一种数据挖掘处理系统的制作方法
本发明涉及大数据技术领域,尤其是一种数据挖掘处理系统。
背景技术:
数据挖掘是指在海量的数据中检索到有价值数据信息的过程。由于待处理数据量庞大,如何降低数据挖掘过程的运算量,提高处理效率成为了这一领域研究的重点。
技术实现要素:
本发明要解决的技术问题是提供一种数据挖掘处理系统,能够解决现有技术的不足,提高了数据处理的效率。
为解决上述技术问题,本发明所采取的技术方案如下。
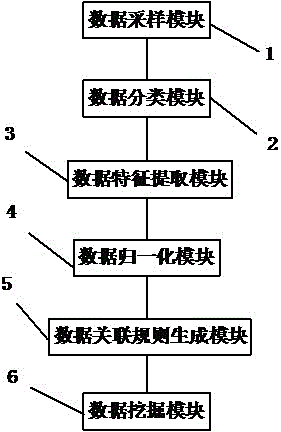
一种数据挖掘处理系统,包括,
数据采样模块,用于对待处理的数据进行采样;
数据分类模块,根据采样结果对数据进行分类处理;
数据特征提取模块,用于对每一类数据进行特征矩阵提取;
数据归一化模块,用于对每一类数据进行归一化处理;
数据关联规则生成模块,用于建立不同类数据之间的关联规则;
数据挖掘模块,用于挖掘有效数据。
一种上述的数据挖掘处理系统的处理方法,包括以下步骤:
a、数据采样模块对待处理的数据进行采样;
b、根据采样结果,数据分类模块对数据进行分类处理;
c、数据特征提取模块对每一类数据进行特征矩阵提取;
d、数据归一化模块对每一类数据进行归一化处理;
e、数据关联规则生成模块建立不同类数据之间的关联规则;
f、数据挖掘模块对有效数据进行挖掘。
作为优选,步骤b中,对数据进行分类包括以下步骤,
b1、根据采样结果,确定数据类别;
b2、提取每一个数据类别的特征量,作为第一特征量;
b3、使用第一特征量对待处理数据进行遍历,对数据进行分类。
作为优选,步骤c中,特征矩阵提取包括以下步骤,
c1、对同一类数据以第一特征量为初始量进行特征迭代处理;
c2、对特征迭代过程出现的新的特征量进行记录,作为第二特征量;
c3、将第一特征量作为特征矩阵的第一列元素,同类数据的第一特征量和第二特征量位于特征矩阵的同一行。
作为优选,步骤d中,对数据进行归一化处理包括以下步骤,
d1、通过变换矩阵对特征矩阵进行处理,得到归一化矩阵;变换矩阵每一行有且只有一个非零元素,所述非零元素为每一类数据中第一特征量和第二特征量的最大特征权重值;
d2、使用归一化矩阵对数据进行归一化处理。
作为优选,步骤e中,不同类数据之间的关联规则包括强关联规则和弱关联规则,强关联规则为关联映射唯一确定的关联规则,弱关联规则包括一组关联映射集。
作为优选,步骤f中,首先使用弱关联规则对有效数据进行挖掘,然后使用强关联规则对挖掘结果进行二次挖掘,根据二次挖掘结果的准确率和数据偏差对弱关联规则的关联映射集进行更新。
采用上述技术方案所带来的有益效果在于:本发明通过设计专门的特征矩阵,加强其与数据分类的关联。然后通过特征矩阵建立归一化矩阵进行数据归一化处理,降低了数据归一化过程中数据特征的损失率。在最后挖掘过程中,本发明开创性的引入了强弱两组关联规则,不仅提高了数据比对速度,而且实现了数据挖掘过程的自适应更新。
附图说明
图1是本发明一个具体实施方式的结构图。
图中:1、数据采样模块;2、数据分类模块;3、数据特征提取模块;4、数据归一化模块;5、数据关联规则生成模块;6、数据挖掘模块。
具体实施方式
参照图1,本发明一个具体实施方式包括,
一种数据挖掘处理系统,包括,
数据采样模块1,用于对待处理的数据进行采样;
数据分类模块2,根据采样结果对数据进行分类处理;
数据特征提取模块3,用于对每一类数据进行特征矩阵提取;
数据归一化模块4,用于对每一类数据进行归一化处理;
数据关联规则生成模块5,用于建立不同类数据之间的关联规则;
数据挖掘模块6,用于挖掘有效数据。
一种上述的数据挖掘处理系统的处理方法,包括以下步骤:
a、数据采样模块1对待处理的数据进行采样;
b、根据采样结果,数据分类模块2对数据进行分类处理;
c、数据特征提取模块3对每一类数据进行特征矩阵提取;
d、数据归一化模块4对每一类数据进行归一化处理;
e、数据关联规则生成模块5建立不同类数据之间的关联规则;
f、数据挖掘模块6对有效数据进行挖掘。
步骤b中,对数据进行分类包括以下步骤,
b1、根据采样结果,确定数据类别;
b2、提取每一个数据类别的特征量,作为第一特征量;
b3、使用第一特征量对待处理数据进行遍历,对数据进行分类。
步骤c中,特征矩阵提取包括以下步骤,
c1、对同一类数据以第一特征量为初始量进行特征迭代处理;
c2、对特征迭代过程出现的新的特征量进行记录,作为第二特征量;
c3、将第一特征量作为特征矩阵的第一列元素,同类数据的第一特征量和第二特征量位于特征矩阵的同一行。
步骤d中,对数据进行归一化处理包括以下步骤,
d1、通过变换矩阵对特征矩阵进行处理,得到归一化矩阵;变换矩阵每一行有且只有一个非零元素,所述非零元素为每一类数据中第一特征量和第二特征量的最大特征权重值;
d2、使用归一化矩阵对数据进行归一化处理。
步骤e中,不同类数据之间的关联规则包括强关联规则和弱关联规则,强关联规则为关联映射唯一确定的关联规则,弱关联规则包括一组关联映射集。
步骤f中,首先使用弱关联规则对有效数据进行挖掘,然后使用强关联规则对挖掘结果进行二次挖掘,根据二次挖掘结果的准确率和数据偏差对弱关联规则的关联映射集进行更新。
在本发明的描述中,需要理解的是,术语“纵向”、“横向”、“上”、“下”、“前”、“后”、“左”、“右”、“竖直”、“水平”、“顶”、“底”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
技术特征:
技术总结
本发明公开了一种数据挖掘处理系统,包括数据采样模块,用于对待处理的数据进行采样;数据分类模块,根据采样结果对数据进行分类处理;数据特征提取模块,用于对每一类数据进行特征矩阵提取;数据归一化模块,用于对每一类数据进行归一化处理;数据关联规则生成模块,用于建立不同类数据之间的关联规则;数据挖掘模块,用于挖掘有效数据。本发明能够改进现有技术的不足,提高了数据处理的效率。
技术研发人员:宋顶利;张昕;周建新
受保护的技术使用者:华北理工大学
技术研发日:2019.07.07
技术公布日:2019.10.15
- 还没有人留言评论。精彩留言会获得点赞!