一种基于YOLOv3深度学习的混凝土裂缝识别方法与流程
本发明属于混凝土结构损伤检测技术领域,尤其涉及一种基于yolov3深度学习的混凝土裂缝识别方法。
背景技术:
混凝土是当今用途最广、用量最大的一种建筑材料,广泛应用于道路、桥梁、房建、隧道及大坝等基础设施的建设中。由于混凝土抗拉强度低,受收缩徐变、外界温度变化、地基变形等内外因素的共同影响,在施工建设和运营使用的过程中经常出现不同程度和形式的裂缝病害。裂缝的扩展是结构破坏的初始阶段;随着裂缝的持续发展,裂缝的宽度一旦超出一定限制,不仅影响基础设施的外观,也可能引起渗漏、耐久性降低、保护层脱落、钢筋锈蚀、混凝土碳化等,甚至对行车及行人安全造成重要影响。因此定期检测混凝土结构表面的裂缝病害状况,并针对检测结果进行预先防治是必不可少的。
混凝土强度的细观研究及工程实践经验表明,混凝土结构开裂不可避免。如果对混凝土结构的裂缝评价要求过高,会导致繁杂且高成本的维护代价,科学的做法应该是设定一个限制。一般来说,同一条裂缝上的裂缝宽度是不均匀的,控制裂缝宽度是指较宽区段(该裂缝长度的10%~15%范围)的平均宽度,这样确定的平均裂缝宽度为该裂缝的最大宽度。同样,该裂缝宽度较窄区段(裂缝长度的10%~15%范围)的平均宽度为最小裂缝宽度。在最大与最小之间为平均裂缝宽度。
一般肉眼可见的最小裂缝宽度是0.05mm,通常将小于0.05mm的裂缝称为微观裂缝,大于或者等于0.05mm的裂缝称为宏观裂缝,宏观裂缝是微观裂缝扩展的结果。一般的混凝土构筑物中宽度小于0.05mm的裂缝对使用并无危险,因此,可认为具有小于0.05mm微观裂缝的结构为无裂缝结构。所以,设计中所谓不允许开裂的结构也只能是无大于0.05mm裂缝的结构。
混凝土最大裂缝宽度的控制标准大致如下:无侵蚀介质,无防水要求的,0.3~0.4mm;轻微侵蚀,无防水要求的,0.2~0.3mm;严重侵蚀,有防水要求的,0.1~0.2mm。中国《城市桥梁检测与评定技术规范》中规定桥梁裂缝宽度不得超过0.3mm。
裂缝按其形状分为表面的、贯穿的、纵向的、横向的、上宽下窄的、下宽上窄的、枣核形的、对角线的、斜向的、外宽内窄的和纵深的(深度达1/2厚度)等等。裂缝的形状与其受力状态有直接关系,大多数裂缝的方向同主拉应力方向垂直,而纯剪裂缝的方向则同剪应力方向平行。准确识别出混凝土结构中的裂缝长度、走向和宽度,对判断结构的病害程度和运营状况有重要意义,这同时也是混凝土结构健康检测所面临的一个巨大难题。
早期所采用的裂缝检测方法以人工检测为主,需要维护人员进行现场勘查、标记、测量,并记录检测结果。人工检测方式工作强度大、效率低且不安全,需要借助检测辅助设备接近结构表面,对检测人员的专业知识和经验要求较高。此外,人工检测的结果受人为主观的影响,导致测量结果不一致、测量精度低等。同时,在桥梁、隧道等交通要道上进行人工检测有时还需封闭场地。这极大地影响了正常的交通,为车辆、行人的正常通行带来不便,严重时甚至会导致交通事故的发生。
