一种测试爬虫数据质量的方法与流程
本发明涉及互联网科技行业技术领域,具体为一种测试爬虫数据质量的方法。
背景技术:
网络爬虫是一个自动提起网页数据的程序,由于网页的多样性和不确定性,得到的爬虫数据的准确性也存在很大的不确定性,目前爬虫数据质量的测试方法比较少,大多数采用传统的人工标注的方式进行测试,显然这种方式的准确率是最高的,但是测试效率极低,成本也较高。
技术实现要素:
本发明的目的在于提供一种测试爬虫数据质量的方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:一种测试爬虫数据质量的方法,包括:
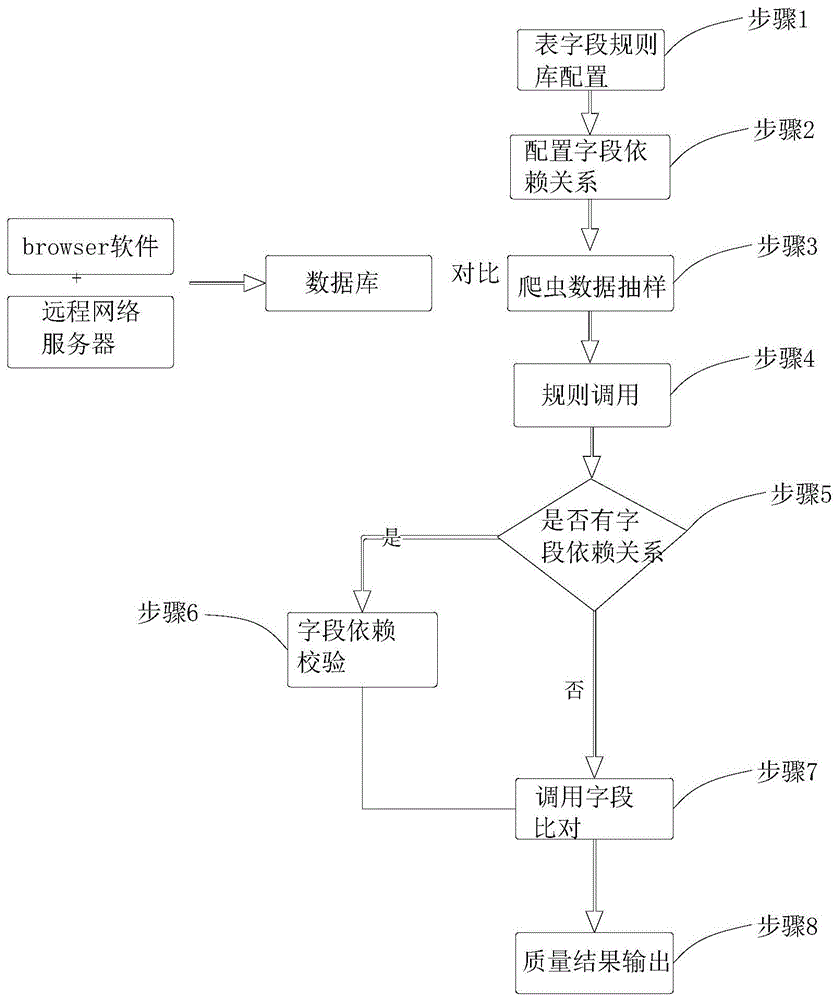
步骤1,表字段规则库配置,从而构成表、字段、正则的匹配关系;
步骤2,配置字段依赖关系;
步骤3,爬虫数据抽样,在被测数据源中随机抽取指定数量的数据样本;
步骤4,规则调用,循环每一条样本数据,然后判断步骤1中表里的字段对应的值是否满足规则;
步骤5,判断是否有字段依赖关系,判断当前字段是否存在规则依赖,即步骤2中的依赖关系里是否包含该字段;
步骤6,字段依赖校验,字段依赖校验模块根据字段a的值验证字段b的值;
步骤7,字段比对,字段比对模块验证对应的字段是否满足规则库中对应的规则;
步骤8,质量结果输出,质量结果输出模块输出错误样本供分析。
优选的,所述步骤5中判断出存在字段依赖关系时,则调用字段依赖校验步骤6,否则调用字段比对模块步骤7。
优选的,所述步骤8中质量输出模块,以excel的形式输出各个字段的缺失率、空值率、准确率、错误率,且txt文件输出错误样本供分析。
优选的,所述表字段规则可以是根据字段本身的业务意义而配置的正则表达式。
优选的,所述步骤1中,可以以公司名称分类为爬取。
优选的,所述爬虫数据抽样前,以用户ip作为凭证,使用browser软件和远程网络服务器作为连接通道,形成一个数据库,与抽样数据进行对比,得出质量分析情况。
优选的,所述数据库中包括记录过去的爬虫数据和网络分类数据;过去的爬虫数据由browser软件以搜索记录、搜索结果和网站id浏览记录数据组合而成,由硬盘存储。
优选的,述网络分类数据包括记录在案的网站信息和分类的领域信息,与抽样的爬虫信息对比,得出信息重合率。
与现有技术相比,本发明的有益效果是:通过爬虫数据抽样、表字段规则库配置、爬虫数据抽样、判断是否有字段依赖关系、字段依赖校验、字段比对和质量结果输出这些步骤,该测试爬虫数据质量的方法高效,速度快,成本低。
附图说明
图1为测试爬虫数据质量的方法流程框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
在本发明的描述中,需要说明的是,术语“上”、“下”、“内”、“外”“前端”、“后端”、“两端”、“一端”、“另一端”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。此外,术语“第一”、“第二”仅用于描述目的,而不能理解为指示或暗示相对重要性。
在本发明的描述中,需要说明的是,除非另有明确的规定和限定,术语“安装”、“设置有”、“连接”等,应做广义理解,例如“连接”,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
如图1所示,本实施例测试爬虫数据质量的方法,包括
一种测试爬虫数据质量的方法,包括:
