一种数据驱动最小二乘预测的三角网格压缩方法与流程
本发明涉及三角网格压缩方法,特别是一种数据驱动的最小二乘预测方法,实现三角网格的更高且稳定的压缩率。
背景技术:
三角网格压缩是计算机图形学与数字几何处理领域的一个经典问题,并且在大规模三维模型存储、基于网络的三维图形绘制等应用中具有重要的作用。三角网格模型需要存储两类主要信息:拓扑信息和几何信息。相应的分为拓扑压缩和几何压缩,其中拓扑压缩的压缩率接近于极限值,而几何压缩则大多在某种拓扑压缩策略基础之上进行,旨在有效提高几何数据压缩的效率。其中关键的挑战在于:在压缩的过程中,如何更加精准地根据已编码的顶点位置对将要编码的顶点位置进行预测,预测越精准、需要的矫正量越小,那么进行熵编码能够得到的压缩率更高。
目前大多数的研究工作试图构造出广泛适用的函数来预测编码顶点坐标,其一般具有如下特点:一)预测模板选取为待编码顶点的小邻域;二)预测函数与模型数据本身无关,往往限定为显式构造函数。虽然它们的计算效率较高,但也较大程度上限制了其压缩率。
技术实现要素:
本发明的目的在于针对现有技术的不足,提供一种数据驱动最小二乘预测的三角网格压缩方法。
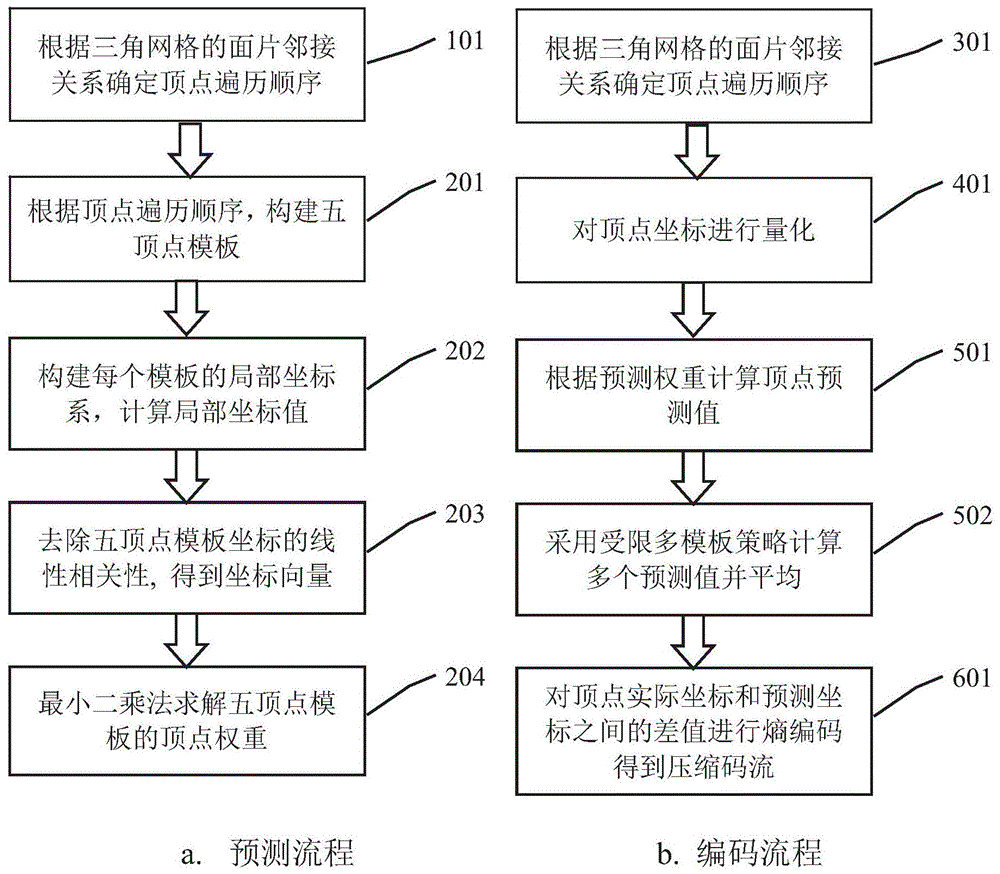
本发明的目的是通过以下技术方案来实现的:一种数据驱动最小二乘预测的三角网格压缩方法,包括预测模型生成和三角网格编码两部分。
预测模型生成部分包括:
101,对三角网格进行拓扑压缩,并确定几何压缩时的顶点遍历顺序。
201,按照遍历顺序,对每个顶点x,选取它的5个已遍历的邻域点作为五顶点预测模板,这5个点分别为x顶点的一条相对边的两个顶点b和c;与边bc相对的顶点a;与边ab相对的顶点p以及与边ac相对的顶点q。
202,为每个五顶点预测模板建立局部坐标系,并计算{a,b,c,p,q}在局部坐标系下的坐标{a′,b′,c′,p′,q′};设置局部坐标系的原点为(a+b+c)/3,坐标轴为[u,v,w],其中u方向沿着b-c方向,w沿着δabc的法向方向,v方向则由其他两个方向叉乘得到。
203,去除局部坐标中线性相关部分,得到坐标向量f,f包括平移标量t和9个坐标b′u,c′u,c′v,p′u,p′v,p′w,q′u,q′v,q′w。
204,构造预测方程并用最小二乘法求解预测器的权重
其中x′i为局部坐标系下第i个顶点坐标的实际值,
其中
三角网格编码部分包括:
301,对三角网格进行拓扑压缩,并确定几何压缩时的顶点遍历顺序。
401,对三角网格的几何数据进行量化。
501,使用预测训练中得到的权重来预测当前顶点的局部坐标系坐标
601,对遍历所有顶点记录的几何坐标值以及差值序列构成的数据流进行熵编码得到压缩码流。
进一步地,所述步骤101中,拓扑压缩采用edgebreaker方法压缩拓扑信息,建立顶点的生成树,确定顶点遍历顺序。
进一步地,所述步骤203具体为:
局部坐标系表示的五个顶点坐标的部分分量存在线性相关性,有如下关系:
