一种面向实体和用户画像的特征融合方法与流程
本发明属于大数据特征融合领域,特别涉及一种面向实体和用户画像的特征融合方法。
背景技术:
随着社会的发展与进步,用户画像的构建越来越重要,用户画像能够利用数据的多维度视图,客观真实的反映出用户的行为轨迹、习惯特点及服务需求等,为各领域的服务能力提升,数据分析的挖掘提供了必要的技术支撑,在政府大数据融合和认知领域,随着近几年的实体和用户画像匹配任务在人工智能、机器学习等领域中逐渐变得热门。我们现在可以构建一个能根据实体内容匹配合适用户画像的实体和用户画像匹配系统,反之亦然。这使得无须再进行繁琐的、重复的人工搜索,减轻工作压力。而作为一个实体和用户画像匹配系统,其必须同时关注实体和用户画像这两个属于不同模态的研究对象,因此实体和用户画像匹配是属于多模态(multimodal)的任务,需要精准地抽取实体和用户画像的特征。特别是对于用户画像来说,由于其表达同样事物的方式更为丰富,因此获取用户画像的特征尤为困难。
实际上,在实体和用户画像匹配中为了更丰富和更有效率地对用户画像进行表征,现有技术的做法是直接使用预训练网络中的单层特征去作为用户画像特征,或者对该单层特征进一步进行微调。换言之,也就只能使用到预训练任务所归纳的某一单层次特征,或者只能从该单层次特征的基础上进一步进行归纳。但是,预训练任务和实际研究的实体和用户画像匹配任务是有一定差别的。直接使用某一单层次的预训练特征会存在实体和用户画像匹配所需要的特征并没有被归纳到的情况,同时也存在大量没有作用的噪声特征。再者,对单层次的预训练特征进行微调也未能利用到其它层次的有用特征。因此,直接使用或微调预训练网络的某一单层次特征并没有充分地、合理地使用这种预训练特征。在实体和用户画像匹配中如何更好地利用预训练特征,准确地表征用户画像,针对政府数据开放共享中面临的数据资源整合困难,如何解决制约政府大数据在多源数据融合和认知的技术难点,面向实体对象(如人、物、事件等),综合关系型数据的准确性、开放社会数据的广泛性和行业数据的深度性特征,突破多模态数据关联和用户画像技术,具有一定的研究价值和意义。
技术实现要素:
本发明的目的是提供一种能够充分地、合理地利用更多有用的预训练图像特征,降低特征维度,减少噪声干扰的面向实体和用户画像的特征融合方法。
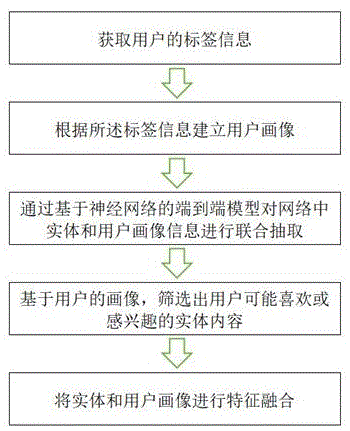
为实现上述目的,本发明的技术方案是:一种面向实体和用户画像的特征融合方法,包括以下步骤:
步骤1:获取用户的标签信息;
步骤2:根据所述标签信息建立用户画像;
步骤3:通过基于神经网络的端到端模型对网络中实体和用户画像信息进行联合抽取;
步骤4:基于用户的画像,筛选出用户可能喜欢或感兴趣的实体内容;
步骤5:将实体和用户画像进行特征融合。
进一步的,所述步骤1中所述获取用户的标签信息,包括:获取互联网中的各类数据,并将获取的互联网中的各类数据进行融合形成知识库;获取用户的上网日志;将所述上网日志与所述知识库进行匹配形成用户标签信息。
进一步的,所述步骤2所述标签信息,包括:数据计算出来的统计类标签信息、建模算法得出的模型类标签信息、单客户标签信息和标签体系用户群信息;所述统计类标签包括地域信息、人口基本属性信息;所述模型类标签包括用户行为偏好、用户消费价值度、用户消费习惯预测。
进一步的,所述获取互联网中的各类数据,并将获取的互联网中的数据进行融合形成知识库,包括:采用分布式爬虫爬取方式获取互联网各类数据;对所述获取的互联网各类数据进行细化类别,然后进行标签自动归并,并将类别进行统一。
进一步的,所述步骤2所述根据所述标签信息建立用户画像的步骤包括:将用户的一个或者多个标签信息组成一个文本向量;将所述文本向量作为用户的用户画像。
进一步的,所述步骤4所述基于用户的画像,筛选出用户可能喜欢或感兴趣的内容,包括:根据用户在网络中的历史数据进行数据分析,分析用户可能喜欢或者感兴趣的内容;所述历史数据包括用户的消费习惯数据、浏览网页数据、购物数据、外卖数据、团购数据、购买电影票数据、app使用习惯数据、用户画像结果数据。
进一步的,所述步骤5所述将实体和用户画像进行特征融合,包括以下步骤:
(1)文本表征,预设m1个分词处理好文本数据,分别为
(2)多层次实体表征,具体包括以下步骤:
①预设m2个实体数据,分别为
