一种多轮对话意图识别方法与流程
本发明涉及自然语言处理
技术领域:
,具体涉及一种多轮对话意图识别方法。
背景技术:
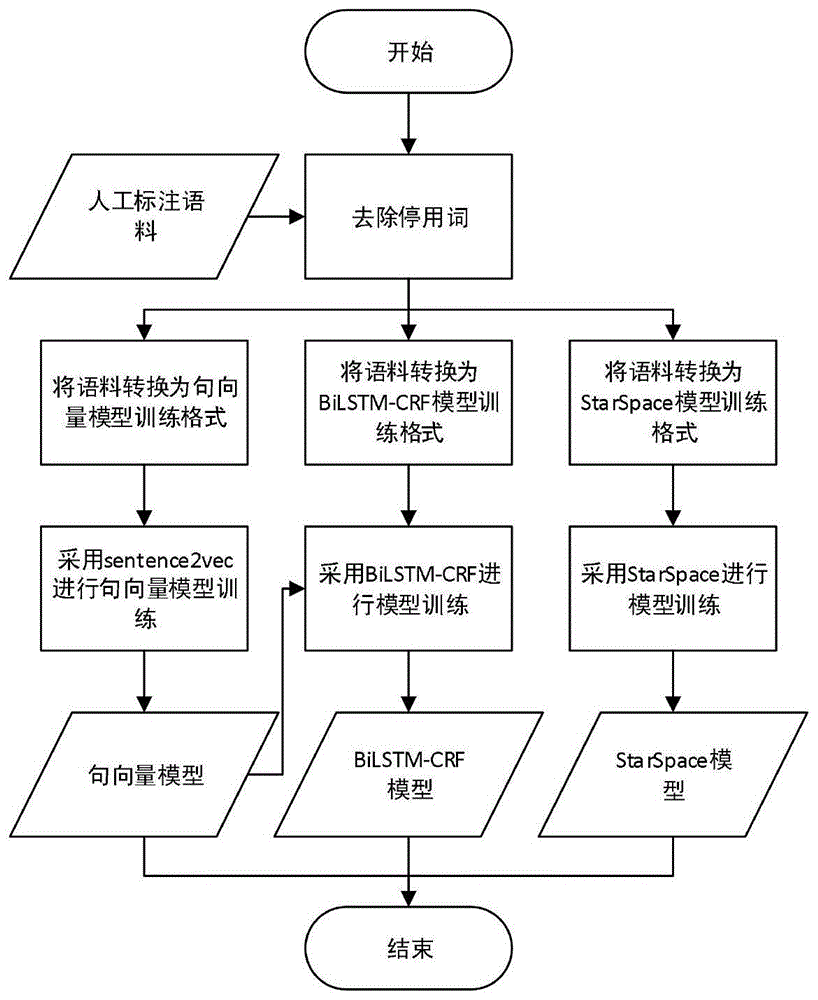
:如今人类进入了人工智能时代,众多企业都在开发自己的客服机器人。这不仅方便用户24小时咨询问题,也减轻了企业雇佣客服人员的成本,然而目前多数客服机器人并没有非常智能,不能满足用户的实际需求,例如,目前,客服机器人对话意图识别方式类型主要有三种:第一种采用规则模板的方法。即通过收集大量用户语料,人工整理出用户咨询问题模板,然后机器人根据模板匹配结果回答用户问题。这种方式准确率较高,适合小规模的客服机器人。第二种采用传统机器学习的方法。即将意图识别问题看成分类问题,通过支持向量机、随机森林等分类方法,在基于用户标注语料训练下得到分类模型,然后机器人根据模型预测用户意图,进而回答用户问题。这种方式节省了大量人工整理用户问题模板时间,而且机器人泛化能力较强。第三种采用深度学习的方法。即采用当下最热门的深度学习模型,如长短期记忆网络、双向长短期记忆网络等方法,在基于巨大量的用户标注语料下得到深度学习模型,然后机器人根据模型预测用户意图,进而回答用户问题。这种方式考虑到了用户对话信息的上下文联系,而且机器人泛化能力强,适合于大规模的客服机器人。比较三种方法,方案一的缺点是,需要大量人工去整理用户语料,形成用户问题模板,然后对客服机器人进行配置。对于那些没有整理配置的问题,机器人无法进行回答,泛化能力很差。方案二,虽然也需要人工标注语料,但是标注难度比方案一小很多,并且可以采用模型辅助进行语料标注。客服机器人的泛化能力也有所提升。方案三,需要投入大量的人工去标注语料,其语料标注规模是前两种方案的几十倍甚至百倍,但正因如此方案三从中很好地学习了用户对话与意图间的转化关系,极大地提高了意图识别的准确率和机器人的泛化能力。技术实现要素:为了解决现有客服机器人意图识别的不足之处,本发明提供了一种多轮对话意图识别方法,该方法基于人工标注用户对话语料,通过采用双向长短期记忆网络-条件随机场(bilstm-crf)模型联系对话上下文,采用starspace模型进行意图分类,根据意图分类模型计算得到的意图置信度进行排序过滤,输出最佳意图。本发明的技术方案如下:一种多轮对话意图识别方法,其特征在于,包括如下步骤:1)根据应用场景确定要识别的对话意图,并获取大量对话数据,人工找出对话数据中的对话块以及其对应的意图,进行语料标注;2)根据人工整理好的停用词表去除对话数据中的停用词;3)构建用于意图识别的句向量模型、bilstm-crf模型及starspace模型;4)由句向量模型、bilstm-crf模型和starspace模型实时获取对话数据,进行意图识别,输出最佳意图。所述的一种多轮对话意图识别方法,其特征在于,所述步骤2)具体为:2.1)将对话数据使用分词工具进行分词;2.2)将分词结果中的每个词与停用词表中的词进行判断,若分词结果中的词在停用词表中存在,则去除该词,否则保留;2.3)将2.2)得到的结果拼接为句子。