即a′在u,v,w方向的分量a′u,a′v,a′w,b′在v,w方向的分量b′v,b′w,以及c,在w方向的分量c′w实际上是冗余的,因此直接将它们从线性系统中消掉,只保留其余的变量:b′u,c′u,c′v,p′u,p′v,p′w,q′u,q′v,q′w;
于是,上述9个坐标以及平移标量t组织成一个10维向量
进一步地,所述步骤401中,量化方法采用可变长量化或者定长量化,量化位数取值8-14位。
进一步地,所述步骤501具体如下:
按照步骤301确定的遍历顺序,对每个顶点x,选取它的5个已遍历的邻域点{a,b,c,p,q}作为五顶点预测模板,如果已遍历的顶点不足以构成符合条件的模板,优选使用平行四边形预测模板记录预测坐标与实际坐标之间的差值,如果己遍历顶点无法构成平行四边形预测模板,则直接记录x的坐标值。
对于五顶点预测模板,计算预测坐标的步骤如下:
以步骤202中描述的局部坐标系计算x的五顶点预测模板中每个顶点的局部坐标系坐标{a′,b′,c′,p′,q′)和x的局部坐标值x′。
以步骤203方法得到该顶点的线性无关坐标向量f,并使用步骤204中计算的权重
进一步地,为了进一步提高预测精度,所述步骤501中,
选用多个可用的预测模板,包括五顶点预测模板和平行四边形预测模板,利用其预测结果的线性组合获得最优预测值
进一步地,每个预测顶点最多采用4个相邻的模板,从而保证每个预测顶点的权重值序列不超过4个比特。
进一步地,所述步骤601中,采用霍夫曼编码、算术编码等无损熵编码。
本发明的有益效果是:本发明提供的数据驱动受限多模板最小二乘预测的三角网格压缩方法,深入利用了三角网格模型上邻近三角形之间的相关性,充分利用网格局部邻域信息特征,有效降低了坐标预测的误差,从而提高了网格压缩的编码压缩率,能够获得更高且稳定的压缩率,尤其是在光滑模型上压缩效果更为显著。
附图说明
图1是本发明一个实施例中的方法流程示意图;
图2是本发明设计的五顶点预测模板示意图;
图3是本发明采用的受限多模板的策略示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步详细说明,以使本发明的优点和特征能更容易被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
请参阅图1。图1是本发明面向三角网格压缩一较佳实施例的流程示意图。
本发明提供了一种数据驱动的基于最小二乘预测的三角网格压缩方法,包括预测模型生成和三角网格编码两部分。
预测模型生成的步骤包括:
101,对三角网格进行拓扑压缩,并确定几何压缩时的顶点遍历顺序。优选地,拓扑压缩采用edgebreaker方法压缩拓扑信息,建立顶点的生成树,确定顶点遍历顺序。可采用深度优先方法对生成树进行遍历。
201,按照步骤101确定的遍历顺序,对每个顶点x,选取它的5个已遍历的邻域点作为预测模板。选取的五顶点预测模板如附图2所示,这5个点分别为x顶点的一条相对边的两个顶点b和c;与边bc相对的顶点a;与边ab相对的顶点p以及与边ac相对的顶点q。
