基于深度强化学习的配对交易系统的制作方法
本发明涉及配对交易领域,具体涉及基于深度强化学习的配对交易系统。
背景技术:
近些年来,随着经济的快速发展,数字货币、融资融券等金融产品相继在金融市场上出现,经过大量实证研究,配对交易在市场环境复杂的金融市场仍然能够给投资者带来利润。另外互联网以及人工智能技术的快速发展也推动着传统金融行业大步前进,利用计算机技术进行的自动化交易在减少人工成本的同时还可以避免人工交易时由于心理因素造成的不良影响,而且在高频交易领域的量化和交易上人工交易都是无法比拟的。高频交易和自动化交易产生了大量的历史交易信息,将配对交易和机器学习相结合,分析、挖掘这些历史交易数据中的信息,可以对未来市场状态进行预测,为投资者提供可靠的参考。
配对交易是统计套利和量化投资中一个简单但非常重要的投资策略,配对交易通常分为两步进行,即先选择长期相关的资产交易对,再寻找交易的机会,因而对配对交易的研究也大致可以分为两个方面,第一是如何从众多的资产中挑选出长期相关的资产对,第二是如何建立交易模型以找到合适的交易机会。目前配对交易中选择交易对的方法主要有距离法、随机价差法和协整法三种,交易机会的发现主要依赖传统的机器学习、强化学习、深度学习和深度强化学习。
技术实现要素:
本发明的目的是提出基于深度强化学习的配对交易系统,通过采用协整法选择交易对,然后将深度强化学习与配对交易结合,实现自动学习特征和决策,一定程度上避免了专家系统中主观性因素造成的损失,面对复杂多变的金融市场也能够获得可观的利润。
本发明采用的技术方案如下:
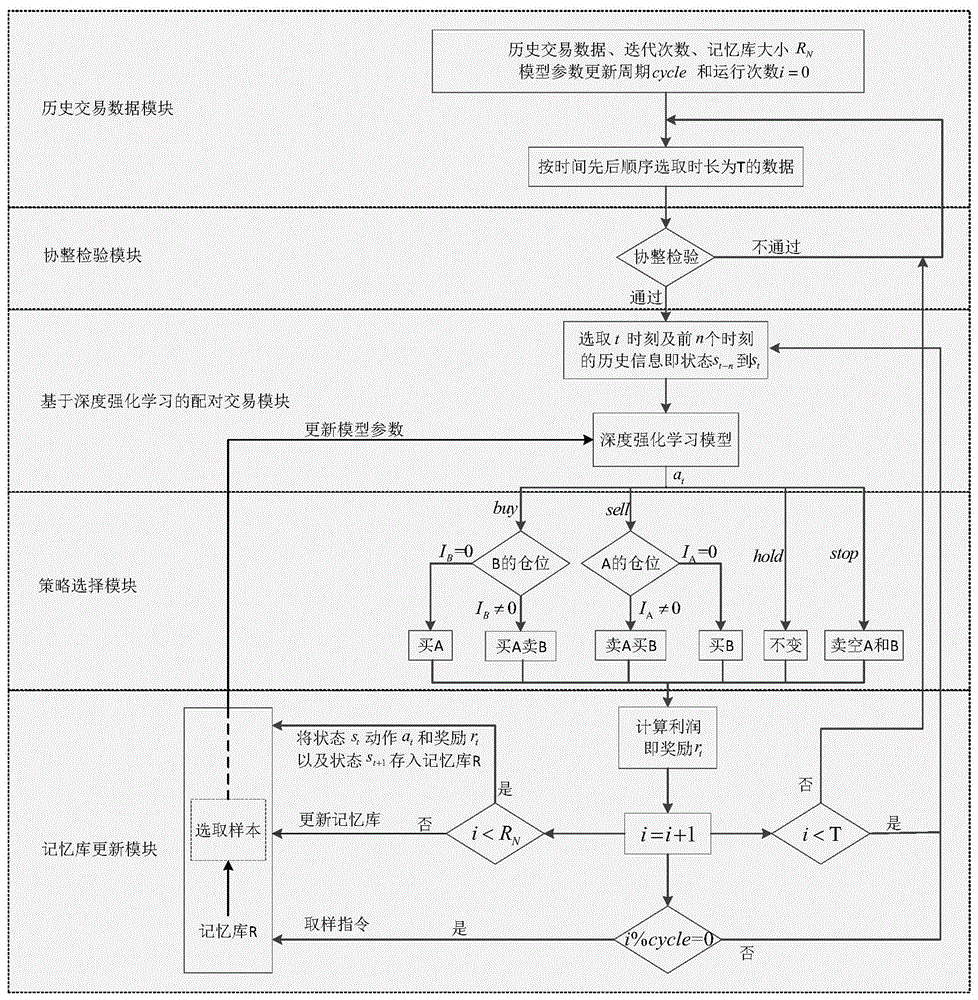
基于深度强化学习的配对交易系统,系统的模块包括:
历史交易数据模块,从交易平台获取历史交易数据,并对数据进行预处理;
协整检验模块,审查资产的基本情况,对相似资产的历史价格序列做相关性分析,选择相关性较大的资产对进行协整检验,将满足协整关系的资产对作为交易对象;
基于深度强化学习的配对交易模块,用于对交易对象的历史交易信息进行分析,并输出结果;
策略选择模块,根据基于深度强化学习的配对交易模块的结果选择交易动作;
记忆库更新模块,即适时删除最早存入的状态、奖励和回报,存入最新的状态。
进一步,所述协整检验模块的相关性分析是指对于两个资产序列变量为x=(x1,x2,…,xt)和y=(y1,y2,…,yt),则其相关性系数r可以表示为
进一步,所述协整检验模块中协整检验是指通过eg两步法检验资产对的协整性。
进一步,所述基于深度强化学习的配对交易模块中将actor-critic强化学习与循环神经网络lstm相结合,采用两个结构相同的神经网络去近似actor-critic中actor的策略函数πθ(a|s)和critic的值函数vπ(st)。具体的步骤如下:
(1)将产品的历史特征作为环境状态输入到actor网络中,生成对应动作;
(2)配对交易系统根据动作做出相应的操作,返回交易的利润作为奖励,把奖励传给critic网络,用于评估td误差;
(3)critic网络对动作和产生的奖励做出评估,然后把td误差传给actor网络用于更新actor网络参数。
critic网络的具体框架为:第一层为lstm,第二层为隐藏层,第三层输出的结果作为值函数vπ(st),然后根据环境对动作at返回的奖励rt,生成时间差分误差(td),计算公式如下:
et_error=rt+ξvπ(st)-vπ(st+1),0≤ξ≤1
cirtic的目标函数是最小化误差函数,记为