较先进的无损检测方法如超声波法、热成像法、计算机断层扫描技术及电磁-声发射传感器检测法,存在着仪器昂贵、测量范围小、无法完全实现非接触测量等缺点。2000年左右,基于计算机视觉技术(ipts)的图像处理方法开始用于混凝土表面裂缝的识别。ipts的一个显著优点是可以识别几乎所有的表面缺陷(例如裂缝和腐蚀等)。但是图像的光照强度、明暗变化和图像扭曲等因素会严重影响检测结果,而且在处理过程中产生大量噪声,使得图像中的混凝土裂缝目标在传统的计算机视觉技术中难以被准确、高效地识别出来。
与本发明最接近的边缘检测法是图像处理技术中最常用的方法,其常用算子一般有一阶导数如sobel算子和canny算子,二阶导数如laplacian算子。边缘检测法的核心原理是检测出周围像素灰度发生急剧变化的像素点的集合。在灰度变化较为均匀的图像中,只利用一阶导数算子得到的边界比较粗,甚至找不到边界;而基于过零检测的二阶导数算子对噪声比较敏感,即便可以检测出边缘,获得的边缘点数也比较少。由于混凝土图像背景整体灰度差异小,裂缝边缘像素梯度低,通常属于弱边缘,边缘检测法应用于裂缝识别领域中效果较差。
伴随着人工智能的快速发展,深度学习算法被广泛应用在图像处理的各个方面。基于深度学习的图像处理技术的出现,为混凝土裂缝检测提供了一个很好的解决思路。已有部分学者应用深度学习理论在混凝土裂缝识别方面提出了一些方法,如在不计算缺陷特征的情况下检测裂缝、提出一种检测每个视频帧内的裂缝的深度学习框架并提出一种新的数据融合方案聚合信息、应用主成分分析法(pca)对裂缝进行分类等。这类方法一般基于滑动窗口技术和深度学习,其中滑动窗口技术没有针对性,由于目标裂缝的宽度较小,滑动窗口技术产生的大部分窗口通常都为冗余窗口,实际有效的窗口数量只占很少一部分,大量运算资源被浪费,运算成本高,且检测效率低;深度学习方法则对数据量的要求大,这也是深度学习发展的最大瓶颈,为了解决这一问题,一些自带数据集,并已经提取了部分目标特征以便于使用的深度学习网络框架得到了广泛应用。如何在这些搭建好的框架下更好地实现特定目标地检测识别,是目前混凝土结构损伤检测领域中需要迫切解决的问题。
综上所述,现有技术存在的问题是:目前常用的边缘检测法不适用于裂缝识别领域;基于滑动窗口技术的深度学习方法,需要大量的数据,缺少针对性,运算成本高,且检测效率低。
解决上述技术问题的难度:在世界范围内缺少公认有效的裂缝数据集,而人工制作数据集需要花费大量的人力物力,成本高;对复杂的模型网络结构进行简化,减少网络的中间输出的同时保持检测的准确率和速度,需要大量时间对网络进行调整、试算、训练等。
解决上述技术问题的意义:在数据集有限的情况下即可获得准确的识别结果,并且输入图像经过单次检测,便能获得图像中所有待检测目标,实现了端到端的目标检测和识别,即使实现输入端——单个神经网络——输出端,减少了冗余数据的产生,降低运算成本。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于yolov3深度学习的混凝土裂缝识别方法。
本发明是这样实现的,一种基于yolov3深度学习的混凝土裂缝识别方法,所述基于yolov3深度学习的混凝土裂缝识别方法采用yolov3中的darknet-53网络作为特征提取器,将目标检测作为回归问题处理,基于一个单独的端到端神经网络模型直接进行目标区域定位及目标类别预测;
