基于图像语义分割识别非机动车异常行为的方法与流程
本发明涉及人工智能与智慧交通领域,特别是一种基于图像语义分割识别非机动车异常行为的方法。
背景技术:
随着日常交通网络的多元化、复杂化,非机动车(自行车、电动车等)在交通道路上扮演着重要的角色。部分非机动车驾驶员交通规则意识淡薄,违规事故频发,所以建立针对非机动车异常行为的智慧交通监测系统的重要性与日俱增。而相比于机动车,非机动车具有体型小、无牌照、不易识别等特点。此外,由于非机动车体积小较为灵活,非机动车驾驶员更容易做出闯红灯、逆行、抢机动车道等违规行为。因此,识别和判断非机动车的异常行为就成为了一项新的技术挑战。
随着人工智能领域深度学习技术的发展和gpu运算能力的几何级扩张,利用大规模的数据来训练神经网络模型成为了一种可能,这无疑为解决非机动车异常行为的识别和判断问题提供了可靠的技术支撑。
非机动车异常行为的识别难点在于如何将非机动车在其所处的复杂背景中剖离出来并判断其行为状态,而传统的识别方法均为常规识别非机动车的类型和在交通道路上的坐标,并没有对非机动车的异常行为做出判断。
技术实现要素:
为解决现有技术中存在的问题,本发明的目的是提供一种基于图像语义分割识别非机动车异常行为的方法,本发明具有识别可靠性高的优点。
为实现上述目的,本发明采用的技术方案是:一种基于图像语义分割识别非机动车异常行为的方法,包括以下步骤:
s1、获取非机动车图像;
s2、将获取的非机动车图像输入图像语义分割模型中,得到仅包含非机动车以及交通要素的图像;
s3、训练状态分类模型,利用训练好的状态分类模型对图像语义分割模型分割后的图像进行分类,并判断非机动车行为是否正常。
作为一种优选的实施方式,所述图像语义分割模型利用卷积层和池化层来抓取图像特征,再通过反卷积层将抓取的图像特征呈现出来,每个卷积层后面添加relu函数来增强图像语义分割模型的拟合能力,通过dicecoefficient损失函数来表示结果与真实值的差距。
作为另一种优选的实施方式,步骤s2中,图像语义分割模型对非机动车图像进行分割具体包括以下步骤:
s21、准备训练集与标签,训练集为真实的交通图像,标签为重点标出非机动车、道路、交通指示灯、斑马线要素的图片;
s22、将训练集与标签输入图像语义分割模型进行训练,获得一个图像语义分割器;
s23、将获取的非机动车图像输入图像语义分割器获得所需要的分割结果,即仅包含非机动车以及交通要素的图像。
作为另一种优选的实施方式,所述状态分类模型的训练过程如下:
数据预处理:对非机动车图像数据集中的样本图像进行预处理,使所有输入状态分类模型的图像大小保持一致,并用one-hot形式为样本图像中的正常行为图像和异常行为图像分别添加不同的标签label,作为状态分类模型的输入层;
搭建状态分类模型:包括与输入层依次连接的隐藏层和全连接层,所述隐藏层包括依次连接的第一卷积层、第一最大池化层、第二卷积层和第二最大池化层;
训练状态分类模型:将包含非机动车的图像分为两类,分别为非机动车正常行为图像和异常行为图像,并通过输入层统一图像大小和ont-hot形式的贴标签,然后将分类后的图像数据分为训练集和验证集输入状态分类模型进行训练,卷积层中通过卷积核对图像映射获得图像特征,最大池化层用于对图像特征进行选择,全连接层通过对图像特征做加权求和,再使用softmax分类器进行分类,得到非机动车行为是否异常的检测结果,训练过程中通过bp反向传播算法来更新卷积核矩阵。
作为另一种优选的实施方式,对样本图像进行预处理具体包括图像缩放、图像旋转和图像裁剪。
本发明的有益效果是:非机动车异常行为的识别难点在于如何将非机动车在其所处的复杂背景中剖离出来并判断其行为状态,而本发明通过图像语义分割将非机动车和交通要素(道路、交通指示灯、斑马线等)从背景中分割出来,再将其输入状态分类模型判断非机动车的行为是否异常,经过图像语义分割后的图像中仅包括非机动车以及判断其行为异常与否的要素,所以使用图像语义分割后的图像来判断非机动车的状态可以有效过滤图像背景中无用的干扰信息,增强识别的可靠性。
附图说明
图1为本发明实施例的流程图;
图2为本发明实施例中图像语义分割模型的结构示意图;
图3为本发明实施例中状态分类模型的结构示意图;
图4为本发明实施例中状态分类模型的卷积与池化的操作示意图;
图5为本发明实施例中状态分类模型训练流程图。