所述的一种多轮对话意图识别方法,其特征在于,所述步骤3)中句向量模型构建步骤具体为:3.1)获取去除停用词后的人工标注语料,将语料中的每句话按字符拆分为list,最终得到整个语料的list列表;3.2)设置sentence2vec算法的预设参数,句子嵌入向量空间的维度n和语料总共使用的次数epoch;3.3)将3.1)中得到的语料list列表作为sentence2vec的输入,进行句向量模型训练;3.4)将3.3)训练得到的句向量模型存储到磁盘上。所述的一种多轮对话意图识别方法,其特征在于,所述步骤3)中bilstm-crf模型构建步骤具体为:3.5)获取去除停用词后的人工标注语料,首先使用句向量模型将对话转化为句向量,然后根据对话块标注块标签,其中,b表示块开始位置,i表示块中位置,e表示块结束位置,o表示其他位置;3.6)设置bilstm-crf模型预设参数,模型隐藏层大小hidden_size、随机失活率dropout、语料总共使用的次数epoch、每批次大小batch_size;3.7)将3.5)进行块标注后的语料作为bilstm-crf模型的输入,进行bilstm-crf模型训练;3.8)将3.7)训练得到的bilstm-crf模型存储到磁盘上。所述的一种多轮对话意图识别方法,其特征在于,所述步骤3)中starspace模型构建步骤具体为:3.9)获取去除停用词后的人工标注语料,只取有意图的对话块,将对话块中的句子拼接起来,与其对应的意图形成key-value对,存储在list中。3.10)设置starspace模型预设参数,对话嵌入粒度、模型隐藏层大小hidden_size、语料总共使用的次数epoch、每批次大小batch_size。3.11)将3.9)得到的存有key-value对的list作为starspace模型的输入,进行starspace模型训练;3.12)将3.11)训练得到的starspace模型存储到磁盘上。所述的一种多轮对话意图识别方法,其特征在于,所述步骤4)具体为:4.1)从对话数据中获取一句对话;4.2)根据停用词表去除对话中的停用词;4.3)将对话输入句向量模型中,得到对话的句向量;4.4)将对话及其句向量存储到对话列表中;4.5)使用bilstm-crf模型对对话列表进行对话分块;4.6)根据4.5)得到的对话分块结果,若结果末端为一个对话块,则进入4.7),否则跳转到4.1);4.7)将4.6)得到的对话块中的句子拼接起来,使用starspace模型进行意图分类;4.8)根据意图分类结果,若意图分类结果置信度大于预设置置信度阈值c,则输出意图,否则该意图分类结果被过滤;4.9)输出最佳意图,若存在未处理的对话数据,则跳转到4.1),否则算法结束。本发明的有益效果是:1)本发明采用了深度学习的方法,克服了
背景技术:
方案一泛化能力差的问题。将联系用户对话上下文看作序列标注问题,采用序列标注方法进行对话分块,很好的解决了方案二没有考虑上下文联系的问题。2)由于本发明将意图识别抽象为了序列标注问题和分类问题,采用两个深度学习模型分别负责语义联系和意图分类,与方案三采用一个深度学习模型同时负责这两个功能相比,本发明所需的语料远低于方案三所需的语料,在保证准确率和泛化能力的前提下,采用本发明的方法大大降低了人工标注语料的成本,克服了方案三语料标注成本高的问题。3)本发明意图识别高效,准确率高,泛化能力强,人工标注语料成本低。附图说明图1表示本发明方案的模型构建流程图;图2表示本发明方案的意图识别流程图。具体实施方法下面结合说明书附图,并结合实施例来说明本发明的算法实施方法。