一种基于机器学习的智能Web代理缓存系统及方法与流程
本发明涉及人工智能技术领域,特别涉及一种基于机器学习的智能web代理缓存系统及方法。
背景技术:
web缓存游走于服务器和客户端之间。这个服务器可能是源服务器(资源所驻留的服务器add),数量可能是1个或多个;这个客户端也可能是1个或多个。web缓存就在服务器-客户端之间搞监控,监控请求,并且把请求输出的内容(例如html页面、图片和文件)(统称为副本)另存一份;然后,如果下一个请求是相同的url,则直接请求保存的副本,而不是再次麻烦源服务器。
通常情况下,使用web缓存有2个主要原因:
一是降低延迟:缓存离客户端更近,因此,从缓存请求内容比从源服务器所用时间更少,呈现速度更快,网站就显得更灵敏。
二是降低网络传输:副本被重复使用,大大降低了用户的带宽使用,若是在流量付费的前提下其实也是一种变相的省钱,同时保证了带宽请求在一个低水平上,使得网络传输更容易维护。
余信达于北京邮电大学发表的硕士学位论文《基于代理服务器的web智能缓存系统研究与设计》中,在原有web端缓存系统的基础之上,对原本的代理缓存服务器缓存管理、替换、预取等策略进行深入研究和分析,由此引入了基于区域热点扩散的新缓存管理算法,同时在单点缓存代理中针对两种情况分别对缓存空间设计了缓存空间节约算法,实现了细粒度文件级的缓存节约策略。然后从基于区域“热点”发现的预取模式方面进行深入挖掘研究。最后,设计实现了新型的web智能缓存系统。
该论文虽然在缓存管理、替换、预取等方面有所创新,但是对cpu的占用率依然很高,没有有效结合实际情况下内存和cpu的可用性和利用率问题。
为了解决cpu的占用率高的问题,本发明设计了一种基于机器学习的智能web代理缓存系统及方法。
技术实现要素:
本发明为了弥补现有技术的缺陷,提供了一种简单高效的基于机器学习的智能web代理缓存系统及方法。
本发明是通过如下技术方案实现的:
一种基于机器学习的智能web代理缓存系统及方法,其特征在于:包括监控组件,预处理组件,离线训练组件,缓存分类器,页面爬虫组件,在线交互组件和插件生成组件七部分;
其中,监控组件负责利用jmeter对用户电脑内存和cpu进行监控,形成用户内存使用率和cpu占用率的趋势图;
所述在线交互组件负责缓存,与用户进行直接交互,得到用户访问的原始数据;
所述预处理组件负对将用户访问的原始数据进行缓存分类,自然语言处理nlp分词和分词过滤;
所述离线训练组件则负责在cpu较为空闲,内存占用较少的时候工作,对已有缓存内容进行处理,不断学习和训练优化,从而不断调整缓存分类器;
所述缓存分类器根据离线训练组件经多次训练和学习得到的相关参数进行设置,并将其分类;
所述页面爬虫组件负责将对应关键字的一些网页爬取出来,按照时间排序,将最新的500条网页记录保存于缓存中;
所述插件生成组件负责整合和封装监控组件,预处理组件,离线训练组件,缓存分类器,页面爬虫组件和在线交互组件的内容,并且经过浏览器兼容性处理,形成通用的浏览器插件。
本发明基于机器学习的智能web代理缓存系统的缓存方法,在智能web缓存机制下,结合web访问过程中数据吞吐量大的特点,针对每个用户的客户端硬件实际情况,合理利用cpu和内存,在web缓存过程中利用闲置cpu资源,采用基于机器学习的方法对已缓存内容进行训练和学习,为web用户提前保存对应领域的内容到缓存中,实现在访问过程中一次请求就能读到缓存的高效性和便捷性。
本发明基于机器学习的智能web代理缓存系统的缓存方法,结合每个用户不同的计算机资源,合理分配,将一部分闲置资源用于预缓存处理;在用户已有缓存内容的条件下,利用机器学习算法对缓存内容进行训练,不断优化学习模型,达到智能化,并提前缓存与用户偏好相关的内容;在缓存内容和用户点击浏览内容不断丰富的情况下,利用闲置cpu和内存,对缓存模型进行调整,从而使预缓存更加贴合用户实际需求。
本发明基于机器学习的智能web代理缓存系统的缓存方法,包括以下步骤:
第一步,插件生成组件将监控组件,预处理组件,离线训练组件,缓存分类器,页面爬虫组件和在线交互组件进行整合和封装,经过浏览器兼容性处理,形成通用的浏览器插件;