②把实体输入到该预训练卷积神经网络中,并对预训练网络中的n层特征进行拼接,以作为实体的多层次总预训练特征;
(3)为了从多层次的预训练特征中归纳出对实体和用户画像匹配任务有用的特征和舍弃无用的噪声特征,构建一个多层感知机(multi-layerperceptron,mlp);
(4)利用实体和用户画像匹配的学习目标,指导多层感知机mlp对实体的多层次总预训练特征进行融合和降维,生成融合特征。
进一步的,所述步骤①所述的实体分类数据集为imagenet数据集。
进一步的,所述步骤②中,把实体ik输入到预训练卷积神经网络中,即可生成对应的多层次总预训练特征
其中
进一步的,所述步骤⑶所述的多层感知机mlp的各层维度随着深度增加相应降低,以满足对高维度且包含大量噪声特征的多层次总预训练特征进行融合和降维的需要,并且该多层感知机mlp的输出层维度与文本特征的维度一致,在多层感知机mlp的隐藏层和输出层设置非线性激活函数,以增强表达能力。
本发明的有益效果是:针对表精准治理、惠民服务等场景的需求,面向实体对象(如人、物、事件等),围绕人口、法人单位等国家基础信息数据以及信用、社保等领域数据资源,融合互联网社会面数据,提出一种从网络数据中抽取与实体和用户画像特征进行融合的方法,具有以下几个有点:
(1)使用预训练网络的多个特征层能够充分地利用更多有用的、不同层次的预训练图像特征,防止实体和用户画像匹配任务未能得到充分的用户画像特征信息。
(2)在实体和用户画像匹配的学习目标指导下,融合和降维的过程能在预训练特征中归纳出对实体和用户画像匹配任务有用的特征,去除无用的特征,减少了噪声特征的干扰。
(3)避免了多特征融合中容易出现的特征维度过高,不同类型的特征维度不一致、计算量较大等问题,稳定性较高。
采用本发明,能够解决政府数据开放共享中面临的数据资源整合困难,解决制约政府大数据在多源数据融合和认知的技术难点,面向实体对象(如人、物、事件等),提高关系型数据的准确性、开放社会数据的广泛性和行业数据的深度性特征。
附图说明
图1为本发明的流程示意图。
具体实施方式
下面结合附图实施例,对本发明做进一步描述:
实施例1
本发明的简要步骤参见图1,包括:
(1)获取用户的标签信息;
获取互联网中的各类数据,并将获取的互联网数据进行融合形成知识库;
获取用户的上网日志;
将所述上网日志与所述知识库进行匹配形成用户标签信息。
采用分布式爬虫爬取方式获取互联网各类数据;
对所述获取的互联网中的各类数据进行细化类别,然后进行标签自动归并,并将类别进行统一。
具体的,用户的标签信息可以是用户的固有属性,也可以是用户的动态属性,还可以是两者的结合,可以根据不同的业务场景获取不同的标签信息。其中,固有属性包括用户的年龄、性别、职业、收入水平、婚育状况等属性,动态属性包括用户购买的历史行为,浏览观看的记录等属性。
获取互联网各类数据时采用分布式爬虫爬取方式,所述分布式爬虫采用主从模式部署,主控节点将用户设置的统一资源定位符(uniformresourcelocator,url)抓取任务分发到各爬虫节点,爬虫节点负责具体的网页下载解析任务,主控节点根据各工作节点的负载情况进行负载均衡。同时,此种方式具有良好的可伸缩性,当系统过载时,通过增加爬虫节点来分担爬取任务。爬虫通过执行定时任务来实现所爬内容的不断自动更新。
获取的各种互联网数据包括以下几大类:门户网站,视频网站,电商网站,旅游网站,论坛,微博、微信等。此时由于数据量巨大,为便于构建用户标签,将互联网数据融合打通时,首先对互联网数据细化类别,然后进行标签自动归并,将类别进行统一。例如,门户网站知识库将细化到最细一级类别,以新浪为例,将实现诸如“科技”-“互联网”两级标签;视频网站将细化到具体某个节目详情,如“电视剧”-“大陆剧”-“琅琊榜”-“主演导演”;电商网站将细化到具体商品详情,如“大家电”-“洗衣机”-“海尔”-“xqg70-b12866”-“7kg/公斤全自动变频静音滚筒洗衣机,价格2199”。由于各网站的类目不统一(例如服装与衣服均表示一类事物,但归并时会造成数据繁冗,处理困难),因此在知识库中建立了同义词库,将各类互联网数据做融合打通时,首先根据同义词库进行标签自动归并,将类别进行统一;可能会剩下的小部分不可归并类别,则由人工参与检查后可以进行自动新标签追加,大大减轻工作量。针对移动应用端的抓取数据,例如app应用等,由于无法细化,需要人工抓包归类,以上爬虫爬取的类目标签在与上网日志做匹配后将组成用户媒体标签和购买标签。