一种多轮对话意图识别方法,包括如下步骤:步骤1:根据应用场景确定要识别的对话意图,并获取大量对话数据,人工找出对话数据中的对话块以及其对应的意图,进行语料标注;人们通常会用连续几句话来表达同一个意图,我们称之为对话块。在语料标注之前,首先根据客服机器人应用场景确定机器人想要识别的意图名称。然后,取一通完整的对话数据,人工找出对话中的对话块以及其对应的意图,进行标注,最后,我们将标注好的对话数据存储到磁盘上。本发明采用了三个深度学习模型(句向量模型、bilstm-crf模型、starspace模型),它们都由多层神经网络构成。因此,需要通过大量人工标注语料来训练优化模型参数。步骤2:根据人工整理好的停用词表去除对话数据中的停用词;由于人们在对话中会使用大量的虚词、语气词等停用词,而这些词频繁出现,不仅影响意图识别的准确率,还极大的造成了存储空间的浪费,所以根据人工整理好的停用词表去除对话数据中的停用词。s1)将对话数据使用分词工具(如:jieba分词)进行分词;s2)将分词结果中的每个词与停用词表中的词进行判断,若分词结果中的词在停用词表中存在,则去除该词,否则保留;s3)将s2得到的结果拼接为句子。步骤3:构建用于意图识别的句向量模型、bilstm-crf模型及starspace模型,为之后意图识别提供底层模型支撑。构建句向量模型:该模型可以将句子嵌入到向量空间中。模型有两个参数需要预先设定:1)句子嵌入向量空间的维度n;2)模型训练过程中,语料总共使用的次数epoch。s1)获取去除停用词后的人工标注语料,将语料中的每句话按字符拆分为list,最终得到整个语料的list列表;s2)设置sentence2vec算法的预设参数,句子嵌入向量空间的维度n和语料总共使用的次数epoch;s3)将s1中得到的语料list列表作为sentence2vec的输入,进行句向量模型训练;s4)将s3训练得到的句向量模型存储到磁盘上。构建bilstm-crf模型:该模型可以进行对话分块,用于联系对话上下文。模型需要预先设定参数:1)块标签,通常为[b,i,e,o];2)模型隐藏层大小hidden_size;3)随机失活率dropout;4)模型训练过程中,语料总共使用的次数epoch;5)模型训练过程中,每批次大小batch_size。s1)获取去除停用词后的人工标注语料,首先使用句向量模型将对话转化为句向量,然后根据对话块标注块标签,其中,b表示块开始位置,i表示块中位置,e表示块结束位置,o表示其他位置;s2)设置bilstm-crf模型预设参数,模型隐藏层大小hidden_size、随机失活率dropout、语料总共使用的次数epoch、每批次大小batch_size;s3)将s1进行块标注后的语料作为bilstm-crf模型的输入,进行bilstm-crf模型训练;s4)将s3训练得到的bilstm-crf模型存储到磁盘上。构建starspace模型:该模型可以进行意图分类,并输出意图置信度。模型需要预先设定参数:1)对话嵌入粒度,字符或词;2)模型隐藏层大小hidden_size;3)模型训练过程中,语料总共使用的次数epoch;4)模型训练过程中,每批次大小batch_size。