发布过程如下所示。
(1)根据baton网络的路由规则找到适合存储tuple.left的节点n。
(2)如果n的子树范围包括了[tuple.left,tuple.right),把tuple存储在该节点,同时判断右孩子的子树范围是否与tuple相交,相交则设置右孩子的tagvalues,跳出循环;否则设置n的tagvalues,并且令n等于n的父节点,继续步骤(2)。
上述操作平均可以在logn步内完成。同时为了在查询时减少向上查找的次数,每个节点针对不同的timeindex需要存储两个值tagvalues以供查询时判断使用。
一个摘要查询可以定义为query=<timeindex,left,right>,其中timeindex是时间序号,left和right是待查询摘要的左值和右值,因此摘要查询的过程实际上就是在baton网络中查找时间序号为timeindex,且与[left,right)相交的索引摘要的ip集合,因此可以总结为:首先寻找到第一个子树范围包括查询范围的节点,从该节点开始广播查询子节点的内容,同时根据tagvalues的内容判断是否需要向父节点查找是否包含内容,由最后一个节点负责返回查询结果。
客户端模块主要是用来封装时空范围查询的api,并对外提供一个简单的调用接口,简化操作。以跨云时空范围查询q为例,客户端模块的主要步骤可描述如下:
1.对于跨云时空范围查询q,将其中的空间范围转化为z值的数组,将时间范围转化为时间序号。
2.根据时间序号的区分,将z值的数组整合后转化为索引摘要查询,向全局索引发出查询请求,并得到返回结果。
3.根据返回的结果,再次封装查询请求,向相应的局部索引节点请求数据,获得结果。
4.根据时间范围返回过滤掉部分结果,并最后整合结果返回。
客户端模块的整体调用逻辑比较简单,在实现时主要注意并行化操作,加快查询速度。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!