一种可配置的模型计算分析自定义方法与流程
本发明属于大数据技术领域,尤其涉及一种可配置的模型计算分析自定义方法。
背景技术:
随着大数据相关技术、人工智能及数据科学的发展,机器学习模型越来越多的被应用于实际生产中。从机器学习模型建立、训练到实际生产应用的过程中,需要把以数学模型为基础的解决方案在各应用程序间共享。目前常用的数据流计算平台如spark、sklearn以及google开源的tensorflow等都有各自的模型共享办法。
spark的管道和模型都支持保存到文件中,可以在另外的spark上下文环境中加载使用,但这里的文件都是二进制的数据,仅spark自己可以加载,并且不可查看,只能在spark中载入模型后通过spark模型库方法输出查看。
sklearn是利用python的pickle机制将训练好的模型进行序列化并保存为文件,sklearn对pickle做了一下封装和优化,但这并不能解决pickle本身的一些限制,例如:版本兼容问题,自定义类无法序列化等扩展问题等。
tensorflow在模型训练包中提供了工具tf.train.saver来导出他的模型到元图(metagraph),tensorflow也利用了python的pickle机制来存储模型,并在这之外加入了额外的元数据。在模型加载的时候必须引入模型算法相关的程序包,否则模型无法成功加载,会导致模型中定义的一些属性会缺失。
当然,数据挖掘技术自20世纪下半叶发展到现在,也有不少办法可以实现数据挖掘模型的跨平台部署应用,随着计算机领域的人工智能取得了巨大进展,使数据挖掘进入机器学习阶段,这些方法同样适用,最常用的便是应用pmml实现机器学习模型的跨平台上线。
pmml全称预测模型标记语言(predictivemodelmarkuplanguage),是一种展现模型的标记语言,利用xml描述和存储数据挖掘模型,已经发展有近20年,并且是一个已经被w3c所接受的标准。预测分析模型和数据挖掘模型是指代数学模型的术语,这些模型采用统计技术了解大量历史数据中隐藏的模式。预测分析模型采用定型过程中获取的知识来预测新数据中是否有已知模式。pmml允许在不同的应用程序之间轻松共享预测分析模型。因此,可以在一个系统中定型一个模型,在pmml中对其进行表达,然后将其移动到另一个系统中,并在该系统中使用上述模型预测机器失效的可能性等。现在的大部分领先数据挖掘工具都可以导出或导入pmml。
如前所述,各大数据流计算平台在模型应用部署上都采用各自特有的技术,如此导致各平台训练所得模型并不能应用于其他平台,不具备通用性。另外,从各数据流计算平台模型部署的实现上可知其模型文件不易查看和编辑,并且在展现上不直观,然而实际生产应用中,存在为了更符合实际应用场景而对模型特定系统做适当调整,如此各平台模型文件不便于生产环境进行模型系统动态调整。