actor网络的具体框架为:第一层为lstm,第二层为隐藏层,第三层使用softmax激活函数生成选用各交易动作的概率分布值。actor的梯度更新计算方法为:
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1.本发明中采用actor-critic强化学习方法,能进行单步更新,容易收敛到局部最优解,具有输出最优稳定策略的能力。而现有的基于深度强化学习方法的配对交易方法采用的是策略梯度方法,采用单步更新,学习效率低且具有较高的方差。
2.本发明中利用lstm的特征提取能力避免了人工提取特征的主观性,极大的提高了配对交易中发现交易机会的能力。
3.现有配对交易的研究对象主要是市场集中的股票、期货等金融产品,本专利可面对交易频度高、市场分散的金融资产选择交易动作,以获得利润。
附图说明
图1系统架构图。
图2eg两步协整检验方法示意图
图3基于深度强化学习的配对量化交易网络结构图
具体实施方式
以下结合附图及实施例,对本发明的具体实施方式做进一步说明。
基于深度强化学习的配对交易系统,如图1,包含以下模块:
历史交易数据模块,从交易平台获取历史交易数据,并对数据进行预处理;
协整检验模块,审查资产的基本情况,对相似资产的历史价格序列做相关性分析,选择相关性较大的资产对进行协整检验,将满足协整关系的资产对作为交易对象;
基于深度强化学习的配对交易模块,用于对交易对象的历史交易信息进行分析,并输出结果;
策略选择模块,根据基于深度强化学习的配对交易模块的结果选择交易动作;
记忆库更新模块,即适时删除最早存入的状态、奖励和回报,存入最新的状态。
在本实施例中,系统运行流程主要是通过深度强化学习方法选择进行配对交易,如图1所示。
在历史交易数据模块中,本实施例中从交易平台的api获取历史交易数据,选用的特征数据为:时间戳、开盘价、收盘价、最高价、最低价、最新成交价和交易量。由于获取时间不统一,本实施例中以一分钟为间隔提取已获得的数据,使得不同交易平台间的数据量保持一致,中间数据缺失的用none进行填充,之后再把数据缺失的行剔除掉。由于价差和对数收益率比较小并且有时是正数有时是负数,而且其他特征的数值也大小不一,为了模型更好地训练,本实施例中对平均价、开盘价、收盘价、最高价、最低价和最新成交价、交易量以及相对强弱指标进行归一化处理,具体计算方法如下:
对于t时刻特征序列xt=(x1,x2,…,xn)中的某个特征xi,先对其进行最大最小归一化,然后将xi缩放到区间[0,1]上,计算公式如下:
再将归一化的结果xi_01映射到区间[-1,1]上,计算公式如下:
这里xi_min表示训练数据中特征xi的最小值,xi_max表示训练数据中特征xi的最大值。
在协整检验模块中,本实施例中采用的具体步骤如下:
1.通过分析相关金融资产交易量大小、资产流动性、行业地位以及背后的技术背景等基本情况,挑选出类似的资产作为一个集合c;
2.对c中资产两两配对,对其历史价格序列做相关性分析,设两个资产序列变量为x=(x1,x2,…,xt)和y=(y1,y2,…,yt),则其相关性系数r可以表示为:
这里
3.利用eg两步法检验c_pre中资产对的协整性,如图2所示。首先从c_pre中任意挑选出一对资产ci=1,2,…,k先判断ci中每个资产的历史价格序列是否是一阶单整的,如果是则对资产对的历史价格序列做回归模型yt=α+βxt+εt,再利用adf检验统计量方法检验残差εt的平稳性,如果残差是平稳的,则说明其具有协整关系,如果不平稳,则将ci从c_pre中剔除,继续检验c_pre中下一对资产的协整性。于是c_pre中的资产都满足协整关系,将其作为研究对象,代入到基于深度强化学习的配对量化交易系统中进行配对交易。