将裂缝图像导入yolov3,图像被自动压缩为416×416像素分辨率;采用类似fpn的上采样和特征融合方式,将原始图像按特征图的尺度大小划分为s×s网格;以候选框与真实框的交并比作为评价标准,对图像训练集的所有裂缝目标标注框使用k-means聚类分析,以获得候选框的大小;yolov3对每个边界框通过逻辑回归预测该框包含目标的概率。
进一步,所述基于yolov3深度学习的混凝土裂缝识别方法具体包括:
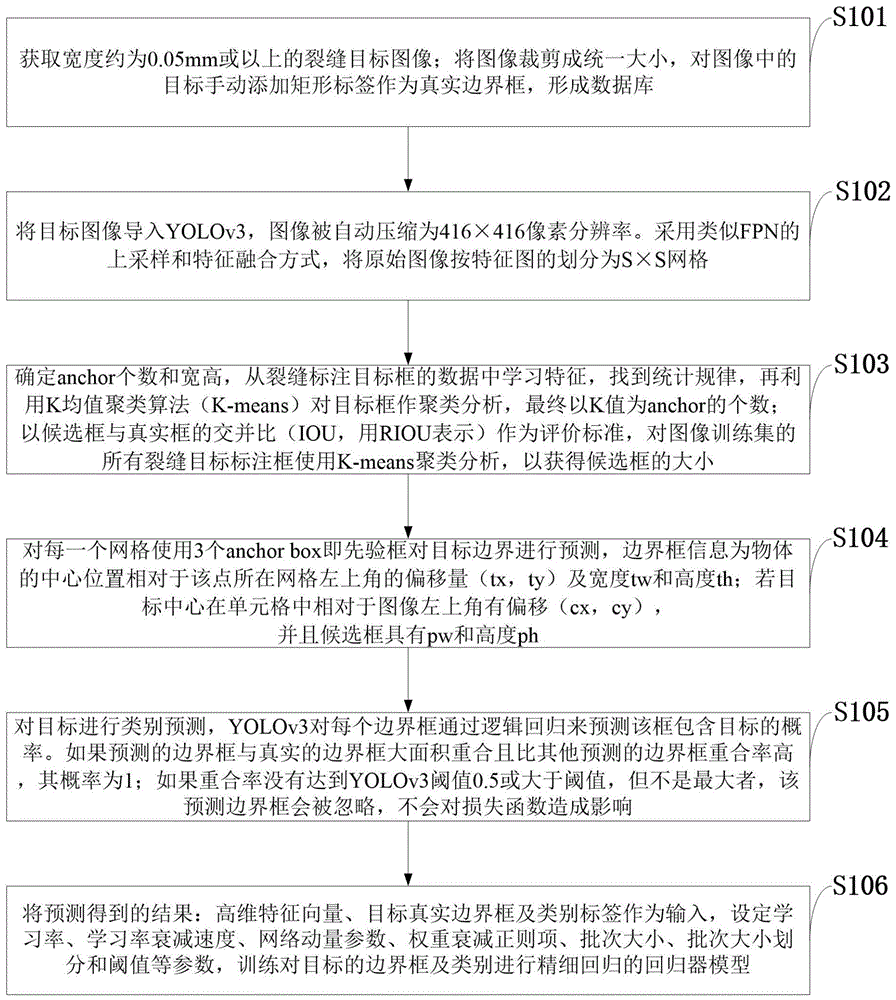
第一步,获取宽度约为0.05mm或以上的裂缝目标图像;将图像裁剪成统一大小,对图像中的目标手动添加矩形标签作为真实边界框,形成数据库;
第二步,将目标图像导入yolov3,图像被自动压缩为416×416像素分辨率。采用类似fpn的上采样和特征融合方式,将原始图像按特征图的划分为s×s网格;
第三步,确定anchor个数和宽高,从裂缝标注目标框的数据中学习特征,找到统计规律,再利用k均值聚类算法对目标框作聚类分析,以k值为anchor的个数;以候选框与真实框的交并比作为评价标准,对图像训练集的所有裂缝目标标注框使用k-means聚类分析,以获得候选框的大小;
第四步,对每一个网格使用3个anchorbox即先验框对目标边界进行预测,边界框信息为物体的中心位置相对于该点所在网格左上角的偏移量(tx,ty)及宽度tw和高度th。若目标中心在单元格中相对于图像左上角有偏移(cx,cy),并且候选框具有宽度pw和高度ph;
第五步,对目标进行类别预测,yolov3对每个边界框通过逻辑回归来预测该框包含目标的概率;如果预测的边界框与真实的边界框大面积重合且比其他预测的边界框重合率高,其概率为1;如果重合率没有达到yolov3阈值0.5或大于阈值,但不是最大者,该预测边界框会被忽略,不会对损失函数造成影响;
第六步,将预测得到的结果:高维特征向量、目标真实边界框及类别标签作为输入,设定学习率、学习率衰减速度、网络动量参数、权重衰减正则项、批次大小、批次大小划分和阈值,训练对目标的边界框及类别进行精细回归的回归器模型。
进一步,所述第三步k-means聚类的距离函数为;
d(b,c)=1-riou(b,c);
式中b为矩形框的大小,c为矩形框的中心,riou(b,c)表示候选边界框与真实边界框的交并比。
进一步,所述第四步的边界框信息为物体的中心位置相对于该点所在网格左上角的偏移量(tx,ty)及宽度tw和高度th;若目标中心在单元格中相对于图像左上角有偏移(cx,cy),并且候选框具有宽度pw和高度ph,则修正后的边界框为:
bx=σ(tx)+cx
by=σ(ty)+cy
进一步,所述第五步对目标进行类别预测;每个预测任务得到的特征大小为:
s×s×[3×(4+l+b)];
式中s为网格大小,3为每个网格的先验框数量,4是边界框大小和坐标,1是置信度,b是类别数量。
本发明的另一目的在于提供一种应用所述基于yolov3深度学习的混凝土裂缝识别方法的混凝土结构损伤检测控制系统。
综上所述,本发明的优点及积极效果为:本发明采用yolov3中的darknet-53网络作为特征提取器,将目标检测作为回归问题处理,基于一个单独的端到端神经网络模型直接进行目标区域定位及目标类别预测,使用了更深的网络进行多尺度预测,简化了网络训练的复杂性,降低了运算成本,快速实现目标检测的同时又获得了较高的准确率,更加适合工程应用环境。