第二步,监控组件利用jmeter自动对用户电脑内存和cpu进行监控,形成用户内存使用率和cpu占用率的趋势图;
第三步,在线交互组件与用户进行直接交互,得到户访问的原始数据,即浏览器文本,离线训练组件处于待工作状态;当用户电脑内存和cpu使用率低时,触发缓存预处理组件和离线训练组件;
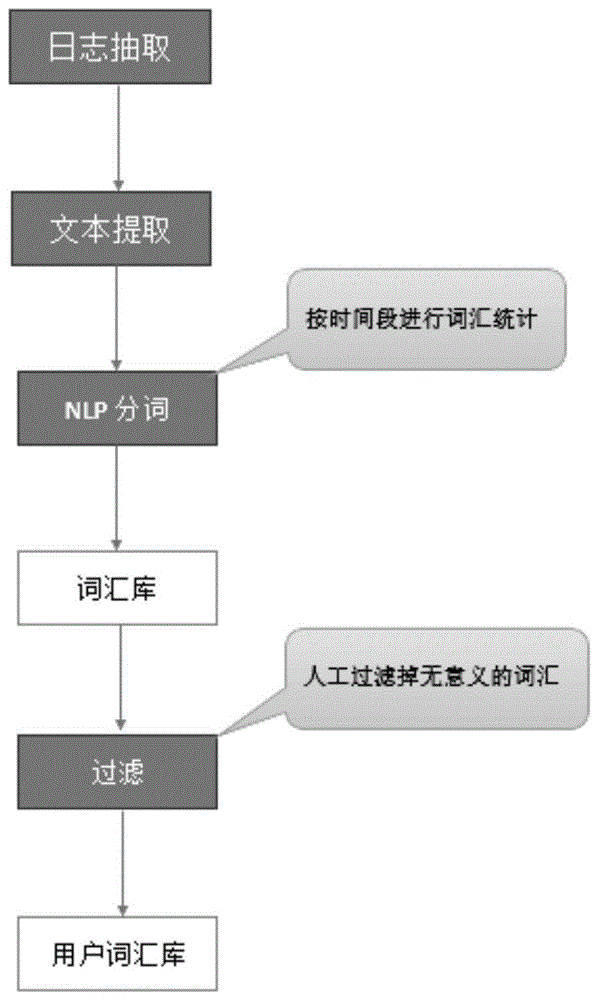
第四步,预处理组件将浏览器文本进行缓存分类,并针对每个类别的文件进行自然语言处理nlp分词,保存于分词库中,针对一段时间内分词库中的数据进行分词过滤,以减少数据的噪声;
第五步,离线训练组件在用户计算机资源空闲时,将过滤后的词汇库数据作为学习数据集参与预缓存训练;
第六步,离线训练组件经过不断地训练和学习,将相关参数设置于缓存分类器中,缓存分类器给出分类结果,所述分类结果为用户在某一时间段偏好浏览的内容关键字;
第七步,得到用户某一时间段偏好浏览的内容关键字后,页面爬虫组件预先将对应关键字的网页爬取出来并保存于缓存中,供用户在访问对应资源时,第一次访问便可以读到缓存内容。
所述第二步中,当内存使用率小于四分之一时,在趋势图上以标志a标明,5分钟标注一次;当cpu占用率小于四分之一时,在趋势图上以标志b标明,5分钟标注一次;离线训练组件不直接参与web用户的交互,当监控趋势图中a标志和b标志在1个小时内同时出现时,触发缓存预处理组件和离线训练组件。
所述第四步中,预处理组件将浏览器文本缓存文件进行处理,根据时间段(0:00-6:00、6:00-12:00、12:00-18:00、18:00-24:00),将文件分成四大类,类别编号分别为1、2、3、4;针对每个类别的文件,提取文件文本,利用自然语言处理nlp,进行文本词汇的抽取和分词,形成“词汇—类别号”的键值对关系,保存于分词库中;针对一段时间内(一天或者一周)分词库中的数据,人工操作分析出现较多并且不能反映用户偏好的词汇(如:“搜索”、“确认”等),将其删除和过滤,以减少数据的噪声。
所述第五步中,过滤后的词汇库数据中,80%作为机器学习的训练集,20%作为验证集;如果当前用户缓存内容较少,则进行多次分拆,实现交叉训练和验证。
所述第七步中,缓存分类器给出用户某一时间段偏好浏览的内容关键字后,页面爬虫组件在对应时间段的前一时间段,将对应关键字的一些网页爬取出来,按照时间排序,将最新的500条网页记录保存于缓存中。
所述第七步中,当缓存内容达到一定阈值(如:5g)时,开始激发一次离线训练组件,离线训练组件处于待工作状态;当计算机的内存和cpu空闲时,离线训练组件开始工作。
本发明的有益效果是:该基于机器学习的智能web代理缓存系统及方法,利用闲置cpu资源,采用基于机器学习的方法对已缓存内容进行训练和学习,为web用户提前保存对应领域的内容到缓存中,实现了用户访问的高效性和便捷性。
附图说明
附图1为本发明预处理流程示意图。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚明白,以下结合实施例,对本发明进行详细的说明。应当说明的是,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
该基于机器学习的智能web代理缓存系统,包括监控组件,预处理组件,离线训练组件,缓存分类器,页面爬虫组件,在线交互组件和插件生成组件七部分;
其中,监控组件负责利用jmeter对用户电脑内存和cpu进行监控,形成用户内存使用率和cpu占用率的趋势图;
所述在线交互组件负责缓存,与用户进行直接交互,得到用户访问的原始数据;
所述预处理组件负对将用户访问的原始数据进行缓存分类,自然语言处理nlp分词和分词过滤;
所述离线训练组件则负责在cpu较为空闲,内存占用较少的时候工作,对已有缓存内容进行处理,不断学习和训练优化,从而不断调整缓存分类器;
所述缓存分类器根据离线训练组件经多次训练和学习得到的相关参数进行设置,并将其分类;
所述页面爬虫组件负责将对应关键字的一些网页爬取出来,按照时间排序,将最新的500条网页记录保存于缓存中;
