一种基于目标识别区域截取的车辆颜色识别方法与流程
本发明涉及一种基于目标识别区域截取的车辆颜色识别方法,属于车辆颜色识别技术领域。
背景技术:
车辆颜色识别,是指通过监控录像中截取的图片,识别出车辆的颜色信息的过程。
车辆颜色是城市交通中的一种重要信息。目前有许多通过识别车牌来识别车辆信息的方法,但是,由于车牌区域小,在图片质量较差的情况下很难准确识别。而车辆颜色是一种对图像质量敏感性不强的车辆信息,判断车辆颜色相对而言更具有普遍性和可操作性。基于以上优点,车辆颜色识别在犯罪追踪、事故分析等领域中有广泛的应用。
目前车辆颜色识别领域还是存在着很大的挑战和难度,主要原因包括以下几个方面:
(1)识别车辆颜色时,常会受背景环境、车窗、轮胎等一系列无效区域的影响,导致识别准确度降低;
(2)同一个相机在不同角度,不同光照,不同天气的情况下,对同一辆车的成像可能会出现偏差,相机成像效果会影响识别的准确性。因此,提高车辆识别模型的泛化能力和准确性显得尤为重要。
现有技术中,经典的实现方法为基于窗去除掩码的车辆颜色识别,其具体步骤为:
1、获取待测车辆图像,对所述待测车辆图像进行图像掩码处理,得到对应的带有掩码的车脸图像;
2、对上述带有掩码的车脸图像进行截取,得到颜色检测区域;
3、将上述颜色检测区域通过单一的rgb或hsv颜色空间模型进行颜色像素统计,按照事先划分好的颜色区段,得到图片各像素点的所属颜色统计分布;
4、通过计算颜色区段对应的像素点的个数,确定车辆颜色。
由此可见,基于窗去除掩码的车辆颜色识别方法中,需要对图片进行掩码处理,增加了模型的复杂度;同时,该方法中仅用单一的rgb或hsv颜色空间模型进行颜色像素统计、预测车辆颜色,相较于用多种模型综合考察的方法来说,准确度和泛化性有所下降。
中国发明专利cn109508720a公开了“一种车辆颜色识别方法及装置”,该方法包括:获取待识别车辆图像,并对所述待识别车辆图像进行分割处理得到对应的待处理图像;对所述待处理图像中的车窗区域进行定位,并对所述车窗区域进行掩码处理,得到待识别图像;将所述待识别图像进行颜色识别判断,输出车辆颜色。该专利使用基于窗去除掩码的车辆颜色识别方法,即通过对车窗区域掩码来得到识别目标区域,处理复杂度较大。
技术实现要素:
针对现有技术的不足,本发明提供一种方法简单、误检率低、泛化能力强的基于目标识别区域截取的车辆颜色识别方法。
本发明采用以下技术方案:
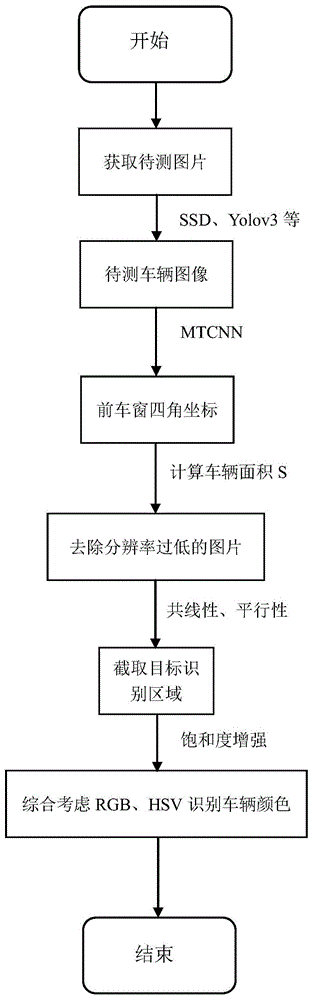
一种基于目标识别区域截取的车辆颜色识别方法,包括以下步骤:
1)获取包含待测车辆的图片;
2)对待测图片进行目标检测,得到待测车辆的图像;
3)对待测车辆提取车窗区域信息,得到前车窗四角的坐标值;
4)去除部分分辨率过低的检测图片;
5)利用车窗、车引擎盖边界的共线性和平行性,截取车辆引擎盖区域作为图片的目标识别区域;
6)对提取的车辆引擎盖区域图像进行饱和度增强处理;
7)用rgb和hsv两套颜色识别模型,对饱和度增强后的车引擎盖图像进行颜色识别,输出最终识别结果。
本发明解决了传统车辆颜色识别中,背景、车窗等干扰区域对车身颜色识别产生影响的问题,提升了车辆颜色识别的准确性和鲁棒性。
优选的,所述步骤1)中,获取包含待测车辆的图片,即准备好待测图片,待测图片应为包含多辆车辆的图片,多辆车辆的图片优选为包括不同场景、不同角度下的图片,以使识别算法具备更强的鲁棒性和泛化能力。
优选的,所述步骤2)中,对待测图片进行目标检测时检测方法包括但不限于yolov3(youonlylookonce)目标检测网络或ssd(singleshotmultiboxdetector)目标检测算法等,通过上述现有方法可以检测出待测图片中目标车辆,得到待测目标车辆的图像。