202,为保证刚体变换不变性,为每个五顶点预测模板建立局部坐标系,并计算{a,b,c,p,q}在局部坐标系下的坐标{a′,b′,c′,p′,q′}。设置局部坐标系的原点为(a+b+c)/3,坐标轴为[u,v,w],其中u方向沿着b-c方向,w沿着δabc的法向方向,v方向则由其他两个方向叉乘得到(此处注意构造局部坐标系要求δabc必须是未退化的三角形)。
203,去除局部坐标中线性相关部分,得到坐标向量f;局部坐标系表示的五个顶点坐标的部分分量存在线性相关性,有如下关系:
即a′在u,v,w方向的分量a′u,a′v,a′w,b在v,w方向的分量b′v,b′w,以及c′在w方向的分量c′w实际上是冗余的,因此可以直接将它们从线性系统中消掉,而只保留其余的变量:b′u,c′u,c′v,p′u,p′v,p′w,q′u,q′v,q′w;
于是,上述9个坐标以及平移标量t组织成一个10维向量
204,构造预测方程并用最小二乘法(least-squarepredictor,lsp)求解预测器的权重。预测方程按照下式:
其中x′i为局部坐标系下第i个顶点坐标的实际值,
其中
三角网格编码的步骤包括:
301,对三角网格进行拓扑压缩,并确定几何压缩时的顶点遍历顺序。优选地,拓扑压缩采用和训练过程的步骤101方法相同。
401,对三角网格的几何数据(顶点位置坐标)进行量化。优选地,量化方法可以为可变长量化或者定长量化,量化位数取值8-14位。
501-502步骤使用多模板策略预测顶点的坐标值,并且逐顶点记录几何坐标数据流。
501,使用预测训练中得到的权重来预测当前顶点的局部坐标系坐标,具体如下:
按照步骤301确定的遍历顺序,对每个顶点x,和步骤201类似,选取它的5个已遍历的邻域点{a,b,c,p,q}作为五顶点预测模板,如果已遍历的顶点不足以构成符合条件的模板,优选使用平行四边形预测模板记录预测坐标与实际坐标之间的差值,如果已遍历顶点无法构成平行四边形预测模板,则直接记录x的坐标值。
对于五顶点预测模板,计算预测坐标的步骤如下:
以步骤202中描述的局部坐标系计算x的五顶点预测模板中每个顶点的局部坐标系坐标{a′,b′,c′,p′,q′}以及x的局部坐标x′。
以步骤203方法得到该顶点的线性无关坐标向量f,并使用步骤204中计算的权重
为了保证编码和解码过程的可逆性,在编码时用于预测的{a,b,c,p,q}的值应该是解码后的坐标值,而不是原始模型的顶点坐标值。
502,利用受限多模板策略,进一步提高预测精度。选用多个可用的预测模板(可以是五顶点预测模板或者平行四边形预测模板),利用其预测结果的线性组合获得最优预测值
一个可能的多模板策略如附图3。如果记录预测顶点周围某个模板的预测值为
601,对遍历所有顶点记录的几何坐标值以及差值序列构成的数据流进行熵编码得到压缩码流,可采用如霍夫曼编码、算术编码等无损熵编码方法。
本发明提出一种五顶点预测模板,在局部坐标下进行构建,通过最小二乘法求解预测器的权重,取得了较好的效果。本领域一般技术人员根据本发明公开的内容,可以采用其它多种具体实施方案实施本发明。因此,凡是采用本发明的设计结构和思路,做一些简单的变化或更改的设计,都落入本发明保护范围。
- 还没有人留言评论。精彩留言会获得点赞!