一种面向数据流的测试用例生成方法与流程
本发明涉及软件测试技术领域,尤其是一种面向数据流的测试用例生成方法。
背景技术:
随着软件开发技术的不断提升,软件产品的应用越来越广泛,其规模和复杂性逐渐增大,质量保证也面临着越来越大的挑战。在软件的质量保证体系中,测试是一项有效的技术,好的测试能够发现尽可能多的软件缺陷。
测试用例的设计是软件测试的核心工作,其一般根据测试需求遵循一定的测试准则来进行。很多研究基于路径覆盖(all-paths)准则进行测试用例的设计,通过检查软件中所有的执行路径来发现错误,而对于包含循环结构的软件而言,在基于all-paths准则的测试用例生成中,要计算出程序的所有路径是难以实现的。考虑软件的基本功能需求,即针对特定的输入可获得预期的输出,输出与输入之间的关联是通过一系列变量的定义和使用来实现的,数据流的正确性一定程度上也反映了软件控制流的正确性,因此保证软件的数据流正确性非常重要。
全使用(all-uses)数据流测试准则要求软件中每个变量的每个定义到该定义的每个使用都被测试覆盖,可有效地保证软件的数据流正确性。传统的方法可采用遗传算法进行测试用例的生成,其中基于合适的适应度函数来判断测试用例是否覆盖待测试目标。而大多方法中适应度函数的值需要通过插装程序的运行加以计算得出,对于大规模复杂的软件而言,该过程需要消耗较多的时间和资源。有研究引入神经网络来改善基于遗传算法的测试用例生成方法,该研究面向路径覆盖准则,对每条待测试路径构造一个神经网络以模拟计算测试用例对该路径的覆盖情况。鉴于数据流正确性的重要性,针对all-uses数据流测试准则,如何有效地且高效地生成测试用例是我们关注的问题。
技术实现要素:
本发明所要解决的技术问题在于,提供一种面向数据流的测试用例生成方法,能够有效地开展软件测试,保证软件的数据流正确性。
为解决上述技术问题,本发明提供一种面向数据流的测试用例生成方法,包括如下步骤:
(1)对待测程序进行数据流分析,获取程序中所有的定义-使用对;
(2)设计并训练bp神经网络,以模拟适应度函数;
(3)利用遗传算法生成覆盖所有定义-使用对的测试用例。
优选的,步骤(1)中,计算程序中所有定义-使用对的具体步骤为:
(11)对待测程序进行解析并构建相应的控制流图cfg;
(12)基于cfg进行数据流分析,采用深度优先遍历的方法遍历程序cfg,获得程序的所有路径,然后自底向上遍历每条可执行路径,获得程序中所有的定义-使用对。
优选的,步骤(2)中,构造bp神经网络的具体步骤为:
(21)选择合适的适应度函数,令x=(x1,x2,...xn)表示测试数据,du=(d,u,v)表示待测试的定义使用对(即变量v在节点d的定义值被节点u使用),评估x是否覆盖du的适应度函数如下所示:
其中dom(n)表示节点n的支配路径,即程序执行从入口结点到n必须经过的结点集;cdom(n)和udom(n)分别表示以x作为输入执行程序时,n的支配路径中被覆盖和没有被覆盖的节点集;fdom(n)表示以x作为输入执行程序时,n的支配路径中被覆盖超过1次的节点集;fdom(d∪u)=fdom(d)∪fdom(u);ft(x,du)≥1则表明x覆盖du;
(22)根据适应度函数设计神经网络的结构,包括输入层、隐藏层和输出层,其中输入层包括n+1个元素,表示由n个输入元素组成的被测程序的输入数据x=(x1,x2,...xn)和1个待测试的定义-使用对du=(d,u,v);输出层包含1个输出元素y,即适应度函数值ft(x,du);
(23)为神经网络的构造设计训练样本,随机生成一定数量的测试数据,针对每个待测试的定义-使用对,将测试数据作为输入运行插桩程序计算出相应的适应度函数值,从而得到所需的网络训练样本;
(24)利用样本训练网络,构造可以估算适应度函数计算的神经网络。
优选的,步骤(3)中,生成测试用例的具体步骤为:
(31)初始化测试用例集以及遗传算法相关参数;
