一种神经网络权重矩阵拆分与组合的方法与流程
本发明属于深度学习
技术领域:
,涉及一种神经网络权重矩阵拆分与组合的方法,尤其涉及一种图像目标检测中yolo系列神经网络权重矩阵拆分与组合方法。
背景技术:
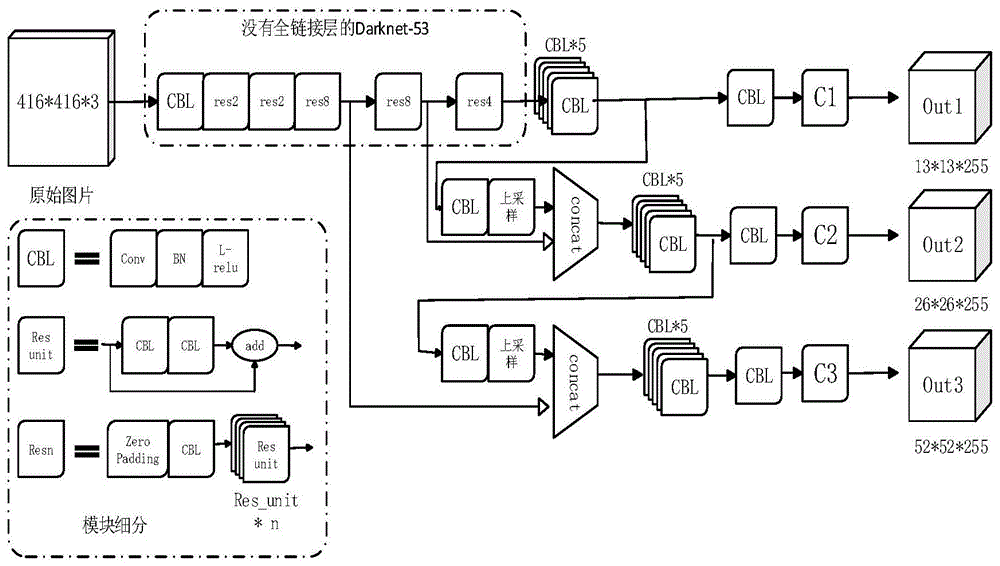
:深度学习的概念源于人工神经网络的研究,是机器学习的分支,是一种以人工神经网络为架构,对数据进行表征学习的算法。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。其中,目标检测是与计算机视觉和图像处理有关的计算机技术,其涉及在数字图像和视频中检测特定类(例如人、建筑物或汽车)的语义对象的实例。目标检测在计算机视觉的许多领域都有应用,包括图像检索和视频监控。深度学习的核心就是卷积操作,它是用特定的卷积核(矩阵)来对整个输入图片(矩阵)通过对应元素相乘并求和来进行遍历。目的就是为了提取图像的抽象特征,一般来说网络结构越复杂和越深,它的效果会更好。一个完整的模型就是由很多卷积层与其它层堆叠而成。目标检测中的rcnn系列算法遵循2-stage的流程:首先找出一系列(预先设定好的)候选区域,而后对这些候选区域进行分类以及位置修正。yolo则开启了1-stage的流派:直接用一个深度网络,回归出目标的位置和归类。yolo(youonlylookonce)是一个实时的目标检测系统,是一个使用卷积神经网络的目标检测框架,由大量的卷积层与其它层组合而成。它采用回归的方法进行目标框的检测以及分类;输入一张图片,马上可以得到图片中的物体类别与具体的坐标,它的检测速度很快,可以达到视频实时检测的需求。yolo首先将图像分割成多个大小相同的网格,再对每个网格分别预测里面有物体的概率以及物体类别和坐标的信息,然后再去除掉重复以及多余的检测框,最后可以得到需要的结果。yolo将物体检测作为回归问题求解,基于一个单独的端到端网络,完成从原始图像的输入到物体位置和类别的输出。它还是一种在工业界广泛使用的实时目标检测模型,以检测速度快闻名。基础yolo检测器的速度能够达到45fps,更快的fastyolo则能够达到惊人的155fps。采用yolo实时目标检测系统的目标检测工程实施的一般过程是:1.确定要检测的物体种类,并搜集图片,以得到训练集,确定要使用的网络结构;2.使用在大型数据集上训练的预训练权重,或者完全从零开始训练自己的权重,后者比前者所花的时间更多。3.权重文件训练好之后就可以使用了。如果在使用中发现需要添加新的类别,这时需要在原有训练集中添加新的类别图片并且比例和原有类别保持一致;或者要移除一些不再需要的类别,这种情况下需要移除训练集中对应类别的图片。4.使用新的训练集重新训练,训练后得到一个新的权重并使用。在上述的场景中,一旦当有新的类别需要加入或者原有类别需要分离时,就需要重新整理训练集并训练,而这个过程会耗费较多的时间。第二种方法是针对新的类别再重新训练一个不同的神经网络权重矩阵,与第一个网络平等地单独部署上线,但这会浪费多余的资源。这些多余的时间和资源耗费显然不是必要的。技术实现要素:本发明的目的,亦即本发明要解决的技术问题是:解决现有目标检测任务中,当更新所训练的模型时需要将整个网络重新训练,耗费时间和资源的不足之处,提供一种只需训练新添加的类别将其加入原有的模型之中或者删除以前不需要的类别来组合为新的模型的,神经网络权重矩阵拆分与组合的方法。