(2)根据所述标签信息建立用户画像;
所述标签信息包括:
数据计算出来的统计类标签信息、建模算法得出的模型类标签信息、单客户标签信息和标签体系用户群信息;
所述统计类标签包括地域信息、人口基本属性信息;
所述模型类标签包括用户行为偏好、用户消费价值度、用户消费习惯预测。
具体的,统计类标签包括地域信息、人口基本属性信息等。模型类标签包括用户行为偏好,用户消费价值度,用户消费习惯预测等。单客户标签是指在整个的标签体系中,给某个指定的用户赋值的标签。用户群信息是指符合某些特征的用户群体。
将用户的一个或者多个标签信息组成一个文本向量;
将所述文本向量作为用户的用户画像。
具体的,用户画像是一种勾画目标用户、联系用户诉求与设计方向的有效工具。在实际操作的过程中往往会以最为浅显和贴近生活的话语将用户的属性、行为与期待联系起来。在本实施例中,用户画像是由获取的多个标签信息组成的,将获取的多个标签信息组成为一个文本向量,将组成的文本向量作为该用户的用户画像。
将获取的用户的多个标签信息组成一个长的文本向量,用户的标签信息可以包括用户的性别、年龄、消费属性、职业、收入水平、婚育状况等等。根据不同的业务场景,可以获取不同的标签信息。
所述标签信息还包括媒体标签、购买标签、搜索标签、行业标签、用户性别、年龄段等。
用户历史状态的向量表示:对于相应的业务营销活动用户的历史数据的二元化向量表示方法。
具体的,将用户标签组成的用户的文本向量作为用户的用户画像,用户画像作为实际用户的虚拟代表,其往往是根据产品和市场来构建出来的,反应了真实用户的特征和需求。
(3)通过基于神经网络的端到端模型对网络中实体和用户画像信息进行联合抽取;
通过lstm神经网络对文本描述信息进行抽取,并将其与知结构化信息源融合到一起时,通过门控机制平衡结构化信息和文本描述信息。由此方法学习并得到实体和用户画像的相关文本描述信息,并将其与结构化信息相结合,可以更精确有效地表示实体和用户画像及其之间相互联系。
(4)基于用户的画像,筛选出用户可能喜欢或感兴趣的实体内容;
具体的,根据用户在本网络或者其他网络中的历史数据进行数据分析,分析用户可能喜欢或者感兴趣的内容;
所述历史数据包括用户的消费习惯数据、浏览网页数据、购物数据、外卖数据、团购数据、购买电影票数据、app使用习惯数据、用户画像结果数据。
具体的,可以通过获取用户的网络数据包,判断用户是否通过并成功接入网络登录应用程序客户端,如qq、微信、微博、京东、淘宝等应用程序客户端,即将获取到用户登录的应用程序作为网络数据包判断用户是否接入网络,从而对结合用户画像对用户当前的网络行为和上网行为轨迹做预测分析。例如,用户登录了京东,则预测用户可能有购买或消费的需求;通过获取用户画像中的历史网络访问数据,例如在京东中的搜索关键字(例如,nike、跑步鞋、wilson网球拍等)、访问的网站类型(例如,电子商务网站、新闻网站等)、搜索商品的信息(例如,nike、跑步鞋、wilson网球拍等),从而获得用户可能感兴趣的信息类型。
(5)将实体和用户画像进行特征融合;
具体的,文本表征,预设m1个分词处理好文本数据,分别为
多层次实体表征,具体为:
预设m2个实体数据,分别为
把实体输入到该预训练卷积神经网络中,并对预训练网络中的n层特征进行拼接,以作为实体的多层次总预训练特征,具体为:
把实体ik输入到预训练卷积神经网络中,即可生成对应的多层次总预训练特征
其中
为了从多层次的预训练特征中归纳出对实体和用户画像匹配任务有用的特征和舍弃无用的噪声特征,构建一个多层感知机(multi-layerperceptron,mlp),并且各层维度随着深度增加相应降低,以满足对高维度且包含大量噪声特征的多层次总预训练特征进行融合和降维的需要,并且该多层感知机mlp的输出层维度与文本特征的维度一致,在多层感知机mlp的隐藏层和输出层设置非线性激活函数,以增强表达能力。
利用实体和用户画像匹配的学习目标,指导多层感知机mlp对实体的多层次总预训练特征进行融合和降维,生成融合特征。
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!