虽然pmml可以做到机器学习模型的跨平台部署,但正因为pmml为了满足跨平台,因此牺牲了很多平台独有的优化,各平台用各自算法库保存模型的api得到的模型文件,要比生成的pmml模型文件小很多。同时pmml文件加载速度也比算法库自己独有格式的模型文件加载慢很多。另外,pmml加载得到的模型和各平台算法库独有的模型相比,预测会存在一点点的偏差,虽然这个偏差并不大。再者,各平台对pmml的支持仅提供了对常用标准机器学习模型的实现,然而实际生产应用中并非都是使用标准机器学习模型,当前绝大多数应用场景由于数据难以获取或标准机器学习模型不适用等诸多原因,实际应用时还是使用自定义模型。虽然pmml提供了一定的扩展支持,但支持力度有限,难以适应种类繁多的实际生产场景,如特定的规则映射转换等。
技术实现要素:
本发明的目的是提供一种可配置的模型计算分析自定义方法,解决了数据预测分析应用中自定义模型描述配置及模型跨平台部署上线的技术问题。
为实现上述目的,本发明采用如下技术方案:
一种可配置的模型计算分析自定义方法,包括如下步骤:
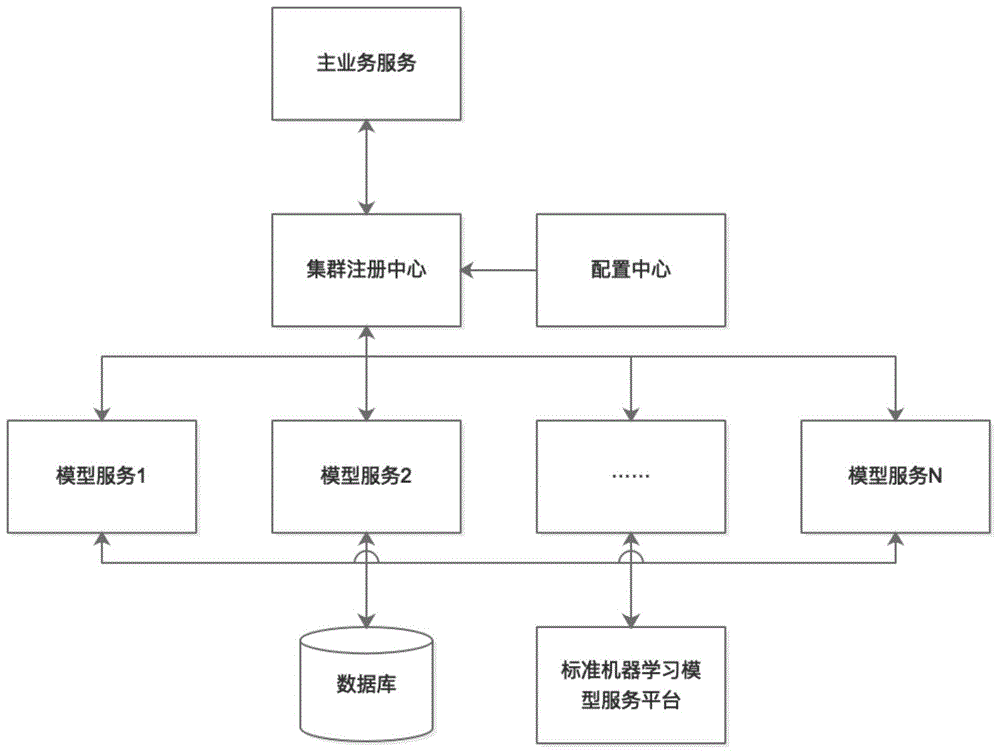
步骤1:构建集群服务注册中心、配置中心、模型服务器和数据库服务器,集群服务注册中心用于管理所有应用服务,应用服务包括业务服务和模型服务,各个应用服务之间的相互调用可通过集群服务注册中心发现调用目标服务;
配置中心用于配置集群服务注册中心中各个应用服务的应用配置;
模型服务器用于自定义模型计算分析,将模型配置持久化到数据库中,同时服务内部缓存模型配置序列化对象;
步骤2:在模型服务器中建立数个模型,通过模型描述元语言对模型进行描述;
模型描述元语言包括数据字典、转换方法、模型封装和归一化输出;
数据字典用于定义模型输入参数,包含1到多个数据字段,每个数据字段即为一个模型变量,数据字段的定义中包括参数名称、数据类型和是否必须等属性值,数据字段用于对模型输入参数的基本校验;
转换方法用于提供输入参数的转换预处理,包含0到多个转换配置,支持对单个参数的多次顺序转换,多次顺序转换通过设置顺序索引实现排序,每个转换配置均包含转换名称、待转换的参数名称和转换索引,转换名称即为转为的算法名称,用于提供字符串截取、阈值转换、映射转换和纯乘除转换;
模型封装为模型具体描述,用于模型计算,支持单个模型或多个模型组合,通过segmentation及其子标签segment对模型组合中的多个模型进行分段,每一个分段为一个子模型;
归一化输出用于描述模型输出转换处理,包含一个或多个输出字段,归一化输出包括输出字段名称、数据类型、原始字段名称和原始字段类型;归一化输出描述了模型计算过程中所有变量的转换输出,变量的转换输出包括模型输入参数、模型计算中间变量和模型计算结果;
步骤3:在集群服务注册中心对每一个业务服务进行注册,建立每一个业务服务的模型,通过配置中心对每一个模型进行模型配置管理,其步骤如下:
步骤a1:新增模型配置,其包括如下步骤:
步骤aa1:检查新增模型的本名称及类型是否满足自定义的预设要求:是,则执行步骤aa2;否,则舍弃新增模型;
步骤aa2:检查新增模型的模型配置文件内容是否可以序列化程序应用对象:是,则将新增模型的模型配置文件内容序列化程序应用对象,生成模型配置内容序列化对象,执行步骤aa3;否,则舍弃新增模型;
步骤aa3:根据新增模型的模型配置文件内容生成新增模型配置信息,根据新增模型配置信息判断是否为数据库服务器中的已有模型:是,则更新数据库服务器中的模型;否,则将新增模型配置信息持久化到数据库服务器中;