深度学习目标检测一般有two-stage和one-stage模型,two-stage模型检测目标时需要生成一系列样本候选框,再由卷积神经网络进行样本分类,运算成本高,效率低下,而yolov3采用one-stage模型不用产生候选框,而是将定位目标边框的问题转化为回归问题处理,算法速度快,在与其他3种具有代表性的目标检测模型faster-rcnn、ssd、cnn+sd进行了比较后,本发明在检测速率和检测效果上均有明显优势,检测速度对比图见图8,检测效果对比图见图9,证明本发明比目前现有的深度学习模型更适用于裂缝识别领域;同时,本发明的实际检测对象包括了结构性裂缝和非结构性裂缝,见图11、图13,结构性裂缝的产生一般是由于结构应力达到限值,造成结构开裂引起的,是结构破坏的开始,而非结构性裂缝的产生一般是由于混凝土材料、浇筑、养护和使用环境等多种因素影响形成,其裂缝外观形式与结构性裂缝有很大不同。本发明对这两种裂缝均有较好的检测效果,解决了一般模型仅针对实验室内出现的结构裂缝进行检测的问题;相比于图像处理技术,本发明的yolov3模型通过单个神经网络模型直接进行目标区域定位及目标类别预测,有效降低了外部环境的干扰,提高了准确率。
附图说明
图1是本发明实施例提供的基于yolov3深度学习的混凝土裂缝识别方法流程图。
图2是本发明实施例提供的基于yolov3深度学习的混凝土裂缝识别方法实现流程图。
图3是本发明实施例提供的平均交并比与候选框数量之间的变化曲线示意图,候选框的数量增大,平均交并比随之增大,但增速逐渐降低。
图4是本发明实施例提供的实例中所取得候选框位置示意图。
图5是本发明实施例提供的yolov3在13×13单元格中预测边界框示意图。
图6是本发明实施例提供的学习率变化曲线示意图。
图7是本发明实施例提供的pr变化曲线示意图。
图8是本发明实施例提供的本发明与其他模型检测速度对比图。
图9是本发明实施例提供的本发明与其他模型检测效果对比图。
图10是本发明实施例提供的苏州吴江江陵大桥桥跨尺寸示意图。
图11是本发明实施例对江陵大桥结构性裂缝图像检测结果。
图12是本发明实施例中采用无人机获取图像的示意图。
图13是本发明实施例对江陵大桥非结构性裂缝图像检测结果。
图14是本发明实施例提供的基于yolov3深度学习的混凝土裂缝识别方法原理流程图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
针对目前常用的类似穷举式的深度学习方法,需要大量的数据,缺少针对性,运算成本高,且检测效率低的问题。本发明是一种具有很强的鲁棒性、很好的泛化能力以及较高的检测效率和准确率的裂缝检测技术,具有原创性,更适用于工程界。
下面结合附图对本发明的应用原理作详细的描述。
如图1所示,本发明实施例提供的基于yolov3深度学习的混凝土裂缝识别方法包括以下步骤:
s101:获取宽度约为0.05mm或以上的裂缝目标图像;将图像裁剪成统一大小,对图像中的目标手动添加矩形标签作为真实边界框,形成数据库;
s102:将目标图像导入yolov3,图像被自动压缩为416×416像素分辨率。采用类似fpn的上采样和特征融合方式,将原始图像按特征图的划分为s×s网格;