所述插件生成组件负责整合和封装监控组件,预处理组件,离线训练组件,缓存分类器,页面爬虫组件和在线交互组件的内容,并且经过浏览器兼容性处理,形成通用的浏览器插件。
该基于机器学习的智能web代理缓存系统的缓存方法,在智能web缓存机制下,结合web访问过程中数据吞吐量大的特点,针对每个用户的客户端硬件实际情况,合理利用cpu和内存,在web缓存过程中利用闲置cpu资源,采用基于机器学习的方法对已缓存内容进行训练和学习,为web用户提前保存对应领域的内容到缓存中,实现在访问过程中一次请求就能读到缓存的高效性和便捷性。
该基于机器学习的智能web代理缓存系统的缓存方法,结合每个用户不同的计算机资源,合理分配,将一部分闲置资源用于预缓存处理;在用户已有缓存内容的条件下,利用机器学习算法对缓存内容进行训练,不断优化学习模型,达到智能化,并提前缓存与用户偏好相关的内容;在缓存内容和用户点击浏览内容不断丰富的情况下,利用闲置cpu和内存,对缓存模型进行调整,从而使预缓存更加贴合用户实际需求。
该基于机器学习的智能web代理缓存系统的缓存方法,包括以下步骤:
第一步,插件生成组件将监控组件,预处理组件,离线训练组件,缓存分类器,页面爬虫组件和在线交互组件进行整合和封装,经过浏览器兼容性处理,形成通用的浏览器插件;
第二步,监控组件利用jmeter自动对用户电脑内存和cpu进行监控,形成用户内存使用率和cpu占用率的趋势图;
第三步,在线交互组件与用户进行直接交互,得到户访问的原始数据,即浏览器文本,离线训练组件处于待工作状态;当用户电脑内存和cpu使用率低时,触发缓存预处理组件和离线训练组件;
第四步,预处理组件将浏览器文本进行缓存分类,并针对每个类别的文件进行自然语言处理nlp分词,保存于分词库中,针对一段时间内分词库中的数据进行分词过滤,以减少数据的噪声;
第五步,离线训练组件在用户计算机资源空闲时,将过滤后的词汇库数据作为学习数据集参与预缓存训练;
第六步,离线训练组件经过不断地训练和学习,将相关参数设置于缓存分类器中,缓存分类器给出分类结果,所述分类结果为用户在某一时间段偏好浏览的内容关键字;
第七步,得到用户某一时间段偏好浏览的内容关键字后,页面爬虫组件预先将对应关键字的网页爬取出来并保存于缓存中,供用户在访问对应资源时,第一次访问便可以读到缓存内容。
所述第二步中,当内存使用率小于四分之一时,在趋势图上以标志a标明,5分钟标注一次;当cpu占用率小于四分之一时,在趋势图上以标志b标明,5分钟标注一次;离线训练组件不直接参与web用户的交互,当监控趋势图中a标志和b标志在1个小时内同时出现时,触发缓存预处理组件和离线训练组件。
所述第四步中,预处理组件将浏览器文本缓存文件进行处理,根据时间段(0:00-6:00、6:00-12:00、12:00-18:00、18:00-24:00),将文件分成四大类,类别编号分别为1、2、3、4;针对每个类别的文件,提取文件文本,利用自然语言处理nlp,进行文本词汇的抽取和分词,形成“词汇—类别号”的键值对关系,保存于分词库中;针对一段时间内(一天或者一周)分词库中的数据,人工操作分析出现较多并且不能反映用户偏好的词汇(如:“搜索”、“确认”等),将其删除和过滤,以减少数据的噪声。
所述第五步中,过滤后的词汇库数据中,80%作为机器学习的训练集,20%作为验证集;如果当前用户缓存内容较少,则进行多次分拆,实现交叉训练和验证。
所述第七步中,缓存分类器给出用户某一时间段偏好浏览的内容关键字后,页面爬虫组件在对应时间段的前一时间段,将对应关键字的一些网页爬取出来,按照时间排序,将最新的500条网页记录保存于缓存中。
所述第七步中,当缓存内容达到一定阈值(如:5g)时,开始激发一次离线训练组件,离线训练组件处于待工作状态;当计算机的内存和cpu空闲时,离线训练组件开始工作。
利用驱动模拟缓存技术webtraff对该基于机器学习的智能web代理缓存系统的缓存方法的最终插件进行了缓存模拟和验证。
以上所述的实施例,只是本发明具体实施方式的一种,本领域的技术人员在本发明技术方案范围内进行的通常变化和替换都应包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!