(32)对测试用例集中的测试用例,使用训练好的神经网络估算其对待测试定义-使用对的适应值;
(33)基于适应值判断测试用例是否覆盖某定义-使用对,若是,则更新测试用例集以及待测试的定义-使用对集,将该测试用例加入测试用例集,并将被覆盖的定义-使用对从待测试的定义-使用对集中删除;否则转步骤(35);
(34)判断是否所有的定义-使用对都被覆盖,或遗传算法是否达到最大迭代,若是,则输出测试用例集,算法结束;否则,转步骤(35);
(35)对测试用例进行遗传操作,即选择、交叉和变异操作,得到新的测试用例,转步骤(32)。
本发明的有益效果为:面向all-uses数据流测试准则,基于控制流图计算java程序中所有的定义-使用对,设计神经网络的结构,用以模拟遗传算法中适应度函数的计算,以评估测试用例对定义-使用对的覆盖情况,基于遗传算子的操作生成覆盖所有定义-使用对的测试用例集;与传统方法相比,利用神经网络模拟适应度函数的计算,可以减少遗传算法中程序插桩运行的次数;通过神经网络结构的设计,优化了基于神经网络的测试用例生成方法流程,无需针对多个待测目标执行流程多次。
附图说明
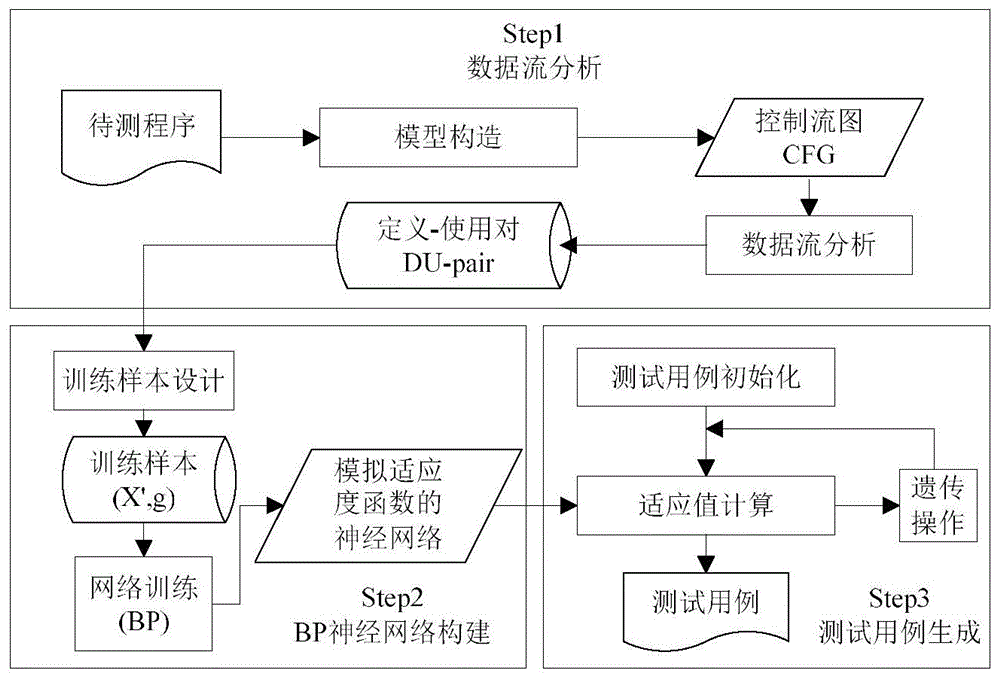
图1为本发明的方法流程示意图。
图2为本发明中遍历控制流图计算路径的流程示意图。
图3为本发明中神经网络结构的示意图。
图4为本发明中执行步骤(1)得到的三角形类型判断程序的部分控制流图。
具体实施方式
如图1所示,一种面向数据流准则的测试用例生成方法,包括如下步骤:
(1)对待测程序进行数据流分析,获取程序中所有的定义-使用对;
(2)设计并训练bp神经网络,以模拟适应度函数;
(3)利用遗传算法生成覆盖所有定义-使用对的测试用例。
步骤(1)中,计算程序中所有定义-使用对的具体步骤为:
(11)利用开源工具soot对待测程序进行解析并构建相应的控制流图cfg,其中的每个结点代表一个原子操作,并对cfg中的每个节点赋予唯一的编号,以便后续分析;
(12)基于cfg进行数据流分析。如图2所示,采用深度优先遍历的方法遍历程序cfg,获得程序的所有路径。首先定义两个栈ps和us分别存储cfg中的路径和节点,从控制流图的头节点开始遍历,以p为当前路径,n为当前节点,对当前节点n,将n添加到路径p,判断n是否存在后继节点,如果n只有一个后继节点,则将该后继节点作为当前节点n去遍历;如果n有多个后继节点,对每个后继节点m,将m压入栈us,复制当前路径p创建一条新的路径,并压入栈ps,分别从栈ps和us中弹出一个栈顶元素作为当前路径p和当前节点n;如果n没有后继节点,则表明当前路径遍历完,判断栈ps和us是否为空,是则路径计算结束,否则分别从栈ps和us中弹出一个栈顶元素作为当前路径p和当前节点n。针对计算出的每条路径,自底向上遍历路径中的节点,当遇到变量v的使用节点u,向上寻找距离最近的关于v的定义节点u,构造关于变量x的定义使用对(d,u,v),最终获得程序中所有的定义-使用对。
步骤(2)中,构造bp神经网络的具体步骤为:
(21)选择合适的适应度函数,令x=(x1,x2,...xn)表示测试数据,du=(d,u,v)表示待测试的定义使用对(即变量v在节点d的定义值被节点u使用),评估x是否覆盖du的适应度函数如下所示:
其中dom(n)表示节点n的支配路径,即程序执行从入口结点到n必须经过的结点集;
cdom(n)和udom(n)分别表示以x作为输入执行程序时,n的支配路径中被覆盖和没有被覆盖的节点集;fdom(n)表示以x作为输入执行程序时,n的支配路径中被覆盖超过1次的节点集;fdom(d∪u)=fdom(d)∪fdom(u)。ft(x,du)≥1则表明x覆盖du。
(22)根据适应度函数设计神经网络的结构,如图3所示,包括输入层、隐藏层和输出层,其中输入层包括n+1个元素,表示由n个输入元素组成的被测程序的输入数据x=(x1,x2,...xn)和1个待测试的定义-使用对du=(d,u,v);输出层包含1个输出元素y,即适应度函数值ft(x,du)。隐藏层设为一层,其中的神经元数量借鉴如下公式来确定:
其中,a表示输入层的神经元数量,b表示输出层的神经元数量。
(23)为神经网络的构造设计训练样本,随机生成一定数量的测试数据,针对每个待测试的定义-使用对,将测试数据作为输入运行插桩程序计算出相应的适应度函数值,从而得到所需的网络训练样本;
(24)利用样本训练网络,构造可以估算适应度函数计算的神经网络。网络的训练过程由信号的正向传播与误差的反向传播两个阶段组成,在传播的过程中,不断调整网络的权值,直到网络的真实输出与预期输出之间的误差低于规定的值,或者训练达到最大迭代次数。
步骤(3)中,生成测试用例的具体步骤为:
(31)初始化测试用例集和遗传算法相关参数。测试用例采用二进制编码方法进行描述,根据待测程序输入变量个数、变量类型以及变量的取值范围,随机产生一组编码串。
(32)对测试用例集中的测试用例,使用训练好的神经网络估算其对待测试定义-使用对的适应值;
(33)基于适应值判断测试用例是否覆盖某定义-使用对,若是,则更新测试用例集以及待测试的定义-使用对集,将该测试用例加入测试用例集,并将被覆盖的定义-使用对从待测试的定义-使用对集中删除;否则转步骤(35);
(34)判断是否所有的定义-使用对都被覆盖,即待测试的定义-使用对集是否为空,或遗传算法是否达到最大迭代,若是,则输出测试用例集,算法结束;否则,转步骤(35);
(35)对测试用例进行遗传操作,即选择、交叉和变异操作,得到新的测试用例,转步骤3.2。其中选择操作使用轮盘赌选择法,针对测试用例集,第i个测试用例被选中的概率pi如下所示:
其中,fi表示第i个测试用例的适应度函数值。交叉操作使用单点交叉法,先按照设定好的概率从测试用例集中选择两个要进行交叉操作的测试用例(a0,a1,…,an)和(b0,b1,…,bn),随机选择一个1和n之间的值m,生成(a0,a1,…,am-1,bm,bm+1,…,bn)和(b0,b1,…,bm+1,am+1,…,an)两个子代。变异操作使用二进制变异方法,先以设定好的概率从测试用例集中选取出要进行变异操作的测试用例(a0,a1,…,an),再随机选择一个1和n之间的值m,则将该编码串中的am的取值转换为不同值,从而生成一个新的测试用例编码串。
为了方便描述,我们利用面向数据流准则的测试用例生成方法为三角形类型判断的java程序生成测试用例,流程如下:
(1)使用soot开源包构造程序的控制流图,部分控制流图如图4所示,用深度优先遍历的方法遍历控制流图,获得程序的所有路径,然后自底向上遍历每条可执行路径,获得程序中所有的定义-使用对,部分定义-使用对如表1所示。利用控制流图中的变量与源程序变量的对应关系,最终得到待测试的定义-使用对如表2所示。
表1部分定义-使用对
(2)设计并训练bp神经网络,以模拟适应度函数。根据适应度函数,神经网络的结构中,输入层有4个节点,对应3个输入变量和1个待覆盖的定义-使用对,输出层有1个节点,对应适应度函数值,根据计算隐藏层有5个节点。然后设计网络的训练样本,根据输入层、隐藏层和输出层的节点数,得出网络连接权重的数量为25,训练样本数取网络连接权重总数量的10倍为250。样本包含测试用例、定义-使用对和相应的适应度函数值。最后将训练样本作为输入,将神经网络的最大迭代次数设为100,使用matlab工具训练神经网络。
表2待测试定义-使用对
(3)利用遗传算法生成覆盖所有定义-使用对的测试用例。首先设置遗传算法的参数,最大迭代次数设为2000,种群规模设为20,交叉概率设为0.75,变异概率设为0.1。然后在matlab中,根据设置的参数,遗传算法调用构造好的神经网络估算测试用例的适应度函数值,通过不断进化迭代,得到覆盖该程序所有定义-使用对的测试用例,部分测试用例如表3所示。
表3部分测试用例
- 还没有人留言评论。精彩留言会获得点赞!