一种基于协同训练的文本分类辅助标注方法与流程
本发明涉及文本分类技术领域,尤其涉及一种基于协同训练的文本分类辅助标注方法。
背景技术:
近年来,随着大数据时代的到来,机器学习和人工智能的迅猛发展,从业人员对于数据的需求也越来越迫切,标注人员的有限工作量已经越来越无法满足人们对海量数据的需求,并且人工标注带来很多缺点,人工标注时间成本和经济成本较高,而且人工标注难免会出现不可避免的错误,这使得标注的语料质量不高。
人工智能尤其是自然语言处理以及图像处理,所面临的一个棘手的现状是:监督学习方法需要获得大量的标注语料,想要获得这些语料,那么需要投入大量的人力和物力。研究表明,获取未标注语料的时间几乎是获取标注语料时间的十分之一,因此对于大量的未标注语料是非常容易获得的,目前数据及标注方法包括手工标注、机器学习标注以及众包标注。
传统的手工标注方法顾名思义,需要专业人员来指定专门的标注规则,标注的语料质量高,但是需要付出高额的时间代价和金钱代价。、
机器学习标注方法,譬如逻辑回归、支持向量机以及朴素贝叶斯等有监督的机器学习方法,可以实现语料的快速标注,但是这些模型的训练依赖于高质量的数据标注,并且在处理多分类的语料时,表现得并不出色。
众包标注是以众包理论为基础,针对各项任务指定专门的标注系统和标注任务,之后对样本进行随机抽样,然后交给专门的人员进行标注,然而这对于与专业人员的要求比较高,依赖性比较大,需要大量的数据复核工作。
在自然语言处理中的文本分类领域中,经常会遇到文本多分类的问题,多的可能有上百个label,这就对于标注的数量要求非常大,而普通的标注人员他们更擅长的是进行语料的二分类,对于他们而言,如果一次性地标注数量众多个label,这是非常困难且低效的。因此,如何高效低成本地将未标注语料标注成高质量的数据成为了迫在眉睫的任务。
技术实现要素:
本发明的目的在于提供一种基于协同训练的文本分类辅助标注方法,能够将大部分简单数据自动完成高质量的标注,这大大地提高了标注的准确率和效率。
为实现上述目的,本发明提供如下技术方案:
一种基于协同训练的文本分类辅助标注方法,其特征在于,包括以下步骤:
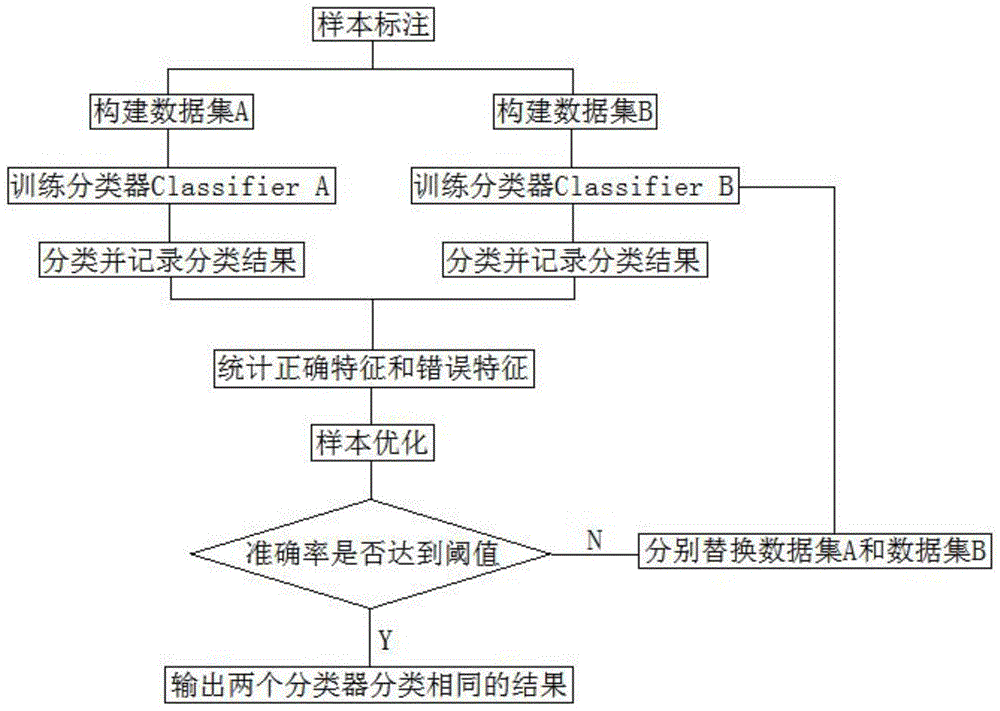
s1,对样本数据进行标注,每一样本数据对应一个标签;
s2,采用已标注的样本数据分别构建数据集a和数据集b,其中数据集a的标签随机分布,数据集b的标签均匀分布;
s3,使用数据集a训练以字向量为输入的分类器classifiera,使用数据集b训练以词向量为输入的分类器classifierb;
s4,训练结束后,采用剩余已标注的样本数据另构建数据集e和数据集f,分别输入分类器classifiera和分类器classifierb中进行分类,并记录分类结果;
s5,根据数据集e的分类结果统计分类器classifiera的正确特征和错误特征,根据数据集f的分类结果统计分类器classifierb的正确特征和错误特征;
s6,样本优化,删除数据集a中包含两个或两个以上分类器classifiera的错误特征的数据,再结合分类器classifierb中分类错误的数据构成数据集b+;删除数据集b中包含两个或两个以上分类器classifierb的错误特征的数据,再结合分类器classifiera中分类错误的数据构成数据集a+;
s7,以数据集a+替换数据集a,数据集b+替换数据集b,回到步骤s4直至分类结果准确率达到置信度阈值;
s8,将未标注数据同时输入分类器classifiera和分类器classifierb,仅在分类结果相同的情况下输出分类结果。
进一步的,所述s5中分类器classifiera/分类器classifierb正确特征的确定方法如下:
取数据集e/数据集f中分类正确的数据,统计分类正确的数据中每个词在不同标签下的概率分布;通过top-k算法筛选每个词概率最高的前k个数据,求其方差,若方差大于预先设定的方差阈值,则该词为分类器classifiera/分类器classifierb的正确特征。
进一步的,所述s5中分类器classifiera/分类器classifierb错误特征的确定方法如下:
取数据集e/数据集f中分类错误的数据,统计分类正确的数据中每个词在不同标签下的概率分布;通过top-k算法筛选每个词概率最高的前k个数据,求其方差,若方差大于预先设定的方差阈值,则该词为分类器classifiera/分类器classifierb的错误特征。
进一步的,所述方差阈值为0.05。
进一步的,所述s6中,数据集a/数据集b包含分类器classifiera/分类器classifierb的错误特征的判断标准为:统计数据集a/数据集b中每个词在不同标签下的概率分布,与分类器classifiera/分类器classifierb的错误特征的概率分布进行比较,若两个分布的kl散度小于预先设定的散度阈值,则认为数据集a/数据集b中该词为分类器classifiera/分类器classifierb的错误特征。
进一步的,所述散度阈值为0.2。
与现有技术相比,本发明的有益效果是:本发明用两个分类器,可以做到从不同角度审视数据,大大地降低了标注的时间,极大地提升了标注的准确性和时间效率,在短时间内可以获得高质量的标注语料。本发明可根据实际情况设定相应的置信度阈值将大部分的简单数据自动标注完成,减少了标注人员的重复多余的工作,提高了标注人员的资源利用效率。
附图说明
图1为本发明的整体结构示意图;
具体实施方式
下面对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种基于协同训练的文本分类辅助标注方法,其特征在于,包括以下步骤:
s1,对样本数据进行标注,每一样本数据对应一个标签;首先,有大量未标注数据集合u,现从该数据集合u中随机抽取几万条数据进行标注作为样本数据。每一条数据为短文本数据,标签为该短文本数据的意图,由人为判断。如一条短文本数据的具体内容为“我在上周下单的衣服在什么时候能够发货”,则在标注的时候,将其归类为“何时发货”该标签下,代表其文本意图。
s2,分别采用3000条已标注的样本数据分别构建数据集a和数据集b,其中数据集a的标签随机分布,数据集b的标签均匀分布;即从原本几万条数据构成的数据集u中随机抽取3000条数据构建数据集a,则其各数据对应标签的数量呈随机分布。再从剩余数据中有选择性地抽取3000条数据,该3000条数据中,对应每一标签的数量平均分布。
s3,使用数据集a训练以字向量为输入的分类器classifiera,使用数据集b训练以词向量为输入的分类器classifierb;优选的,本申请中分类器classifiera和分类器classifierb的结构为cnn神经网络,具体选用textcnn分类器。
s4,训练结束后,采用数据集u中剩余已标注的样本数据分别提取3000条另构建数据集e和数据集f,并将数据集e和数据集f分别输入分类器classifiera和分类器classifierb中进行分类,并记录分类结果;若分类结果与该数据预先标注的标签一致,则认为分类正确,否则分类错误,同时计算其准确率。如,分类器classifiera分类结果有2200条分类正确,800条分类错误;分类器classifierb分类结果中有2300条分类正确,700条分类错误,则其准确率为(2200+2300)/6000×100%=75%。