为解决上述技术问题,本发明采用了以下技术方案:本发明一种神经网络权重矩阵拆分与组合的方法,该方法用于具有one-stage网络结构的目标检测中,在进行目标检测时,首先确定要检测的物体种类(n类),通过收集图片数据进行训练,得到一个可以用来进行目标检测的效果好的神经网络权重矩阵,即原始权重矩阵w1;原有n个类别,当其中某一类或者多个类别(j个类别)不再需要需移除时,要进行神经网络权重矩阵的拆分,即将原始权重矩阵中的某一类或者多个类别提取出来,亦即,将n类减少为n-1类或n-j类;当其中某一类或者多个类别(j个类别)需要更新或者需要添加新类别时,要进行神经网络权重矩阵的组合(即合并),亦即,将原始权重矩阵中的某一类或者多个类别提取出来进行单独训练之后,再通过权重矩阵组合添加合并进去。进一步地,进行神经网络权重矩阵的拆分与组合的方法如下:(1)神经网络权重矩阵的拆分拆分是指将包含多种检测类别的神经网络权重矩阵中的某一类或者多类单独提取出来,并保持原有类别的识别效果不变;拆分的方法是:将多余的一个类别或j个类别在原始权重矩阵w1的三个不同尺度层的最后一个卷积层即c1、c2、c3层的卷积核上的对应值直接移除,即将c1、c2、c3层的权重矩阵的第二个维度从n=(5+n)*3改为b=(n-1+5)*3或b=(n-j+5)*3,其它层的权重矩阵保持不变;即完成对w1的拆分修改,拆分修改后的w1称为w2。进行神经网络权重矩阵拆分的具体方法如下:a、将原始权重矩阵w1的三个不同尺度层的最后一个卷积层取出,分别为c1、c2、c3层,得到三个维度分别为m*n的权重矩阵,m为上一层通道数,n为本层通道数;原始权重矩阵w1有n类,则n=(5+n)*3;b、在n中提取出相应的要单独提取出来的一类或者多个类别对应的维度,即提取出n列中的对应列,记为a;当只提取出一类时,a为(5+1)*3=18;当提取出两个类别时,a为(5+2)*3=21;当提取出j个类别时,a为(5+j)*3;c、将提取出来的一类或者多个类别的新的维度组成一个m*a的权重矩阵,将提取之后剩下的n-1或n-j个类别的维度组成一个新的权重矩阵,替换掉原本的卷积层;原始权重矩阵的第二个维度是n=(5+n)*3,提取一类之后,提取出的那一类的权重矩阵的第二个维度是a=(5+1)*3=18,提取之后剩下的n-1类的权重矩阵的第二个维度是b=(n-1+5)*3;提取j个类别之后,提取出的那j个类别的权重矩阵的第二个维度是a=(5+j)*3,提取之后剩下的n-j个类别的权重矩阵的第二个维度是b=(n-j+5)*3;d、用相同的方法处理卷积层的偏置矩阵;e、得到拆分后的新权重矩阵w2。(2)对取出的权重矩阵或要添加的新类别的权重矩阵w3单独进行训练需要更新时,从原神经网络权重矩阵w1中提取出其中的某一类或者多个类别的权重矩阵,对取出的权重矩阵进行单独训练之后再添加进去;需要添加新类别时,从原神经网络权重矩阵w1中任意提取出其中的某一类或者多个类别的权重矩阵,作为模板,进行单独训练之后再添加进去;(添加新类别时,这一类或者多个类别可以任取,相当于只是提取一个模板出来进行单独训练);使用新类别的数据集只对上面提取出来的c1、c2、c3三个卷积层进行单独训练,这样就得到新类别的神经网络权重矩阵(只有三个卷积层被更新为新类别的参数)。具体方法如下:①将w1复制得到w3,使用w3作为预训练权重矩阵进行新类别的训练;并且,在训练时,停止除c1、c2、c3卷积层以外其它层参数的更新;也就是,只对三个输出卷积层即c1、c2、c3层进行训练。②训练后的w3中c1、c2、c3卷积层所对应的新的权重参数,就是识别新类别所需的信息,记为d1、d2、d3。提取出1个类别时,将w1复制得到w3,将w3的c1、c2、c3卷积层修改为单类别的形式。