模型配置信息包含模型唯一标识id、模型名称、模型类型、模型描述、模型配置文件内容和模型状态;
模型类型包括标准模型和自定义模型;模型状态用于表示模型是否在用;
步骤aa4:在配置中心中设立模型服务缓存,将模型配置内容序列化对象存放于模型服务缓存中,用于模型调用;
步骤a2:模型配置删除操作采用的是逻辑删除,即将模型状态配置为不可用,并将该模型的模型配置内容序列化对象从模型服务缓存中清除;
步骤4:在集群服务注册中心为每一个模型建立一个模型服务,通过模型服务来加载模型,模型服务用于接收模型计算请求,在模型服务器中完成模型计算,其步骤如下:
步骤b1:模型服务提供一个模型调用rest接口,通过rest接口输入参与计算的参数,参与计算的参数包括模型唯一标识id和模型变量;
步骤b2:检查模型唯一标识id是否存在并且根据模型唯一标识id检查模型状态是否为可用:存在且可用,则执行步骤b3;反之则返回计算错误结果;
步骤b3:提取参与计算的参数,然后根据模型唯一标识id从模型服务缓存中载入模型配置内容序列化对象;
步骤b4:将模型变量传入模型配置内容序列化对象,执行模型运算;
步骤b5:获取步骤b4的计算结果,并输出计算结果。
优选的,所述字符串截取为配置开始位置和结束位置,对输入模型变量进行字符串截取处理;
所述提供阈值转换为对比模型变量,当在某个配置的阈值范围内时转换为特定的值;所述映射转换为将模型变量进行映射转换,由一个值到另一个值;
所述纯乘除转换为配置单个或多个乘法或除法因子对变量进行乘除转换。
优选的,所述模型封装用于单个或多个模型的分段组合实现,即支持子模型的概念,子模型支持规则模型和基础线性模型;规则模型包含规则配置和目标模型结果计算方法,即满足特定规则的情况下调用对应方法计算模型结果。
优选的,所述归一化输出为多个输出,用于输出模型计算中间变量和最终计算结果。
本发明所述的一种可配置的模型计算分析自定义方法,解决了数据预测分析应用中自定义模型描述配置及模型跨平台部署上线的技术问题,本发明模型配置描述清晰,便于线上动态调整模型,实时生效。并且便于扩展实现新增自定义模型,达到新模型快速上线,采用自定义模型描述元语言,可根据实际生产应用扩展元语言内容,提供更多实际生产应用场景支持,使模型描述配置保持和生产应用相同的复杂度,通常大多数实际生产应用模型更加简单,使得模型配置更简单,加载更快,且保持了模型训练和应用的计算一致性,同时也保留了跨平台的特性。
附图说明
图1是本发明的系统构架图;
图2是本发明的模型的执行流程图;
图3是本发明的模型配置新增模型流程图;
图4是本发明的模型计算请求执行流程图。
具体实施方式
如图1-图4所示的一种可配置的模型计算分析自定义方法,包括如下步骤:
步骤1:构建集群服务注册中心、配置中心、模型服务器和数据库服务器,集群服务注册中心用于管理所有应用服务,应用服务包括业务服务和模型服务,各个应用服务之间的相互调用可通过集群服务注册中心发现调用目标服务,实现负载均衡等,同时所有服务,包括注册中心服务都支持多实例部署,避免服务单点故障。
配置中心用于配置集群服务注册中心中各个应用服务的应用配置;配置中心实现服务配置和服务运行实例的分离,通过集群注册中心可以实现单个服务下线,更新配置,再上线服务,达到配置灰度发布。
