一种基于C-S和GRU的看画题诗方法与流程
本发明属于神经网络自动看画题诗的深度学习领域,涉及到目标检测、自然语言处理等技术,尤其涉及到一种基于c-s(cornernet-saccade)和gru(gaterecurrentunit)的看画题诗方法
背景技术:
随着深度学习在计算机视觉和自然语言处理领域的发展,人工智能已经日渐渗透人们的生活,在未来的艺术创作领域,人工智能也必然会有一番作为。在当今社会,艺术形式不断变化,古诗词的创作艺术不断流失,人类的非物质文化遗产也面临着危机,在高速的生活节奏下,保护古诗词等非物质文化遗产的传承也是社会应当重视的问题。深度神经网络通过训练学习到的看画题诗的方法,也是现代人工智能技术和古人智慧的一种结合。
相关技术中自动看画题诗方法目前较少,对画中提取的意象词和画的图像信息并没有做处理,也没有利用画所表达的中心思想作为建模方式,导致所作的诗文不对题,逻辑不通。
技术实现要素:
本发明克服了现有技术的不足之处,提出了一种基于cornernet-saccade和gru的看画题诗方法,意在提升现有计算机作诗效果,提升输入特定画作的美感,也可以利用本申请网络所作的诗提升画作的艺术价值。
本发明为达上述发明目的,采用如下技术方案:
一种基于cornernet-saccade和gru的看画题诗方法,其步骤包括:
步骤(1):对画用cornernet-saccade算法进行目标检测,softmax层对检测到的目标分类,获取意象词;将同一张画输入mobilenetv3网络,softmax层对画表达的中心思想分类,获取中心词。
步骤(2):为画数据集中所有人工方法标注的意象词、中心词建立词库并分配词向量,词向量大小为100维。
步骤(3):为五言诗数据集中古诗的每一个不重复的字都分配一个200维的向量,并建立字向量的库。
步骤(4):建立第一层gru网络,所述第一层gru网络由n个gru单元组成,其中最后一个单元连接一个全连接层和一个softmax层,用于生成所题诗的前2句。第一层gru网络输入为步骤(2)所有检测到的意象词词向量的和x和一个100的起始向量<bos>,即输入为c1=(x,<bos>),其中x=(x1+x2+…+xn),xi表示从画中检测到的每个意向词向量。通过第一层gru网络得到满足韵律要求的每个候选字的概率,选择概率最大的字作为五言诗的第一个字a1,然后利用再将第一个字的字向量
步骤(5):建立第二层gru网络,所述第二层gru网络由m个gru单元组成,最后一个单元连接一个全连接层和一个softmax层,用于生成所题诗的后2句,第二层gru网络的输入为意象词向量的和x和中心词向量y组成的向量
步骤(6):根据预先构建平仄函数和平仄矩阵以及预测的当前字的位置,确定预测当前字的平仄取值,在满足平仄取值的候选字中选取概率最大候选字。所述五言诗的平仄矩阵为:
平仄矩阵中p(i,j)代表当前字的位置,i代表诗句的行,j代表诗句的列。0表示该位置的字代表平仄不限,1或者-1代表该位置为平或者仄,2或-2表示该位置与第1句第2字平仄相同或相反,3或-3表示该位置与第1句第3字平仄相同或相反。
所述平仄函数为:
步骤(7):预测五言诗的第2、4句的最后一个字时需要还需要满足韵脚规律,根据预先构建的韵脚编码与汉字之间的映射表,确定要预测的当前字属于哪个汉字集,再从这个汉字集中的候选字选择概率最大的字的作为当前字。
所述韵脚编码与汉字之间映射表,其特征在于:依据平韵和仄韵,将106个韵脚进行编码,第一个韵脚编码为0,最后一个韵脚编码为105,将每个韵脚编号对应的汉字组合成汉字集,如{东,同,童…},在预测需要满足韵脚要求的字时,将一句最后一个字的韵脚根据编码映射到汉字集,并除去该字,并选取其余候选字中概率最大的字作为当前字。
与现有技术相比,本发明的有益效果体现在:
数据集为相关的五言诗和对应画,因为本发明用于生成五言诗,所以这样的数据集更有针对性。用cornernet-saccade提取了画中的意象词,用mobilenetv3提取了画的中心词,并建立了两种词的词库。针对五言诗前2句诗和后2句诗的特征做了不同的分析,双层的gru网络比传统的lstm、rnn更适用于本发明,对生成的诗做了韵律处理,使生成的诗更加具有美感和艺术性。
附图说明
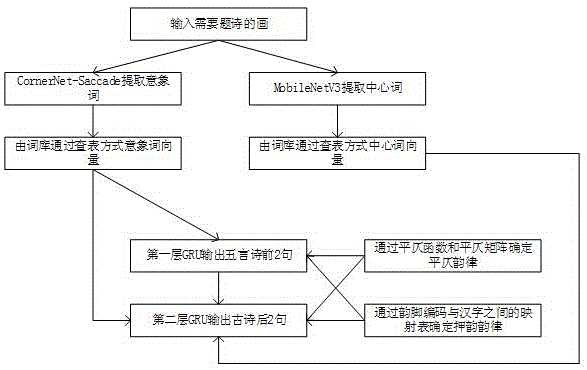
图1是本发明的方法流程图。
图2是cornernet-saccade网络结构示意图。
图3是mobilenetv3提取中心词示意图。
图4是第一层gru网络模型的结构示意图。
图5是第二层gru网络模型的结构示意图。
具体实施方式
下面结合附图对本发明做进一步说明。
如图1-5所示,本发明的于cornernet-saccade和gru的看画题诗方法,包括如下步骤:
步骤(1):收集为画题诗及为诗作画的画与诗,所述诗为五言诗,将收集到的五言诗数据中的每个不重复的字建立字库,并为每个字分配一个200维的向量;画数据中的人或物体的位置及其标签人工方法进行标注,画中每一个标注的人或物体代表一个意象词,为所有不重复的意象词建立词库。每张画都有欲表达的中心思想,用中心词表示中心思想,画的中心词类别标签人工方法标注,为所有不重复的中心词建立词库。为所有意象词、中心词都分配词向量,词向量大小为100维。