s103:确定anchor个数和宽高,从裂缝标注目标框的数据中学习特征,找到统计规律,再利用k均值聚类算法(k-means)对目标框作聚类分析,最终以k值为anchor的个数;以候选框与真实框的交并比(iou,用riou表示)作为评价标准,对图像训练集的所有裂缝目标标注框使用k-means聚类分析,以获得候选框的大小;
s104:对每一个网格使用3个anchorbox即先验框对目标边界进行预测,边界框信息为物体的中心位置相对于该点所在网格左上角的偏移量(tx,ty)及宽度tw和高度th。若目标中心在单元格中相对于图像左上角有偏移(cx,cy),并且候选框具有宽度pw和高度ph;
s105:对目标进行类别预测,yolov3对每个边界框通过逻辑回归来预测该框包含目标的概率。如果预测的边界框与真实的边界框大面积重合且比其他预测的边界框重合率高,其概率为1;如果重合率没有达到yolov3阈值0.5或大于阈值,但不是最大者,该预测边界框会被忽略,不会对损失函数造成影响;
s106:将预测得到的结果:高维特征向量、目标真实边界框及类别标签作为输入,设定学习率、学习率衰减速度、网络动量参数、权重衰减正则项、批次大小、批次大小划分和阈值等参数,训练对目标的边界框及类别进行精细回归的回归器模型。
下面结合附图对本发明的应用原理作进一步的描述。
如图2所示,本发明实施例提供的基于yolov3深度学习的混凝土裂缝识别方法包括以下步骤:
(1)获得数据库;
以人眼精度为准,获取宽度约为0.05mm或以上的裂缝目标图像,其中为保证训练出的模型具有更好的鲁棒性和稳定性,目标的发展方向、清晰度各有不同,目标所在的结构背景表面还存在污点、模板痕迹或水迹等等干扰。本实例中共计获取图像242张,将原始图像统一裁剪成1000×1000像素分辨率的较小图像,剔除非混凝土背景部分,使用lableimg对图像中的裂缝进行手动标注,以此作为总数据库,共计3821张图像。在数据库中随机生成训练集、验证集和测试集。
(2)对原始图像进行尺度分割;
将裂缝图像导入yolov3,图像被自动压缩为416×416像素分辨率。采用类似fpn的上采样和特征融合方式,将原始图像按特征图的尺度大小(13×13、26×26、52×52)划分为s×s网格。
(3)确定anchor个数和宽高;
利用k-means对裂缝真实边界框做聚类分析。由于yolov3的anchor个数和宽高维度是由voc20类数据集聚类得到,数据集中目标形态差距很大,与混凝土裂缝目标差异更大,需要对裂缝真实边界框做聚类分析,重新确定anchor个数和宽高。以候选框与真实框的交并比(iou,用riou表示)作为评价标准,对图像训练集的所有裂缝目标标注框使用k-means聚类分析,以获得候选框的大小。k-means聚类的距离函数为;
d(b,c)=1-riou(b,c);