模型服务器用于自定义模型计算分析,将模型配置持久化到数据库中,同时服务内部缓存模型配置序列化对象;另外,模型服务支持扩展调用外部标准机器学习模型服务,针对标准机器学习模型,模型配置支持提取机器学习模型关键系数作为配置项,可提供和自定义模型一样实现实时动态调整模型系统(标准机器学习模型服务平台再加载模型后根据配置重新调整模型系数)。
步骤2:在模型服务器中建立数个模型,通过模型描述元语言对模型进行描述;
模型描述元语言包括数据字典、转换方法、模型封装和归一化输出;
数据字典用于定义模型输入参数,包含1到多个数据字段,每个数据字段即为一个模型变量,数据字段的定义中包括参数名称、数据类型和是否必须等属性值,数据字段用于对模型输入参数的基本校验;数据字典用于表示字段类型和是否必须检查
转换方法用于提供输入参数的转换预处理,包含0到多个转换配置,支持对单个参数的多次顺序转换,多次顺序转换通过设置顺序索引实现排序,每个转换配置均包含转换名称、待转换的参数名称和转换索引,转换名称即为转为的算法名称,用于提供字符串截取、阈值转换、映射转换和纯乘除转换;
模型封装为模型具体描述,用于模型计算,支持单个模型或多个模型组合,通过segmentation及其子标签segment对模型组合中的多个模型进行分段,每一个分段为一个子模型;
设置属性标识多个模型的组合方式,如链式、全选、权重等。链式即多个模型顺序执行,取最后一个模型结果为整体结果,segment的id属性值表示执行顺序;全选即选全部子模型结果;权重即按子模型结果进行加权得到最终结果。本实施例中每段的子模型支持两种模型大类,基础线性模型和规则模型,且每种大类下又有许多具体的模型实现。
归一化输出用于描述模型输出转换处理,包含一个或多个输出字段,归一化输出包括输出字段名称、数据类型、原始字段名称和原始字段类型;归一化输出描述了模型计算过程中所有变量的转换输出,变量的转换输出包括模型输入参数、模型计算中间变量和模型计算结果;pmml中并不支持入参和中间变量的输出,本发明很好的解决了这个问题,更符合实际生产应用。
本发明中模型描述元语言的定义采用和pmml相同的实现方式,通过xmlschema(可扩展标记语言模式定义)来描述和定义用于描述模型的xml文档结构。采用这种方式的目的在于兼容标准机器学习模型的pmml定义实现,但更加轻量化,提供更多扩展性。另外大多应用程序开发平台都提供了xsd(xml模式定义)到应用程序代码实现的转化,如java中通过一些工具或者maven插件maven-jaxb2-plugin将xsd中定义的内容生成成具体的实体类,以便在实现算法时使用。
步骤3:在集群服务注册中心对每一个业务服务进行注册,建立每一个业务服务的模型,通过配置中心对每一个模型进行模型配置管理,其步骤如下:
步骤a1:新增模型配置,其包括如下步骤:
步骤aa1:检查新增模型的本名称及类型是否满足自定义的预设要求:是,则执行步骤aa2;否,则舍弃新增模型;
步骤aa2:检查新增模型的模型配置文件内容是否可以序列化程序应用对象:是,则将新增模型的模型配置文件内容序列化程序应用对象,生成模型配置内容序列化对象,执行步骤aa3;否,则舍弃新增模型;