(3)神经网络权重矩阵的组合(即合并)组合是指将第二步单独训练的新类别的权重矩阵w3与原有的神经网络权重矩阵(包括原始权重矩阵w1和拆分修改后的权重矩阵w2)合并为一个权重文件的过程;该过程最大化了原始权重矩阵的作用,只需要添加少部分的权重文件便完成了类别的更新;具体方法如下:a、将新权重矩阵w3的c1、c2、c3卷积层取出,维度为m*a,a=(5+j)*3;同样,取出原有的权重矩阵w1或w2对应的层即c1、c2、c3卷积层,w1的维度为m*n,n=(5+n)*3;w2的维度为m*b,b=(n-j+5)*3;b、将要合并的两个权重矩阵直接在m维度方向上连接到一起,形成一个维度为m*c的权重矩阵(c不等于a+b),c=(n-j+5+jz)*3+((n-j)z+5+j)*3,下角标z表示占位;操作时,除了类别的维度,还要带上坐标和置信度五个维度一起连接。亦即,将新训练的权重矩阵w3与原有权重矩阵w1或w2(即原始权重矩阵w1或拆分修改后的权重矩阵w2)合并;w3与w1或w2之间,除了上述c1、c2、c3三个卷积层以外,其它层都是相同的;w3与w1或w2合并完成后,得到新的权重矩阵w4;w4相比原本的w1或w2,权重矩阵模型的大小(占用空间,存储大小)只增加了极小一部分。进一步地,神经网络权重矩阵的组合方法为:①将w3中d1、d2、d3层的参数添加到w1或w2中对应的c1、c2、c3三个卷积层中。②添加要保证类别的对应,应在c1、c2、c3部分加入对新类别的占位,在d1、d2、d3部分添加对原类别的占位。进一步地,使用aeras等高级深度学习框架来对权重文件进行修改,也就是对权重矩阵模型的卷积层进行修改。进一步地,该方法中,占位要将权重项置为零,偏置项置为负值,保证对原有类别不产生影响;亦即,将c中除了a+b,其他多余的部分,置为零,在格式上占个位,方便解析最后的结果。进一步地,该方法中,拆分、合并操作要在每个尺度上进行(有三个不同尺度)。该方法可根据新类别尺度大小来添加部分卷积层,自由度很大。本发明的有益效果:本发明的方法能够实现目标检测模型的自由拆分与合并,节省训练时间,简化训练步骤,针对不同的尺度具有较高的自由度。总的来说,能以较高的准确度快速部署于修改模型。该方法是一种可以用在类似的one-stage网络结构里的通用方法。本发明的方法可以向工业目标检测领域推广。随着图像处理尤其是视频安防检测的迅猛发展,快速、灵活地部署一个检测模型并保持后续更新变得越来越重要。本方法能够改善一般方法中部署后不容易更新修改的缺点,简单快速地完成新类别的训练并加入到原有类别之中,具有一定的推广价值。附图说明图1是本发明中的yolov3网络架构图;图2是本发明的神经网络权重矩阵拆分与组合的方法的流程示意图;图3是本发明的方法应用到履带式智能小车上的示意图。图中:1、摄像头2、智能小车具体实施方式以下结合附图和实施例对本发明作进一步的说明。实施例1本实施例以yolov3(yolo系列第三版)为例,说明本发明一种针对yolov3的神经网络权重矩阵拆分与组合的方法。下面以标准416*416在coco训练集上训练的80类的yolov3为例,层序号以其中共106层编号为标准。如图1所示,本发明中的yolov3网络结构简介如下:输入:三通道彩色图片(416*416*3);输出:分别预测不同大小目标的三个尺度(13*13,26*26,52*52)的预测结果。daranet-53:一个53层的特征提取网络,可以将图片的抽象特征提取出来。其中,cbl:卷积层(conv)+批量归一化层(bn)+激活层(l-relu),主要执行卷积操作。res_unit:残差模块,包含2个cbl和跳级相加的残差结构,可以显著减轻网络结构太深时梯度消失的影响。resn:具有一个cbl和n个残差模块的合并层,zeropadding是对输入做填充以保证大小对应。上采样:将特征图使用最邻近插值放大一倍以检测小目标。concat:矩阵拼接合并操作。