基于事件检测的微博网络情感社区识别方法与流程
本发明涉及微博事件检测技术领域,是一种基于事件检测的微博网络情感社区识别方法。
背景技术:
社交网络是指由节点和链接组成的复杂结构,其中,节点表示个人或组织,链接表示节点和节点之间的关系,例如:朋友关系,亲戚关系,同事关系以及科研领域的合作关系等。从不同的结构粒度来看,社交网络分析方法大致可分为三类:宏观层面,研究社交网络的相关指标及模型;微观层面,研究社交网络的个体影响力及传播动力学原理;中观层面,研究社交个体的群聚特征,其中最具代表性的就是社区结构。所谓社区,是指网络中的密集群体,同一社区内的节点间的链接相对紧密,不同社区之间的节点的链接相对稀疏。通常,社区内的节点具有相似的兴趣爱好或其他属性,在网络中起同步效应。社区发现可以识别网络中的功能模块,有助于人们更加深入的理解网络的本质。
社区识别研究根据所用方法的不同,大致可分为五类:(1)层次聚类分析方法。这类方法通过计算网络中节点之间的相似度,合并相似度高的节点为同一社区。聚类过程以树的形式展示,通过模块度函数衡量划分结果,从而获得最优的社区;(2)矩阵谱分析方法。通过对网络的邻接矩阵施以谱分析等矩阵计算方法来发现社区;(3)基于链接的分析方法,以网络中的链接为基本单位进行社区识别;(4)基于图论的方法。运用极大团、极大连通子图等识别社区;(5)语义社区识别方法。通过对社交网络用户发表文本信息加以分析,将具有主题相似性的用户聚合成同一社区。
现有方法存在的问题在于:只考虑了社交网络的结构特性及文本相似性,忽略了网络用户的情感倾向性。社交网络发展至今,微博等社交媒体早已融入人们的日常生活和工作当中,在微博网络上,人们喜欢对微博上获取的消息加以评论,发表自己的观点与见解,并对社会事件表达情感倾向。因此,合理的社区结构应该对某类社会事件具有相近的社会认知。而现有方法以链接关系、链接程度以及主题相似性等指标作为社区的生成标准会增加社区的分裂风险,社区稳定性略显不足。
技术实现要素:
本发明为解决目前社区识别算法无法刻画用户的情感倾向性,导致输出的社区结果内聚性较低、稳定性不足,在网络演化过程中容易引发社区分裂这一问题,本发明提供了一种基于事件检测的微博网络情感社区识别方法,本发明提供了以下技术方案:
一种基于事件检测的微博网络情感社区识别方法,包括如下步骤:
步骤一:基于python爬虫爬取微博网络用语的数据,对微博网络数据进行初始化;
步骤二:提取微博网络中的社会热点事件,构造事件热点评估函数;
步骤三:度量微博用户对社会热点事件的情感极性,生成微博用户对多个社会热点事件的情感极性标签;
步骤四:初始化微博用户的情感极性标签,构造社区标签更新迭代规则,直至标签收敛时终止循环,将具有相同标签的节点划分到同一社区。
优选地,所述步骤一具体为:
第一步:采用python爬虫向上广度优先搜索策略,爬取微博社交网络用户的用语数据,通过下式表示所述微博网络用语数据:
di={li,fi,ri,ci,ti}(1)
其中,di为微博帖子i的网络用语数据,li为微博帖子i的文本,fi为微博帖子i的发帖者的粉丝数量,ri为微博帖子i的转发次数,ci为微博帖子i的评论次数,ti为微博帖子i的发布时间,i表示为微博帖子;
第二步:初始化微博网络用语数据,并将所述初始化的数据存于mysql数据库。
优选地,所述步骤二具体为:
第一步:采用tf-idf方法计算词汇η在微博网络用语数据中的权重,通过下式计算词汇n的权重:
其中,
第二步:以词汇η的权重为基础,构造度量微博帖子间相关程度的余弦相似表达式
c={c1,c2,...,ck}(3)
其中,c为迭代生成的事件集合,ck为第k个微博事件,
第三步:构造社会热点事件评估函数δhot,筛选处关注度高的m个社会热点事件,通过下式表示δhot:
其中,δhot为社会热点事件评估函数,nc为事件集合c中的帖子总数;
第四步:对筛选处的m个社会热点事件进行排序,得到m个社会热点事件集合,通过下式表示m个社会热点事件集合:
cim={c1,c2,...,cm}(6)
其中,cim为m个社会热点事件集合,cm为第m个社会热点事件。
优选地,通过δhot统计粉丝的有效回应,所述δhot取值范围为[0,1]。
优选地,所述步骤三具体为:
第一步:利用ictclas分词系统对微博网络用语数据进行分词;
第二步:基于hownet情感词典完成词语级情感极性分析,对未出现在情感词典中的网络词汇ηnew,建立词语级相似性度量函数,通过函数判断ηnew与hownet情感词典已有的词汇ηhow相似程度,通过下式表示词语级相似性度量函数:
其中,s(ηnew,ηhow)为词语级相似性度量函数,|ηnew|以及|ηhow|分别为词汇ηnew以及ηhow在爬取数据时出现次数;
第三步:计算用户u对m个社会热点事件发表言论的情感极性,生成微博用户u对m个社会热点事件的情感极性标签,通过下式表示所述情感极性标签:
其中,u为微博用户u对m个社会热点事件的情感极性标签,
优选地,所述步骤四具体为:
第一步:初始化微博用户对社会热点事件的情感极性标签,每个微博用户包含一个特征向量,通过下式表示特征向量:
vecu=(lu,bu)(9)
其中,vecu为微博用户u的特征向量,lu为微博用户u的社区标签集合,bu为微博用户u对社区的归属程度;
初始化所述征向量时,得到vecu=(u,1),归属程度为1;
第二步:微博用户向邻居用户传递一次特征向量,构造社区标签更新迭代规则,所述规则具体为:当微博用户收到邻居用户传来的特征向量时,微博用户将收到的特征进行更改,通过下式进行更改:
其中,τ(u)为微博用户u的邻居集合,v为微博用户u的邻居用户,vecv∈τ(u)为所述邻居用户v的特征向量,lv为邻居用户v的社区标签集合,b′v为邻居用户v对社区的归属程度;u和v分别代表微博用户u以及邻居用户v的情感极性标签集合,mic(u,v)为微博用户u与邻居用户v之间情感极性标签的最大互信息系数,
通过下式计算mic(u,v):
其中,i[u;v]为u和v之间的互信息;
当对微博用户u的任意一邻居x,x∈τ(u),以及所有收到的任意特征向量vec′x∈τ(u)=(lx,b′x),lx为任意一邻居x的社区标签集合,b′x为任意一邻居x对社区的归属程度,选择b′x最大的邻居所持有的社区标签作为基准社区标签,则用户u加入基准社区标签所代表的社区;
当对于基准社区标签之外的社区标签ly时,y∈τ(u),满足y归属程度不是最大的,当y的邻居同时包括y自身对ly的隶属度的为最大值时,所述隶属度的最大值再加上除ly的隶属度最大值外的隶属度之和再与u的邻居数的作商;当所述作商的结果大于b′x,则将u加入y所在社区;
第三步:重复第二步,当社区标签收敛时,终止循环,将具有相同社区标签的用户划分到同一个社区。
本发明具有以下有益效果:
本发明利用文本分析技术,构造了社交网络重大社会事件提取方法,实现了基于事件的微博用户情感倾向性分析,保证了输出的社区结果具有较高的内聚性及稳定性,对网络演化产生的网络结构及属性改变具有较高的适应性。
附图说明
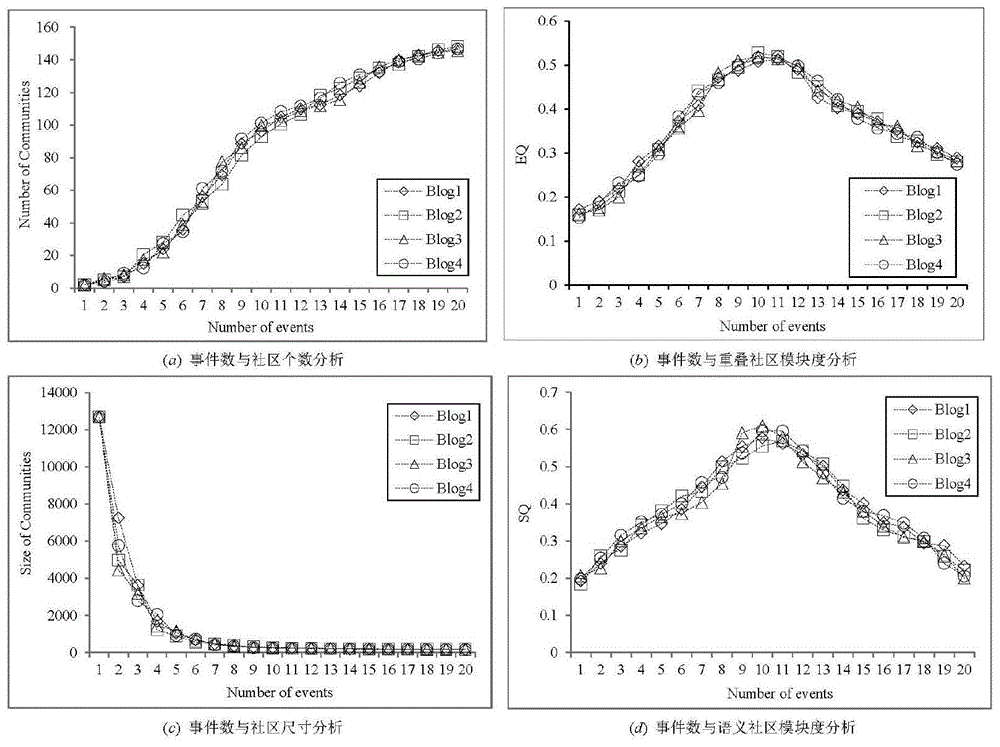
图1是重大社会事件选取分析图,图1-a为事件数与社区个数分析图,图1-b为时间书与重叠社区模块度分析图,图1-c为事件数与社区尺度分析图,图1-d为事件数与语义社区模块度分析图。
图2是短文本极性分析规则例图。
图3是社区标签更新实施例图。
图4是football网络的社区划分结果图,图4-a为gn划分结果图,图4-b为lfm划分结果图,图4-c为copra划分结果图,图4-d为ecm划分结果图。