步骤(2):将步骤(1)标注好的画输入cornernet-saccade目标检测网络训练,训练集和验证集按照9:1的比例划分,模型的优化函数为计算随机梯度下降,学习速率为0.01,迭代5000次,将未标注的画输入到训练好的模型中,输出画中人、物体的预测框bk及类别,从而得到意象词,再从词库中获取意象词对应的词向量,如图2所示,其中k表示输入画中检测到的第k个预测框;将输出的预测框bk水平和垂直方向都分成10份,对每一份都进行最大池化(maxpooling),得到100维的特征
步骤(3):将步骤(1)中画数据送入mobilenetv3识别网络训练,目的是为了获得画的中心词,训练集和验证集按照9:1的比例划分,模型的优化函数为计算随机梯度下降,学习速率为0.01,迭代5000次。将未标注的画输入到训练好的模型中,输出画对应的中心词类别,从而得到画的中心词,再从词库中获取中心词对应的词向量,如图3所示。
步骤(3):为画数据中所有意象词、中心词分配词向量,词向量大小为100维。具体向量化时可以用word2vec技术,如“明月”表示为
x1=[0.011516,0.048745,…,0.075151];
如“寄托乡思”表示为
y=[0.021521,0.051561,…,0.072151]。
步骤(4):为五言诗数据集中古诗的每一个不重复的字都分配一个200维的向量,并建立字向量的库。具体向量化时可以用word2vec技术,如“床”表示为a1=[0.0853512,0.092564,…,0.078534]。
步骤(5):建立第一层gru网络,所述第一层gru网络由n个gru单元组成,其中最后一个单元连接一个全连接层和一个softmax层,用于生成所题诗的前2句,如图4所示。输入为意象词向量x和给定的100维起始向量<bos>,即输入为c1=(x,<bos>),其中x=(x1+x2+…+xn),xi表示从画中检测到的每个意向词向量。通过第一层gru网络得到满足韵律要求的每个候选字的概率,选择概率最大的字作为五言诗的第一个字a1,然后利用再将第一个字的字向量
步骤(6):建立第二层gru网络,所述第二层gru网络由m个gru单元组成,最后一个单元连接一个全连接层和一个softmax层,用于生成所题诗的后2句,如图5所示。五言诗后2句一般都带有升华的意境信息,如“野火烧不尽,春风吹又生”即表达一种自强不息的精神,为此,第二层gru网络的输入为意象词向量的和x和中心词向量y组成的向量
步骤(7):双层gru网络一同训练,模型优化函数为随机梯度下降,学习速率为0.01,迭代次数为5000次。
步骤(8):预测的当前字在每个候选字中选取概率最大的候选字,选取候选字的前提是需要满足韵律要求。所述韵律要求包括:平仄韵律,押韵韵律。所述平仄指的诗句中每个字的声调,即一、二声为平调、三、四声为仄调。如“风”、“昂”为平调,“爽”、“尽”为仄调。根据预先构建平仄函数和平仄矩阵以及预测的当前字的位置,确定预测当前字的平仄取值,在满足平仄取值的候选字中选取概率最大候选字。所述五言诗的平仄矩阵为:
平仄矩阵中p(i,j)代表当前字的位置,i代表诗句的行,j代表诗句的列。0表示该位置的字代表平仄不限,1或者-1代表该位置为平或者仄,2或-2表示该位置与第1句第2字平仄相同或相反,3或-3表示该位置与第1句第3字平仄相同或相反。
所述平仄函数为:
h(i,j)代表平仄取值。如当前字为“床”时,预测下一个字时从候选字中选取概率最大的且满足平仄取值的字,此时满足要求的字为“前”。
步骤(9):预测五言诗的第2、4句的最后一个字时需要还需要满足韵脚规律,如《静夜思》中“霜”“乡”是押韵的。根据预先构建的韵脚编码与汉字之间的映射表,确定要预测的当前字属于哪个汉字集,再从这个汉字集中的候选字选择概率最大的字的作为当前字。
所述韵脚编码与汉字之间映射表,其特征在于:是基于《平水韵》中的押韵规则建立映射表,《平水韵》将汉字分类为平韵和仄韵,平韵包括上平韵和下平韵,仄韵包括上声韵、去声韵、下声韵,所有韵律一共包含106个韵脚,依据平韵和仄韵,将106个韵脚进行编码,第一个韵脚编码为0,最后一个韵脚编码为105,将每个韵脚编号对应的汉字组合成汉字集,如{东,同,童…},在预测需要满足韵脚要求的字时,将一句最后一个字的韵脚根据编码映射到汉字集,并除去该字,并选取其余候选字中概率最大的字作为当前字。
综上所述,可将本发明的流程归结为如图1所示:1)输入需要题诗的画;2)cornernet-saccade做目标检测提取意象词,同时mobilenetv3提取输入图片的中心词;3)更具预先建立的词库分配好词向量;4)将意向词向量输入第一层gru网络输出五言诗的前2句;5)将意向词向量、中心词向量、第10个字的字向量加权组合后输入第二层gru网络输出五言诗的后2句。
- 还没有人留言评论。精彩留言会获得点赞!