c:纯卷积层;c1、c2、c3指权重矩阵的三个不同尺度层的最后一个卷积层(即输出卷积层);后续类别分割和合并操作主要在本层上执行。out:输出层;out1、out2、out3,指三个不同尺度的输出层。如图2所示,本发明一种针对yolov3的神经网络权重矩阵拆分与组合的方法:首先确定要检测的物体种类(n=80类),通过收集图片数据进行训练,得到一个可以用来进行目标检测的效果好的神经网络权重矩阵,即原始权重矩阵w1;再根据需要,对神经网络权重矩阵进行拆分与组合,方法如下:1)神经网络权重矩阵的拆分原有n=80种类别,现有1类或j个类别不再需要或者需要更新待处理,即要将80类减少为n-1=79类或n-j类;拆分是指将包含多种检测类别的神经网络权重矩阵中的某一类或者多类单独提取出来,并保持原有类别的识别效果不变;拆分的具体方法如下:a、将原始权重矩阵w1的三个不同尺度层的最后一个卷积层取出,分别为c1、c2、c3层(即图1中三个c层即81、93和105层),得到三个维度分别为m*n的权重矩阵,m为上一层通道数,n为本层通道数;原始权重矩阵有80类,则n=(5+n)*3=255;原始权重矩阵w1的c1层即81层的m与n分别为1024和255,m*n=1024*255;c2层即105层的m与n分别为512和255,m*n=512*255;c3层即105层的m与n分别为256和255,m*n=256*255;b、在n中取出相应的要单独提取出来的一类或者多个类别对应的维度,即取出n列中的对应列,记为a;当只提取出一类时,维度a为(5+1)*3=18;当取出两个类别时,维度a为(5+2)*3=21;当提取出j个类别时,维度a为(5+j)*3。c、将提取出来的一类或者多个类别的新的维度组成一个m*a的权重矩阵,将提取之后剩下的n-1或n-j个类别的维度组成一个新的权重矩阵,替换掉原本的卷积层;原始权重矩阵的第二个维度是n=(5+n)*3,提取一类之后,提取出的那一类的权重矩阵的第二个维度是a=(5+1)*3=18,提取之后剩下的n-1类的权重矩阵的第二个维度是b=(n-1+5)*3;提取j个类别之后,提取出的那j个类别的权重矩阵的第二个维度是a=(5+j)*3,提取之后剩下的n-j个类别的权重矩阵的第二个维度是b=(n-j+5)*3;d、用相同的方法处理卷积层的偏置矩阵;e、得到拆分后的新权重矩阵w2。亦即,神经网络权重矩阵的拆分,是将多余的一个类别或j个类别在原始权重矩阵w1的三个不同尺度层的最后一个卷积层即c1、c2、c3层的卷积核上的对应值直接移除,即将c1、c2、c3层的权重矩阵的第二个维度从n=(5+n)*3改为b=(n-1+5)*3或b=(n-j+5)*3,最后c1、c2、c3变为1024*252、512*252、256*252;其它层的权重矩阵保持不变;即完成对w1的修改,修改后的w1称为w2。(2)对取出的或要添加的新类别的权重矩阵w3单独进行训练需要更新时,从原神经网络权重矩阵w1中提取出其中的某一类或者多个类别的权重矩阵,对取出的权重矩阵进行单独训练之后再添加进去;需要添加新类别时,从原神经网络权重矩阵w1中任意提取出其中的某一类或者多个类别的权重矩阵,作为模板,进行单独训练之后再添加进去;(添加新类别时,这一类或者多个类别可以任取,相当于只是提取一个模板出来进行单独训练);使用新类别的数据集只对上面提取出来的c1、c2、c3三个卷积层进行单独训练,这样就得到新类别的神经网络权重矩阵(只有三个卷积层被更新为新类别的参数)。具体方法如下:①将w1复制得到w3,使用w3作为预训练权重矩阵进行新类别的训练;并且,在训练时,停止除c1、c2、c3卷积层以外其它层参数的更新;也就是,只对三个输出卷积层即c1、c2、c3层(81、93和105层)进行训练。