图5为重叠社区模块度比对分析图。
图6为语义社区模块度比对分析图。
具体实施方式
以下结合具体实施例,对本发明进行了详细说明。
具体实施例一:
一种基于事件检测的微博网络情感社区识别方法,包括如下步骤:
步骤一:基于python爬虫爬取微博网络用语的数据,对微博网络数据进行初始化;
步骤二:提取微博网络中的社会热点事件,构造事件热点评估函数;
步骤三:度量微博用户对社会热点事件的情感极性,生成微博用户对多个社会热点事件的情感极性标签;
步骤四:初始化微博用户的情感极性标签,构造社区标签更新迭代规则,直至标签收敛时终止循环,将具有相同标签的节点划分到同一社区。
步骤1:数据初始化。
利用python编写的爬虫程序采用向上广度优先搜索策略,爬取微博数据并将结果存于mysql数据库。微博帖子i的数据可表示为di={li,fi,ri,ci,ti},其中l表示帖子i的文本内容、f表示帖子i的发帖者的粉丝数量、r表示帖子i的转发次数、c表示帖子i的评论次数、t表示帖子i的发布时间。
步骤2:提取微博网络中的top-m个重大社会事件。
1)利用tf-idf方法计算词汇η在微博帖子di中的权重
公式(1)中
2)以
公式(2)中
3)构造事件热点评估函数δhot,筛选热度较高的top-m个热点事件(m<k,m的取值可以参照本发明的实施例)。δhot定义为:
根据公式(3)所得结果进行排序,可得m个重大社会事件集合cim={c1,c2,...,cm}。公式(3)中nc为事件集合c中的帖子总数,δhot统计了粉丝的“有效回应”,取值范围为[0,1]。
步骤3:度量微博用户对重大社会事件的情感极性,生成微博用户u对m个重大社会事件c1,c2,...,cm的情感极性标签
1)利用中国科学院ictclas分词系统对微博数据进行分词。
2)基于hownet情感词典完成词语级情感极性分析。对未出现在情感词典中的网络词汇ηnew判定ηnew与hownet词典已有情感词ηhow之间的相似程度。将网络词汇ηnew的情感极性定义为与ηnew相似程度最高的hownet情感词的情感极性。词语级相似性度量函数s(ηnew,ηhow)定义为:
公式(4)中|ηnew|以及|ηhow|分别代表网络词汇ηnew以及hownet情感词汇ηhow在爬取数据中的出现次数。
3)如图2所示,定义短文本级情感极性分析规则:
规则1:对短文本中出现的所有词汇,定义积极词汇初始评分为+1,消极词汇初始评分为-1,中性词汇初始评分为0
规则2:当词汇的前置词汇为程度词汇时,词汇的评分等于词汇的初始评分乘以前置程度词汇在hownet词典中的程度评分,该评分取值范围为(0,1)。
规则3:当词汇(包括程度词汇)的前置词汇为否定词汇时,词汇评分乘以-1。
短文本最终的情感极性为所有词汇评分之和。
4)利用短文本情感极性分析规则,计算用户u对m个重大事件c1,c2,...,cm发表言论的情感极性,生成微博用户u对m个重大社会事件c1,c2,...,cm的情感极性标签
步骤4:识别情感社区集合。
1)初始化微博用户u对m个重大社会事件的情感极性标签
2)初始化社区标签。微博中的每个用户u包含一个初始特征向量vecu=(lu,bu),lu代表用户u的社区标签集合,bu代表用户u对所述社区的归属程度。初始化时,vecu=(u,1),代表用户u的初始社区为自身,且归属程度为1。
3)构造社区标签更新规则:定义与u直接相连的用户集合为用户u的邻居集合τ(u)。算法开始后,所有用户向自己所有的邻居用户传递一次特征向量。当用户u收到邻居用户v∈τ(u)传来的特征向量vecv∈τ(u)=(lv,bv)时,执行以下规则。
规则1:u将收到的特征向量更改为vec′v∈τ(u)=(lv,b′v),
u和v分别代表用户u以及用户v的情感极性标签集合,mic(u,v)为用户u与用户v之间情感极性标签的最大互信息系数,具体为:
i[u;v]为u和v之间的互信息。
规则2:对于用户u的任一邻居x∈τ(u),以及所有收到的特征向量vec′x∈τ(u)=(lx,b′x),选择b′x最大的邻居x所持有的社区标签lx作为基准社区标签,用户u必然加入基准社区标签所代表的社区。
规则3:对于基准社区标签之外的其他社区标签ly,y∈τ(u),y≠x,如果“所有持有ly社区标签的邻居(包括y自身)对ly的隶属度的最大值”,加上“对ly的其他隶属度之和与u的邻居数的商”,结果大于b′x,则u加入y所在社区。
4)构造标签迭代终止规则:重复上一步骤,当社区标签收敛时终止循环。将具有相同社区标签的用户划分到同一社区,其中持有多个社区标签的节点为社区的重叠节点。
具体实施例二:
1)数据初始化实施例。爬取2017年10月-2018年9月共12个月用户所发的微博帖子,随机选取网络节点作为初始爬取节点,采用自底向上的方法爬取初始节点的邻居结构。过滤掉微博数少于50的用户以及关注数/被关注数少于5的用户并以3个月为时间间隔对所得数据进行了分割,用blog1、blog2、blog3、blog4加以标识,具体如表1所示。
表1微博数据描述
2)top-m重大社会事件提取实施例。
附图1给出了top-m中m的确定分析,对于blog1~blog4而言,m的取值在8~12之间时算法被认为具有较高的识别性能。提取出的重大事件如表2所示。
表22017年10月-2018年9月期间微博网络重大社会事件摘要
3)附图2给出了短文本极性分析规则的实施例图,用于分析用户的情感倾向性。
规则1:对短文本中出现的所有词汇,定义积极词汇初始评分为+1,消极词汇初始评分为-1,中性词汇初始评分为0
规则2:当词汇的前置词汇为程度词汇时,词汇的评分等于词汇的初始评分乘以前置程度词汇在hownet词典中的程度评分,该评分取值范围为(0,1)。
规则3:当词汇(包括程度词汇)的前置词汇为否定词汇时,词汇评分乘以-1。
短文本最终的情感极性为所有词汇评分之和。
4)情感社区集合识别实施例。
附图3给出了社区识别时标签更新实施例,用户u邻接a,b,c三个社区,假设社区内节点对社区的隶属度以及与u的mic值,已知(分别为括弧内向量以及边上权重),则受到的特征向量为:(a,0.70)、(b,0.65)、(b,0.45)、(c,0.50)、(c,0.40)、(c,0.50)。此处基准社区标签为(a,0.70),对社区a、b、c的隶属度更新为:(a,0.70)、(b,0.65+0.45/6)=(b,0.725),(c,0.5+(0.4+0.5)/6)=(c,0.65),因此用户u加入社区a和社区b。
为了使社区识别结果更加清晰,在附图4(a)~(d)中分别给出了标签传播类社区识别方法gn、lfm、copra以及本发明ecm方法在football网络上的划分结果。
选取语义社区识别方法cut、cart、lcta、turcm以及s-lpa作为比对方法,用重叠社区模块度函数eq以及语义社区模块度函数sq度量社区的稳定性以及凝聚力。除微博数据外,选取enron邮件网络、dblp引文网络、arxiv高能物理引文网络(cnd)以及清华大学qlsp数据集作为验证数据。验证结果在附图5(eq)以及附图6(sq)给出,可以看出本发明方法ecm在性能上确实有所提高,具有比较好的效果。
以上所述仅是基于事件检测的微博网络情感社区识别方法的优选实施方式,基于事件检测的微博网络情感社区识别方法的保护范围并不仅局限于上述实施例,凡属于该思路下的技术方案均属于本发明的保护范围。应当指出,对于本领域的技术人员来说,在不脱离本发明原理前提下的若干改进和变化,这些改进和变化也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!