式中b为矩形框的大小,c为矩形框的中心,riou(b,c)表示候选边界框与真实边界框的交并比。平均交并比与候选框数量之间的变化曲线如图3所示,可以看出随着候选框的数量增大,平均交并比的增速变的越来越缓慢。本实例在权衡平均交并比与候选框的数量之间的关系后,取9个候选框,分别为(33,46),(122,43),(50,148),(73,362),(144,155),(350,74),(153,381),(364,75),(322,365),每三个anchor对应三个尺度,如图4所示,其中小圆点为裂缝数据集标注框,大圆点表示裂缝数据集的聚类候选框,三角点为原yolov3的voc20数据集的候选框。
(4)进行边界框预测;
对每一个网格使用3个anchorbox即先验框对目标边界进行预测,预测实例见图5,在13×13单元格中预测边界框,其中灰色框为为聚类得到的先验框,白色框为真实框,深灰色框是对象中心点所在网格。
边界框信息为物体的中心位置相对于该点所在网格左上角的偏移量(tx,ty)及宽度tw和高度th。若目标中心在单元格中相对于图像左上角有偏移(cx,cy),并且候选框具有宽度pw和高度ph,则修正后的边界框为:
bx=σ(tx)+cx
by=σ(ty)+cy
(5)对目标进行类别预测;每个预测任务得到的特征大小都为:
s×s×[3×(4+l+b)];
式中s为网格大小,3为每个网格的先验框数量,4是边界框大小和坐标,1是置信度,b是类别数量。
yolov3对每个边界框通过逻辑回归预测该框包含目标的概率。如果预测的边界框与真实的边界框大面积重合且比其他预测的边界框重合率都要高,其概率为1;如果重合率没有达到yolov3阈值0.5或大于阈值,但不是最大,预测的这个边界框会被忽略,不会对损失函数造成影响。在训练过程中,yolov3对每一个物体仅分配一个预测框。
(6)训练模型
将预测得到的结果:高维特征向量、目标真实边界框及类别标签作为输入,设定学习率为0.001,学习率衰减速度为迭代到40000次时衰减10倍,迭代到45000次时再衰减10倍,变化曲线见图6;网络动量参数为0.9;权重衰减正则项为0.005;批次大小为64,批次大小划分为16;阈值为0.5,迭代次数为50200,训练对目标的边界框及类别进行精细回归的回归器模型。训练对目标边界框及类别进行精细回归的回归器模型。
训练完成后,用测试集的样本来验证yolov3模型的识别能力,ap值达89.4,pr曲线见图7,在与其他3种具有代表性的目标检测模型faster-rcnn、ssd、cnn+sd进行了比较后,本发明在检测速率和检测效果上均有明显优势,检测速度对比图见图8,检测效果对比图见图9。针对该实例问题,本发明在检测速度和检测效果方面都更为突出,其中检测速度可以达到实时检测的要求,证明本发明在混凝土结构损伤检测领域中的优势。
将本发明方法应用于苏州吴江江陵大桥裂缝检测识别中。该桥为三跨预应力混凝土连续箱梁刚构桥,配跨为50m+86m+50m=186m,见图10所示。桥梁运营15年后出现裂缝,采用无人机对运河上面的主跨底板进行裂缝图片采集,并进行了识别,结果显示:基于yolov3深度学习的混凝土裂缝检测模型能够对结构裂缝、非结构裂缝等多目标进行快速准确地识别,识别速度远快于其它模型,甚至达到了对混凝土裂缝目标进行实时检测的要求。这种目标检测模型对于混凝土裂缝的识别精度远优于其它模型,具有更强的鲁棒性和泛化能力。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!