②训练后的w3中c1、c2、c3卷积层所对应的新的权重参数,就是识别新类别所需的信息,记为d1、d2、d3。提取出1个类别时,将w1复制得到w3,将w3的c1、c2、c3卷积层修改为单类别的形式,即1024*18、512*18、256*18,其中,18=(1+5)*3。(3)网络权重矩阵的组合(即合并)组合是指将原有的神经网络权重矩阵与第二步新训练的权重矩阵合并为一个权重文件的过程;该过程最大化了原始权重矩阵矩阵的作用,只需要添加少部分的权重文件便完成了类别的更新;具体方法如下:a、将新权重矩阵w3的c1、c2、c3卷积层取出,维度为m*a,a=(5+j)*3;同样,取出原有的权重矩阵w1或w2对应的层即c1、c2、c3卷积层,w1的维度为m*n,n=(5+n)*3;w2的维度为m*b,b=(n-j+5)*3;b、将要合并的两个权重矩阵直接在m维度方向上连接到一起,形成一个维度为m*c的权重矩阵(c不等于a+b),c=(n-j+5+jz)*3+((n-j)z+5+j)*3,下角标z表示占位;操作时,除了类别的维度,还要带上坐标和置信度五个维度一起连接。亦即,将新训练的权重矩阵w3与原有权重矩阵w2合并;w2与w3除了上述3个卷积层以外其它层都是相同的;w3与w2合并完成后得到新的权重矩阵w4;w4相比原本的w1,模型权重大小只增加了极小一部分。①将w3中d1、d2、d3层的参数添加到w1或w2中对应的c1、c2、c3卷积层即81、93和105层中。当w3为1个类别时,维度a为(5+1)*3=18,将(1+5)*3=18个维度加入到(79+5)*3=252中;当w3为j个类别时,维度a为(5+j)*3,则将(5+j)*3个维度加入到(n-j+5)*3个维度中。②添加要保证类别的对应,应在c1、c2、c3部分加入对新类别的占位,在d1、d2、d3部分添加对原类别的占位。当w3为1个类别时,合并后的c为(79+1+5)*3+(79+1+5)*3=510,所以,添加完成后,最后的3个卷积层变为1024*510,512*510,256*510。当w3为j个类别时,合并后的c=(n-j+5+jz)*3+((n-j)z+5+j)*3,下角标z表示占位。该方法中,拆分、合并操作要在每个尺度上进行(有三个不同尺度),即有多个图2中所示的5+1(一个类别)或5+n(多个类别)。该方法中,占位要将权重项置为零,偏置项置为负值,保证对原有类别不产生影响;亦即,将c中除了a+b,其他多余的部分,置为零,在格式上占个位,方便解析最后的结果。该方法可根据新类别尺度大小来添加部分卷积层,自由度很大。在增加一个新类别时,本发明的方法与普通方法的效果对比如下:表1本发明的方法与普通方法的效果对比普通方法(重训练)普通方法(加模型)本发明的方法权重模型大小基本不变增加一倍基本不变训练耗时大于原训练时间较短较短检测速度基本不变增加一倍不变检测质量下降不变不变实施例2使用keras高级深度学习框架来对权重文件进行修改,也就是对权重矩阵模型的卷积层进行修改。下面以修改yolov3权重文件为例。首先确定要检测的物体种类(原始包含80种类别),通过收集图片数据训练yolov3得到一个效果较好的卷积神经网络权重,称为原始权重矩阵w1,可以用来进行目标检测的任务。1、现有1类不再需要或者需要更新待处理,所以要将这1类提取出来,即要将80类减少为79类。对应图1的y1、y2、y3输出13*13*255、26*26*255、52*52*255应修改为13*13*252、26*26*252、52*52*252。1.1经过分析可以知道,原始权重矩阵w1有三个输出卷积层(图1中的3个c层),即c1、c2、c3层。