在基于深度强化学习的配对交易模块中,如图3,在本实施例中深度强化学习是将actor-critic强化学习与循环神经网络lstm相结合,采用两个结构相同的神经网络去近似actor-critic中actor的策略函数πθ(a|s)和critic的值函数vπ(st)。在本实施例中,具体的步骤如下:
(1)将产品的历史特征作为环境状态输入到actor网络中,生成对应的动作;
(2)配对交易系统根据动作做出相应的操作,返回交易的利润作为奖励,把奖励传给critic网络,用于评估td误差;
(3)critic网络对动作和产生的奖励做出评估,然后把td误差传给actor网络用于更新actor网络参数。
critic网络的具体框架为:第一层为lstm,第二层为隐藏层,第三层输出的结果作为值函数vπ(st),然后根据环境对动作at返回的奖励rt,生成时间差分误差(td),计算公式如下:
et_error=rt+ξvπ(st)-vπ(st+1),0≤ξ≤1
cirtic的目标函数是最小化误差函数,记为
actor网络的具体框架为:第一层为lstm,第二层为隐藏层,第三层使用softmax激活函数生成选用各交易动作的概率分布值。actor的梯度更新计算方法为:
本实施例中采用的配对交易方法如下:
动作空间记为
profitt=a_numst×a_pt+b_numst×b_pt.
设交易中a产品和b产品的交易量分别为a_volt、b_volt,则根据不同的动作at产品剩余量a_numst、b_numst变化如下:
①当at为buy时,买入a产品,卖出b产品。扣除交易中手续费率产品剩余量分别为:
②当at为sell时,卖出a产品,买入b产品.对应的剩余量分别为:
b_numst=b_numst-1+b_volt×(1-fee);
③当at为hold时,a产品和b产品都不交易,交易量为0。因此:
b_numst=b_numst-1;
④当at为stop时,同时卖空a产品和b产品,此时剩余量为0,总资产为:
在基于深度强化学习的配对交易模块中,环境状态st是具有协整关系产品的历史时间序列特征,策略函数πθ(a|s)利用actor网络近似得到,值函数vπ(s)通过critic网络去近似,动作at输入到配对交易方法中,方法获取的利润作为相应的奖励rt。最终目标是最大化累计回报r,其中0≤ξ≤1为折扣因子。
本实施例中模型训练的数据集划分方法如下:
数据集是按照训练期交易期的形式划分的,即从最开始时刻选取t时间的数据作为训练数据,紧接着从t时间后选取t_test时间的数据作为交易数据,之后再选择t时间的数据作为训练,依此循环直到训练和交易完所有数据。
在策略选择模块中,本实施例中包含的动作空间为
在记忆库更新模块中,在策略选择模块中选定交易动作返回奖励rt后,将状态st和st+1和动作at以及奖励rt存入记忆库r中,对比交易次数n和记忆库大小rn,如果n大于rn,则更新记忆库即删除最开始存入的状态、奖励和回报,把最新的状态存入到r中,这样可以保证取样更新模型参数时是最近时间的信息。
本发明公开了基于深度强化学习的配对交易系统,凡在本发明的基础上所作的任何修改、等同替换和改进等,只要原理相同,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!