s1)获取去除停用词后的人工标注语料,只取有意图的对话块,将对话块中的句子拼接起来,与其对应的意图形成key-value对,存储在list中;s2)设置starspace模型预设参数,对话嵌入粒度、模型隐藏层大小hidden_size、语料总共使用的次数epoch、每批次大小batch_size;s3)将s1得到的存有key-value对的list作为starspace模型的输入,进行starspace模型训练;s4)将s3训练得到的starspace模型存储到磁盘上。步骤4:由句向量模型、bilstm-crf模型和starspace模型实时获取对话数据,进行意图识别,输出最佳意图。该部分的目的是根据实时对话数据,高效准确地进行意图识别,为客服机器人提供意图识别能力。在意图识别流程中需要设置置信度阈值c,用于过滤意图分类结果,只输出意图分类置信度大于阈值c的意图,提高意图识别准确率。由第一部分构建模型得到了句向量模型、bilstm-crf模型和starspace模型。它们为意图识别提供了基础能力。算法实时获取对话数据,进行意图识别,输出最佳意图,具体步骤如下:s1)从对话数据中获取一句对话;s2)根据停用词表去除对话中的停用词;s3)将对话输入句向量模型中,得到对话的句向量;s4)将对话及其句向量存储到对话列表中;s5)使用bilstm-crf模型对对话列表进行对话分块;s6)根据s5得到的对话分块结果,若结果末端为一个对话块,则进入s7,否则跳转到s1;s7)将s6得到的对话块中的句子拼接起来,使用starspace模型进行意图分类;s8)根据意图分类结果,若意图分类结果置信度大于预设置置信度阈值c,则输出意图,否则该意图分类结果被过滤;s9)输出最佳意图,若存在未处理的对话数据,则跳转到s1,否则算法结束。本发明的实施例:由于模型训练需要大量的人工标注语料,我们以标注一则对话为例。假设现有一则对话,如表1所示。表1角色内容坐席31552号话务员为您服务客户我想查询一下话费坐席请问您想查询哪个月的话费客户上个月的坐席您上个月话费总共58元客户我想办理宽带坐席好的,为您推荐融合宽带客户好的,谢谢在标注之前,我们需要预先确定意图名称,以举例意图识别场景为例,有“查话费”、“办理宽带”两个意图。经人工标注后,结果如表2所示。表2角色内容块序号意图坐席31552号话务员为您服务1客户我想查询一下话费2查话费坐席请问您想查询哪个月的话费2客户上个月的2坐席您上个月话费总共58元3客户我想办理宽带4办理宽带坐席好的,为您推荐融合宽带5客户好的,谢谢6其中,连续几句话表达同一意图的对话被标记为同一块序号,对于在意图识别场景有意义的对话块,标注上对应意图名称。在构建模型之前需要去除标注语料中的停用词,如“请问您想查询哪个月的话费”去除停用词后为“查询哪月话费”。同样,根据停用词表得到其他对话去停用词后的结果,如表3所示。表3角色内容块序号意图坐席话务员服务1客户查询话费2查话费坐席查询哪月话费2客户上月2坐席上月话费总共58元3客户办理宽带4办理宽带坐席推荐融合宽带5客户6构建句向量模型,首先将语料转换为句向量模型训练格式,将表3内容列每行按字符拆分,存储到list中,得到句list,再将句list存储在整个对话的list中,转换完成后部分结果如下所示[[“话”,“务”,“员”,“服”,“务”],[“查”,“询”,“话”,“费”]]。