它们的卷积核维度分别为1024*255、512*255、256*255,分别对应检测不同尺度上的目标。1.2每个卷积核上都有80个类别的对应节点,用来判断不同的类别。255表示(80+5)*3,80代表80个类别,5代表4个坐标值(中心点坐标与长宽值)与1个置信度。乘3代表预测3个不同长宽比形状的矩形框,3个c层均各有3个。1.3将多余的一个类别在原始权重矩阵w1的三个不同尺度层的最后一个卷积层即c1、c2、c3层的卷积核上的对应值直接移除,即将c1、c2、c3层的权重矩阵的第二个维度从n=(5+n)*3改为b=(n-1+5)*3=(79+5)*3=252,最后c1、c2、c3变为1024*252、512*252、256*252;其它层的权重矩阵保持不变;即完成对w1的修改;修改后的w1变成为w2。如要将多余的j个类别在原始权重矩阵w1的三个不同尺度层的最后一个卷积层即c1、c2、c3层的卷积核上的对应值直接移除,即将c1、c2、c3层的权重矩阵的第二个维度从n=(5+n)*3改为b=(n-j+5)*3,其它层的权重矩阵保持不变;即完成对w1的修改;修改后的w1变成为w2。2.现有一个新的检测类别需要添加到原有权重矩阵(拆分后修改的权重矩阵w2)中,所以,先要对新类别的权重矩阵w3进行单独训练。(新类别为一类)2.1将w1复制得到w3,将w3的c1、c2、c3卷积层修改为单类别的形式。即1024*18、512*18、256*18,其中,18=(1+5)*3。2.2使用w3作为预训练权重矩阵矩阵进行新类别的训练。并且,在训练时停止除c1、c2、c3卷积层以外其它层参数的更新。也就是只对三个输出卷积层(81、93和105层)进行训练。2.3训练后的w3中c1、c2、c3卷积层所对应的新的权重参数就是识别新类别所需的信息,记为d1、d2、d3。3.将新训练的新类别的权重矩阵w3与原有权重矩阵(拆分后修改的权重矩阵w2)合并。w2与w3除了上述3个c1、c2、c3卷积层以外其它层都是相同的。3.1将d1、d2、d3层的参数添加到w2中对应的3个c1、c2、c3卷积层即81、93和105层中。添加一个类别时,维度a为(5+1)*3=18,即将(1+5)*3=18个维度加入到(79+5)*3=252中;如果要添加j个类别时,维度a为(5+j)*3,则将(5+j)*3个维度加入到(n-j+5)*3个维度中;3.2添加要保证类别的对应,应在c1、c2、c3部分加入对新类别的占位,在d1、d2、d3部分添加对原类别的占位。添加一个类别时,添加连接的公式为(79+1+5)*3+(79+1+5)*3=510,所以,添加完成后,最后的3层变为1024*510,512*510,256*510。如果要添加j个类别时,维度a为(5+j)*3,则将(5+j)*3个维度加入到(n-j+5)*3个维度中,添加连接的公式是c=(n-j+5+jz)*3+((n-j)z+5+j)*3,下角标z表示占位。4.合并完成后得到新的权重矩阵w4,相比原本的w1,模型权重大小只增加了极小一部分。应用实施例将通过本发明实施例1和实施例2的方法处理的目标检测模型移植到履带式智能小车上,与智能小车配合,并实时检测它所拍摄的画面。如图3所示,通过摄像头1拍摄画面回传,来实时对智能小车2拍摄的画面进行分析,检测图像中的目标。摄像头不仅拍摄常规图像,还包括红外、星光等其它类型的图像。通过用以上方法对目标检测模型进行处理,分割不需要识别的类别,整合需要识别的类别。比如,停车场使用时需要检测车辆,而到了安防场景下需要检测人员。这样就可以把智能小车快速部署到不同的应用场景,更加高效地识别各种需要的类别。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1