具体实施方式
下面结合附图对本发明的实施例进行详细说明。
实施例:
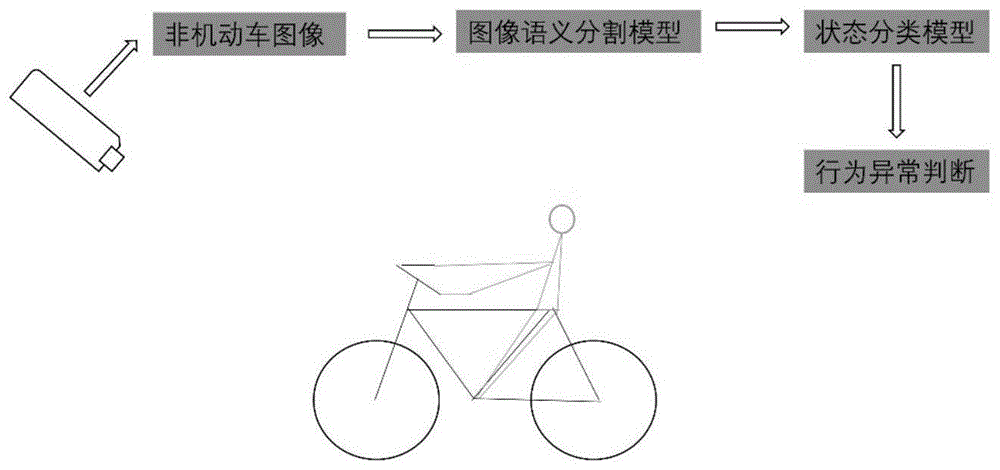
本实施例主要包括图像语义分割和行为分类两个方面,如图1所示,一种基于图像语义分割识别非机动车异常行为的方法,包括以下步骤:
s1、获取非机动车图像;
s2、将获取的非机动车图像输入图像语义分割模型中,得到仅包含非机动车以及交通要素的图像;
s3、训练状态分类模型,利用训练好的状态分类模型对图像语义分割模型分割后的图像进行分类,并判断非机动车行为是否正常。
图像语义分割:
为了对非机动车以及道路、交通灯等要素进行图像语义分割,本实施例提出了一种针对性的图像语义分割模型。由于一些交通要素比如路灯在图像中所占比例较小,所以卷积核的大小以及池化层的数量都必须适用于识别小面积的特征,因此本实施例的图像语义分割模型使用了3*3*3的卷积核,并且将池化层的数量设置为2,图像语义分割模型的结构示意图如图2所示。
图像语义分割模型利用卷积层和池化层来抓取图像特征,再通过反卷积层将抓取的特征呈现出来,每个卷积层后面添加relu函数来增强模型的拟合能力,通过dicecoefficient损失函数来表示结果与真实值的差距。
非机动车以及道路要素的图像语义分割步骤为:
准备训练集与标签,训练集为真实的交通图像,而标签为重点标出非机动车、道路、交通灯等要素的图片。
将训练集与标签输入图像语义分割模型进行训练,获得一个图像语义分割器。
将交通图像输入图像语义分割器获得所需要的分割结果,即仅包含非机动车以及交通要素的图像。
状态分类:
本实施例通过构建状态分类模型对图像语义分割后的图像进行分类,以判断非机动车行为是否正常,具体包括:
数据预处理:
为了扩大训练集规模和提高状态分类模型的泛化能力,本实施例通过数据增强的操作来增加样本数量,包括图像缩放,图像旋转和图像裁剪。这样的预处理也可以平衡非机动车正常行为图像和异常行为图像(正反面样本)的数量,避免某一类别识别准确率过低的问题。
为了统一图像的大小便于后续的深度学习,本实施例利用python中的pil库来调整图像尺寸,使得所有输入状态分类模型的图像大小保持一致。此外,用one-hot形式为样本图像添加标签label,比如正常行为图像为[1,0],而异常行为图像为[0,1]。
状态分类模型的搭建:
本实施例采用的状态分类模型包括两个卷积层、两个最大池化层和一个全连接层,状态分类模型的结构示意图如图3所示。
输入层负责统一图像大小和ont-hot贴标签的工作。卷积层中通过卷积核对图像的映射获得图像特征,最大池化层负责对显著特征的选择,卷积与池化操作示意如图4所示:
图4中输入的9*9矩阵代表一张图像,其中的数值代表每个像素点的灰度值。卷积操作中,卷积核按照从左到右从上到下的顺序分别与对应区域的像素矩阵进行点乘,获得卷积后的输出,即一个7*7的特征图。为了进一步获取特征图中的主要信息,对特征矩阵进行最大池化操作,即在特征矩阵取2*2区域内所有元素的最大值。值得注意的是,本实施例中所用图像的实际大小为256*256,图4仅用于解释原理,并不代表真实的图像尺寸与矩阵数值。卷积与池化都是通过线性运算构建的模型,网络逼近能力有限,为此本实施例调用非线性函数relu作为激励函数,增强状态分类模型的表达能力。全连接层在整个学习过程中起到分类的作用,通过对前面网络的特征做加权和,再使用softmax分类器进行分类,得到非机动车行为是否异常的检测结果。
本实施例具体使用keras搭建整个状态分类模型。keras是一个基于python的高层神经网络api,具有高度模块化,极简和可扩充特性,支持卷积、池化等模块的调用和实现。
状态分类模型的训练:
本实施例涉及的状态分类模型解决的是一个分类问题。首先将包含非机动车的图像分为两类,分别为非机动车正常行为图像和异常行为图像并贴上one-hot形式标签。然后将分类后数据中的80%作为训练集,20%作为验证集输入状态分类模型进行训练,通过bp反向传播算法来更新卷积核矩阵(权重矩阵),获得理想的分类模型。状态分类模型的训练需要在有相当计算能力的gpu上进行,状态分类模型的训练过程如图5所示。
以上所述实施例仅表达了本发明的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!