设置sentence2vec算法的预设参数,句子嵌入向量空间的维度n=5和语料总共使用的次数epoch=500,将转换后结果采用sentence2vec算法进行句向量模型训练,将训练好的句向量模型存储到磁盘上。构建bilstm-crf模型,首先将语料转换为bilstm-crf模型训练格式。规定块标签为[b,i,e,o]。其中,b表示块开始位置,i表示块中位置,e表示块结束位置,o表示其他位置。每句话采用句向量模型转为句向量。将表3转换成模型训练格式,如表4所示。表4设置bilstm-crf模型预设参数,模型隐藏层大小hidden_size=128、随机失活率dropout=0.5、语料总共使用的次数epoch=150、每批次大小batch_size=20。将转换后的结果采用bilstm-crf进行模型训练,将训练好的bilstm-crf模型存储到磁盘上。构建starspace模型,首先将语料转换为starspace模型训练格式。将同一对话块的句子进行拼接,并和对应的意图组成key-value进行存储。将表3转换成模型训练格式,结果如下{“查询话费查询哪月话费上月”:“查话费”,“办理宽带”:“办理宽带”}。设置starspace模型预设参数,对话嵌入粒度=“char”、模型隐藏层大小hidden_size=[128,256]、语料总共使用的次数epoch=300、每批次大小batch_size=20。将转换后的结果采用starspace进行模型训练,将训练好的starspace模型存储到磁盘上。为叙述方便,意图识别对话数据仍然使用表1,实际中,对话数据和构建模型数据不相同。预先设定意图分类置信度阈值c=0.9。假设意图识别流程已经处理完对话数据前3句,开始处理第4句。算法获取第4句对话“上个月的”,根据停用词表去除停用词后为“上月”。然后采用句向量模型将对话转为句向量[0.61,-0.23,0.93,0.43,0.32],存储到对话列表中,此时对话列表如表5所示。表5角色内容句向量坐席话务员服务[0.32,0.56,0.12,-0.64,0.88]客户查询话费[0.11,0.87,0.33,0.45,0.91]坐席查询哪月话费[-0.22,1.03,0.56.0.76,0.02]客户上月[0.61,-0.23,0.93,0.43,0.32]将表5句向量组成的list使用bilstm-crf模型进行对话分块,结果为[o,b,i,e]。算法发现分块结果末端为一个对话块,所以将对话块中的句子进行拼接,结果为“查询话费查询哪月话费上月”。若此阶段算法没有发现分块结果末端为一个对话块,则获取下一句对话数据,开始下一轮意图识别。得到拼接完成的对话后,使用starspace模型进行意图分类,得到分类结果。其中,包含意图名称和意图置信度{“name”:“查话费”,“confidence”:0.91672}。根据分类结果发现意图分类置信度0.91672大于预先设定的意图分类置信度阈值c=0.9,算法认为意图分类结果是准确的,于是输出此意图。若此阶段意图分类置信度小于预先设定的意图分类置信度阈值c,则认为该对话块不足以形成一个意图输出。同样的,对话数据中的剩余对话都按照上述流程进行意图识别。若对话数据被全部处理完,则算法结束。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1