步骤aa3:根据新增模型的模型配置文件内容生成新增模型配置信息,根据新增模型配置信息判断是否为数据库服务器中的已有模型:是,则更新数据库服务器中的模型;否,则将新增模型配置信息持久化到数据库服务器中;
模型配置信息包含模型唯一标识id、模型名称、模型类型、模型描述、模型配置文件内容和模型状态;
模型类型包括标准模型和自定义模型;模型状态用于表示模型是否在用;
步骤aa4:在配置中心中设立模型服务缓存,将模型配置内容序列化对象存放于模型服务缓存中,用于模型调用;
步骤a2:模型配置删除操作采用的是逻辑删除,即将模型状态配置为不可用,并将该模型的模型配置内容序列化对象从模型服务缓存中清除;
模型主要包含两大功能,模型配置管理和模型运算。模型配置管理实现添加模型配置、修改模型配置及删除无用模型。模型服务使用mysql数据库实现模型配置持久化。
步骤4:在集群服务注册中心为每一个模型建立一个模型服务,通过模型服务来加载模型,模型服务用于接收模型计算请求,在模型服务器中完成模型计算,其步骤如下:
步骤b1:模型服务提供一个模型调用rest接口,通过rest接口输入参与计算的参数,参与计算的参数包括模型唯一标识id和模型变量;
步骤b2:检查模型唯一标识id是否存在并且根据模型唯一标识id检查模型状态是否为可用:存在且可用,则执行步骤b3;反之则返回计算错误结果;
步骤b3:提取参与计算的参数,然后根据模型唯一标识id从模型服务缓存中载入模型配置内容序列化对象;
步骤b4:将模型变量传入模型配置内容序列化对象,执行模型运算;
步骤b5:获取步骤b4的计算结果,并输出计算结果。
输出结果返回给调用方。
优选的,所述字符串截取为配置开始位置和结束位置,对输入模型变量进行字符串截取处理;
所述提供阈值转换为对比模型变量,当在某个配置的阈值范围内时转换为特定的值;所述映射转换为将模型变量进行映射转换,由一个值到另一个值;
所述纯乘除转换为配置单个或多个乘法或除法因子对变量进行乘除转换。
优选的,所述模型封装用于单个或多个模型的分段组合实现,即支持子模型的概念,子模型支持规则模型和基础线性模型;规则模型包含规则配置和目标模型结果计算方法,即满足特定规则的情况下调用对应方法计算模型结果。
优选的,所述归一化输出为多个输出,用于输出模型计算中间变量和最终计算结果。
本发明提供独立的配置中心分离服务和配置,支持服务配置的灰度发布,动态更新模型配置可通过配置中心通知特定节点或全部节点重新载入模型配置。
本发明所述的一种可配置的模型计算分析自定义方法,解决了数据预测分析应用中自定义模型描述配置及模型跨平台部署上线的技术问题,本发明模型配置描述清晰,便于线上动态调整模型,实时生效。并且便于扩展实现新增自定义模型,达到新模型快速上线,采用自定义模型描述元语言,可根据实际生产应用扩展元语言内容,提供更多实际生产应用场景支持,使模型描述配置保持和生产应用相同的复杂度,通常大多数实际生产应用模型更加简单,使得模型配置更简单,加载更快,且保持了模型训练和应用的计算一致性,同时也保留了跨平台的特性。
- 还没有人留言评论。精彩留言会获得点赞!