步骤1,表字段规则库配置,此规则一般是根据字段本身的业务意义而配置的正则表达式,如爬取的公司名字,而公司名字一般以有限公司、有限责任公司、厂等结尾,从而构成表、字段、正则的匹配关系,如a=[field1:regex1,field2:regex2](a为表名,field1和field2为表a里的字段,regex1为field1字段值应该满足的正则表达式,regex2为field2字段值应该满足的正则表达式);
步骤2,配置字段依赖关系,抽取的字段之间有时候是存在关联关系的,如field1值为a时,field2的值一定为b;filed1值为c时,filed2的值应该为空,a={field1:{‘value’:[a1,b1,c1],‘filed1’:[c1,d1,e1]},filed2:{‘value’:[a2,b2,c2],‘filed3’:[c2,d2,e2]}};
步骤3,爬虫数据抽样,在被测数据源中随机抽取指定数量的数据样本;
步骤4,规则调用,循环每一条样本数据,然后判断步骤1中表里的字段对应的值是否满足规则;
步骤5,判断是否有字段依赖关系,判断当前字段是否存在规则依赖,即步骤2中的依赖关系里是否包含该字段,判断出存在字段依赖关系时,则调用字段依赖校验步骤6,否则调用字段比对模块步骤7;
步骤6,字段依赖校验,字段依赖校验模块根据字段a的值验证字段b的值;
步骤7,字段比对,字段比对模块验证对应的字段是否满足规则库中对应的规则;
步骤8,质量结果输出,质量结果输出模块错误样本供分析,以excel的形式输出各个字段的缺失率、空值率、准确率、错误率,且txt文件输出错误样本供分析。
在上述实施例中,所述爬虫数据抽样前,以用户ip作为凭证,使用browser软件和远程网络服务器作为连接通道,形成一个数据库,与抽样数据进行对比,得出质量分析情况。
具体地,所述数据库中包括记录过去的爬虫数据和网络分类数据;过去的爬虫数据由browser软件以搜索记录、搜索结果和网站id浏览记录数据组合而成,由硬盘存储。
具体地,所述网络分类数据包括记录在案的网站信息和分类的领域信息,与抽样的爬虫信息对比,得出信息重合率。
对于本领域技术人员而言,显然本发明不限于上述示范性实施例的细节,而且在不背离本发明的精神或基本特征的情况下,能够以其他的具体形式实现本发明。因此,无论从哪一点来看,均应将实施例看作是示范性的,而且是非限制性的,本发明的范围由所附权利要求而不是上述说明限定,因此旨在将落在权利要求的等同要件的含义和范围内的所有变化囊括在本发明内。不应将权利要求中的任何附图标记视为限制所涉及的权利要求。
技术特征:
技术总结
本发明公开了一种测试爬虫数据质量的方法,包括步骤:表字段规则库配置,配置字段依赖关系,爬虫数据抽样,在被测数据源中随机抽取指定数量的数据样本,规则调用,判断是否有字段依赖关系,判断当前字段是否存在规则依赖,字段依赖校验,字段依赖校验模块根据字段A的值验证字段B的值,字段比对,字段比对模块验证对应的字段是否满足规则库中对应的规则,质量结果输出,质量结果输出模块错误样本供分析,该测试爬虫数据质量的方法高效,速度快,成本低。
技术研发人员:陈双艳
受保护的技术使用者:北京海致星图科技有限公司
技术研发日:2019.07.13
技术公布日:2019.10.25
-
 0访客 来自[未知地区] 2020年04月16日 13:56在第三方如微信,淘宝,微博,小红书,短视频,爬取的数据,我要对爬取的数据进行测试,有好的测试的思路吗,或者方法,该如何去执行,某种数据准确率,数据的覆盖率,URL抽查,酬谢解答,救急,帮帮忙,感谢。
0访客 来自[未知地区] 2020年04月16日 13:56在第三方如微信,淘宝,微博,小红书,短视频,爬取的数据,我要对爬取的数据进行测试,有好的测试的思路吗,或者方法,该如何去执行,某种数据准确率,数据的覆盖率,URL抽查,酬谢解答,救急,帮帮忙,感谢。