s5,根据数据集e的分类结果统计分类器classifiera的正确特征和错误特征,根据数据集f的分类结果统计分类器classifierb的正确特征和错误特征。
具体的,分类器classifiera/分类器classifierb正确特征的确定方法如下:取数据集e/数据集f中分类正确的数据,统计分类正确的数据中每个词在不同标签下的概率分布(如“发货”这个词在“何时发货”这个标签下的出现频率很高,其他标签下很少出现。因此对应的“何时发货”这个标签的概率很高,甚至达到90%以上);通过top-k算法筛选每个词概率最高的前5个数据,求其方差,若方差大于预先设定的方差阈值,所述方差阈值优选为0.05,则该词为分类器classifiera/分类器classifierb的正确特征。方差表达了该次在不同标签下概率的分散程度,若一个词均匀得分散在不同的标签下,则代表该次对于标签分类的过程没有作出贡献,为干扰项,因此不能作为正确特征;反之,若该词在某一个标签下很集中,在其他的标签下几乎没有出现,其方差相应较大,说明其能够反映文本的意图,即对分类作出了巨大贡献。
同理,分类器classifiera/分类器classifierb错误特征的确定方法如下:取数据集e/数据集f中分类错误的数据,统计分类正确的数据中每个词在不同标签下的概率分布;通过top-k算法筛选每个词概率最高的前5个数据,求其方差,若方差大于预先设定的方差阈值,所述方差阈值优选为0.05,则该词为分类器classifiera/分类器classifierb的错误特征。
s6,样本优化,删除数据集a中包含两个或两个以上分类器classifiera的错误特征的数据,再结合分类器classifierb中分类错误的数据构成数据集b+;同理,删除数据集b中包含两个或两个以上分类器classifierb的错误特征的数据,再结合分类器classifiera中分类错误的数据构成数据集a+。这里之所以结合分类错误的数据,是因为分类错误的数据包含的信息价值更大。而数据集a用分类器classifierb预测错误的数据,数据集b用分类器classifiera预测错误的数据是因为,分类器classifiera和分类器classifierb从不同的角度审视数据,分类器classifiera既然分类错了,这部分分类错的数据显然包含了分类器classifiera没有学习到的特征。这里是希望分类器classifierb能学习到分类器classifiera没有学习到的特征,继续构造差异。分类器classifiera和分类器classifierb差异越大,对于分类器classifiera和分类器classifierb共同判断正确的句子的可信度也就越大。
具体的,数据集a/数据集b包含分类器classifiera/分类器classifierb的错误特征的判断标准为:统计数据集a/数据集b中每个词在不同标签下的概率分布,与分类器classifiera/分类器classifierb的错误特征的概率分布进行比较,若两个分布的kl散度小于预先设定的散度阈值,所述散度阈值优选为0.2,则认为数据集a/数据集b中该词为分类器classifiera/分类器classifierb的错误特征。
s7,以数据集a+替换数据集a,数据集b+替换数据集b,回到步骤s3,重复步骤s4至步骤s6,直至分类结果准确率达到置信度阈值,置信度阈值优选为90%;
s8,将未标注数据同时输入分类器classifiera和分类器classifierb,仅在分类结果相同的情况下输出分类结果;若分类结果不同,则进行人工标注。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。
- 还没有人留言评论。精彩留言会获得点赞!