优选的,所述步骤3)中,利用现有的mtcnn网络(multi-taskconvolutionalnetwork)提取前车窗四角坐标,所述mtcnn网络分为三部分,按执行顺序分别为pnet、rnet和onet。
优选的,将步骤2)得到的待测车辆的图像送入pnet,pnet输出多个尺寸为m*n(m、n为像素点的个数)的方框的坐标回归值,每个方框中均为pnet判断可能为车窗的区域,得到可能为车窗区域的方框集合;
截取pnet输出的方框在原图中的对应区域,将所有截取得到的图像合并到一个四维矩阵中,作为rnet的输入,rnet对pnet输出的方框实现进一步筛选,更新方框坐标,使得其精度更高;
将rnet输出的更精确的方框作为onet的输入,onet输出更为精确的方框坐标,并返回车窗四个角的坐标a(a1,b1)、b(a2,b2)、c(a3,b3)和d(a4,b4)。
优选的,所述步骤4)中,根据步骤3)中输出的前车窗四角的坐标计算出车窗面积s,将车窗面积s小于人为设定阈值k的图片删除,即去除部分分辨率过低的图片,阈值k可根据实际需要人为设定,该步骤可以有效去除距离过远的车辆图片,其中,面积s的计算方法为两向量的叉乘值|ab×ad|。
进一步优选的,所述步骤5)中,考虑到在不同场景、不同角度下,车窗和车引擎盖的相对位置不会发生改变,车窗的边界线和车引擎盖的边界线始终满足共线性、平行性,平行四边形abcd为车窗区域,若平行四边形cdef为车辆引擎盖区域,即始终满足a、d、e共线,b、c、f共线,ab∥cd∥ef;
定义ratio,如公式(1)所示,dy为过a点所在的cd垂线段的长度,经查阅多种品牌与型号的车辆车窗参数,可确定在距离不远的前提下,通过公式(1)计算得到,ratio为1.9~2.1之间,实验证明,在不同型号、以及拍照角度不同的情况下,其ratio值基本不变,在本发明中,ratio的值取为2,需要说明的是,在步骤(4)中,已将距离过远的车辆图片去除,故取ratio=2是较为合理的;
通过公式(2)得到:
在公式(2)中,系数1/3为根据大数据试验得到的经验值,由公式(2)计算得到de线段的长度,可确定e点坐标(a5、b5);
确定e点坐标后,可通过dc∥ef和b、c、f共线确定f点的坐标(a6、b6),此处e点坐标为[a4-2(a1-a4)/3,b4-2(b1-b4)/3],f点坐标为[a3-2(a2-a3)/3,b3-2(b2-b3)/3];
e、f两点坐标确定后,即可截取平行四边形dcfe作为车引擎盖区域;
车引擎盖区域为目标识别区域,在后续颜色识别过程中仅识别该目标识别区域的颜色。
进一步优选的,所述步骤6)中,对车辆引擎盖区域图像进行饱和度增强处理,目前已有很多算法可以实现,包括但不限于采用vibrance自然饱和度算法,此算法为现有算法,其具体的增强处理过程此处不再赘述。
进一步优选的,所述步骤7)中,事先将hsv颜色识别模型和rgb颜色识别模型分别划分为q个区域,分别表示q个颜色,划分规则可以人为设定,每个区域的区间大小所需颜色的细致程度进行设定,其中,rgb、hsv是两种衡量标准不同的颜色识别模型,在rgb颜色识别模型中,颜色的衡量参数为:r(red:红)、g(green:绿)、b(blue:蓝)分别代表可见光谱中的三种基本颜色,该三种基本颜色按亮度的不同均可分为256个等级,三种颜色进行不同程度的叠加得到各种颜色;
在hsv颜色识别模型中,颜色的衡量参数为:色调h,饱和度s,明度v,不同色调、饱和度、明度的组合,可以形成各种颜色;
采用逐点像素比较的方式确定目标区域颜色,即将步骤7)所得经饱和度增强处理的车辆引擎盖区域图像中每一个像素点在hsv颜色识别模型和rgb颜色识别模型的数值与已预先定义的q种颜色在hsv,rbg色彩空间数值范围进行比较,最终将每一个像素判定为上述颜色的一种;
若rgb颜色识别模型中属于某一颜色的像素点个数为ai,hsv颜色识别模型中属于某一颜色的像素点个数为bi,则属于该颜色的像素点个数平均值为(ai+bi)/2,像素点个数平均值(ai+bi)/2最多的颜色,即为最终识别颜色,该最终识别颜色即为输出值。
本发明未详尽之处,均可采用现有技术进行。
本发明的有益效果为:
目前车辆颜色识别领域普遍使用基于窗去除掩码的车辆颜色识别方法,即通过对车窗区域掩码来得到识别目标区域,进而用单一的rgb或hsv颜色识别模型进行颜色识别,同时,该方法中仅用单一的rgb或hsv颜色空间模型进行颜色像素统计、预测车辆颜色,相较于用多种模型综合考察的方法来说,准确度和泛化性有所下降。本发明基于目标识别区域截取的车辆颜色识别方法能更快捷、直接的获取目标识别区域,整个过程无需掩码,而是直接通过车窗和车引擎盖边界的共线性和平行性,经过简单的计算,直接截取得车引擎盖区域作为目标识别区域;同时,本发明采用rgb、hsv两套颜色识别模型来识别车辆颜色,比用单一的rgb或hsv颜色空间模型识别有更高的准确度,因此基于目标识别区域截取的车辆颜色识别方法具有更强的泛化能力和更高的准确性。
本发明解决了传统车辆颜色识别中,背景、车窗等干扰区域对车身颜色识别产生影响的问题,提升了车辆颜色识别的准确性和鲁棒性。
附图说明
图1为本发明的基于目标识别区域截取的车辆颜色识别方法的流程示意图;
图2为车窗四角的坐标示意图;
图3为车窗与引擎盖相对位置示意图;
图4为车引擎盖区域确定方法示意图。
具体实施方式:
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述,但不仅限于此,本发明未详尽说明的,均按本领域常规技术。
实施例:
一种基于目标识别区域截取的车辆颜色识别方法,如图1所示,包括以下步骤:
1)获取包含待测车辆的图片;
获取包含待测车辆的图片,即准备好待测图片,待测图片应为包含多辆车辆的图片,多辆车辆的图片优选为包括不同场景、不同角度下的图片,以使识别算法具备更强的鲁棒性和泛化能力。
2)对待测图片进行目标检测,得到待测车辆的图像;
对待测图片进行目标检测时检测方法本实施例中采用ssd(singleshotmultiboxdetector)目标检测算法,检测出待测图片中目标车辆,得到待测目标车辆的图像。
3)对待测车辆提取车窗区域信息,得到前车窗四角的坐标值;
利用现有的mtcnn网络(multi-taskconvolutionalnetwork)提取前车窗四角坐标,所述mtcnn网络分为三部分,按执行顺序分别为pnet、rnet和one;
将步骤2)得到的待测车辆的图像送入pnet,pnet输出多个尺寸为m*n(m、n为像素点的个数)的方框的坐标回归值,每个方框中均为pnet判断可能为车窗的区域,得到可能为车窗区域的方框集合;
截取pnet输出的方框在原图中的对应区域,将所有截取得到的图像合并到一个四维矩阵中,作为rnet的输入,rnet对pnet输出的方框实现进一步筛选,更新方框坐标,使得其精度更高;
将rnet输出的更精确的方框作为onet的输入,onet输出更为精确的方框坐标,并返回车窗四个角的坐标a(a1,b1)、b(a2,b2)、c(a3,b3)和d(a4,b4),如图2所示。
4)去除部分分辨率过低的检测图片;
根据步骤3)中输出的前车窗四角的坐标计算出车窗面积s,将车窗面积s小于人为设定阈值k的图片删除,即去除部分分辨率过低的图片,阈值k可根据实际需要人为设定,该步骤可以有效去除距离过远的车辆图片,其中,面积s的计算方法为两向量的叉乘值|ab×ad|。
5)利用车窗、车引擎盖边界的共线性和平行性,截取车辆引擎盖区域作为图片的目标识别区域;
考虑到在不同场景、不同角度下,车窗和车引擎盖的相对位置不会发生改变,车窗的边界线和车引擎盖的边界线始终满足共线性、平行性,如图3所示,平行四边形abcd为车窗区域,下部灰色区域即平行四边形cdef为车辆引擎盖区域,即始终满足a、d、e共线,b、c、f共线,ab∥cd∥ef;
定义ratio,如公式(1)所示,dy为过a点所在的cd垂线段的长度,如图4所示,经查阅多种品牌与型号的车辆车窗参数,可确定在距离不远的前提下,通过公式(1)计算得到,ratio为1.9~2.1之间,实验证明,在不同型号、以及拍照角度不同的情况下,其ratio值基本不变,在本发明中,ratio的值取为2,需要说明的是,在步骤(4)中,已将距离过远的车辆图片去除,故取ratio=2是较为合理的;
通过公式(2)得到:
在公式(2)中,系数1/3为根据大数据试验得到的经验值,由公式(2)计算得到de线段的长度,可确定e点坐标(a5、b5);
确定e点坐标后,可通过dc∥ef和b、c、f共线确定f点的坐标(a6、b6),此处e点坐标为[a4-2(a1-a4)/3,b4-2(b1-b4)/3],f点坐标为[a3-2(a2-a3)/3,b3-2(b2-b3)/3];
e、f两点坐标确定后,即可截取平行四边形dcfe作为车引擎盖区域;
车引擎盖区域为目标识别区域,在后续颜色识别过程中仅识别该目标识别区域的颜色。
6)对提取的车辆引擎盖区域图像进行饱和度增强处理,采用vibrance自然饱和度算法进行处理,处理过程可参考现有技术进行;
7)用rgb和hsv两套颜色识别模型,对饱和度增强后的车引擎盖图像进行颜色识别,输出最终识别结果,具体为:
事先将hsv颜色识别模型和rgb颜色识别模型分别划分为q个区域,分别表示q个颜色,划分规则可以人为设定,每个区域的区间大小所需颜色的细致程度进行设定,其中,rgb、hsv是两种衡量标准不同的颜色识别模型,在rgb颜色识别模型中,颜色的衡量参数为:r(red:红)、g(green:绿)、b(blue:蓝)分别代表可见光谱中的三种基本颜色,该三种基本颜色按亮度的不同均可分为256个等级,三种颜色进行不同程度的叠加得到各种颜色;
在hsv颜色识别模型中,颜色的衡量参数为:色调h,饱和度s,明度v,不同色调、饱和度、明度的组合,可以形成各种颜色;
采用逐点像素比较的方式确定目标区域颜色,即将步骤7)所得经饱和度增强处理的车辆引擎盖区域图像中每一个像素点在hsv颜色识别模型和rgb颜色识别模型的数值与已预先定义的q种颜色在hsv,rbg色彩空间数值范围进行比较,最终将每一个像素判定为上述颜色的一种,本发明直接通过逐点像素比较的方式确定目标区域颜色,操作简单,降低了处理复杂度。
若rgb颜色识别模型中属于某一颜色的像素点个数为ai,hsv颜色识别模型中属于某一颜色的像素点个数为bi,则属于该颜色的像素点个数平均值为(ai+bi)/2,像素点个数平均值(ai+bi)/2最多的颜色,即为最终识别颜色,该最终识别颜色即为输出值。
本发明解决了传统车辆颜色识别中,背景、车窗等干扰区域对车身颜色识别产生影响的问题,提升了车辆颜色识别的准确性和鲁棒性。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以作出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!