一种基于向量自回归模型的水驱油藏渗流场评价方法与流程
本发明属于油田注水开发调整领域,涉及一种基于向量自回归模型的水驱油藏渗流场评价方法。
背景技术:
水驱开发作为主要的油藏提高采收率的手段,具有极其广泛的应用。然而目前大部分油藏历经长期水驱开发后,剩余油分布杂乱且分散,难以有效认识水驱油藏动用规律,导致渗流场调整难度大,影响水驱开发效率。
国内学者通过确定渗流场影响参数对渗流场进行评价,为渗流场调整决策提供支撑,然而其方法需要依靠专家经验进行评价,主观性较强,导致评价结果准确性较低。国外学者多通过流线模拟等方法预测并优化水驱油藏注水制度,但其方法在复杂地质条件下,方法存在收敛性较差的缺陷。
对于渗流场而言,由于现有技术无法直接观测地下流体流动情况,因此研究者通过求解基于达西或非达西定律的物质守恒方程的方式模拟地下流体流动,进而表征地下渗流场。而在油藏工程师通过对地质特征完成油藏建模,同时通过数值模拟进行历史拟合,进一步地使油藏模型更加贴近实际地质情况后,仍需要基于拟合完成的模型确定对渗流场的注水调整方法,以进一步提高波及效率及采收率。对于小型油藏而言,可通过经验性的方法调整井作业方式进而调整流场,然而考虑到大部分油藏具有复杂的地质条件及开采方式,油藏优化方案的确定将变得极为挑战性。
因此,针对上述问题,本发明提出了一种基于向量自回归模型的水驱油藏渗流场评价方法。
技术实现要素:
本发明的目的在于:提供了一种基于向量自回归模型的水驱油藏渗流场评价方法,解决了现有渗流场评价方法存在计算成本较高和准确性较低,以及复杂地质条件下存在收敛性较差的问题。
本发明采用的技术方案如下:
一种基于向量自回归模型的水驱油藏渗流场评价方法,包括以下步骤:
收集目标油藏的历史生产数据和/或历史注水数据;
对历史生产数据和/或历史注水数据进行预处理;
根据预处理后的历史生产数据和/或历史注水数据拟合模型,并验证模型;
依据拟合后的模型预测采出井未来的采出量,并对模型的预测结果进行不确定性分析,同时依据拟合后的模型参数评价注入井的采油贡献量。
进一步地,所述收集目标油藏的历史生产数据和/或历史注水数据,具体为收集采出井的历史生产数据和/或注入井的历史注水数据,整理为“*.xlsx”或“*.csv”格式的文件,表格中每行至少包含年月、井号、日产油量数据和/或日注水量数据。
更进一步地,所述对历史生产数据和/或历史注水数据进行预处理,包括:对日产油量数据和/或日注水量数据进行滑窗平滑化处理及归一化处理。
进一步地,所述根据预处理后的历史生产数据和/或历史注水数据拟合模型,并验证模型包括以下步骤:
将预处理后的日产油量数据和/或日注水量数据构造成时间序列格式,即每列数据表示不同井,每行数据表示不同时刻的数据;
通过向量自回归方法依据历史生产数据和/或历史注水数据,拟合历史生产数据,并通过滞后阶数选取的方法为模型选取合理的滞后阶数;
选取历史数据末尾几个月的数据作为验证集,以其之前的数据作为训练集训练模型;
通过训练后的模型对验证集进行预测效果,再对预测的效果进行评价,若验证集的预测效果越好,表明对未来时刻采出井产量的预测效果越好,且对注入井采油贡献量预测精度更高。
更进一步地,所述通过向量自回归方法依据历史生产数据和/或历史注水数据,拟合历史生产数据,并通过滞后阶数选取的方法为模型选取合理的滞后阶数,包括:
构造向量为:
其中,yi,t为t时刻第i口采出井采出量,单位是m3/月;ei,t为t时刻第i口注入井注入量,单位是m3/月;kp为采出井总数;ki为注入井总数;yt为t时刻采出井采出量向量,
通过井间流量的相互关系建立采出井流量预测模型如下:
其中,ai为第i阶采出井参数矩阵,用于描述采出井之间的流量关系,
模型以当月及以往p月采出井日产油量作为yt+…+yt-p+1,并以未来1个月及其前p-1月的日注入量作为输入
其中,带上三角的符号如估计参数矩阵
y=dz+u,
u=[u1,u2,...,un],
其中,y为总因变量矩阵,z为总自变量矩阵,u为总残差矩阵,d为总参数矩阵;
再通过最小二乘法求解:
因为当井数量过多或滞后阶数过大时,得到的结果可能产生过拟合,因此需在方程组添加正则化项;
再依据滞后阶数选择方法选取目标数据集的滞后阶数。
更进一步地,所述通过训练后的模型对验证集进行预测效果,再对预测的效果进行评价,包括:
通过参数对注入井进行评价,评价依据是将任意注入井流量增加固定数值,若是评价采出井则是增加固定数值的采出井流量,观察其对整体系统影响,进一步即可对注入井或采出井进行评价,注入井评价公式为:
其中,
进一步地,所述对模型的预测结果进行不确定性分析,同时依据拟合后的模型参数评价注入井的采油贡献量,包括:
基于将原本的时间序列过程考虑为随机过程,其简洁的矩阵表示如下:
其中,
考虑参数的持续影响:
其中,
对于var模型而言,其中重要的超参数为最大滞后值p,其代表了假设最多yt-p及et-p+1的值的大小将影响yt,该值的选择通过信息准则完成,首先,计算模型在滞后值p时的似然估计值l,并通过考虑似然函数值及模型参数的大小,给出信息准则,公式如下:
aic=-2ln(l)+2k,
bic=-2ln(l)+ln(n)k,
hq=-2ln(l)+ln(ln(n))k,
其中,l为似然估计值,aic为aic信息准则评价值,bic为bic信息准则评价值,hq为hq信息准则评价值,fpe为fpe信息准则评价值,k为模型参数个数,通过综合考虑以上四个信息准则,选取使以上准则值均较小的滞后阶数即为合适的滞后阶数p。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
1.一种基于向量自回归模型的水驱油藏渗流场评价方法,通过拟合采出井历史生产数据,建立机器学习模型,捕捉可能存在的任意采出井采油量同历史数据的关系,可对复杂数据关系建模,精度高,计算时间短,并可通过模型模拟注入井增注效果评价注入井采油贡献量,有效地避免了复杂地质条件下数值模拟拟合存在收敛性较差的问题。与现有渗流场评价方法相比,本发明涉及的方法主观性较少,无需依靠专家经验即可进行评价,且精确度较高,且预测可进行不确定性分析,确保预测结果的安全性与准确性。
2.以本发明对m油田x区油藏2017年5月以前的数据预测2017年5月至2018年3月采出井采油量,预测精度可达86.92%,且以本发明对m油田x区数值油藏模型依据注入井评价结果进行注水调整,数值模拟采收率在2年内提升0.3112%,产油量多出34770m3,实践表明以本发明得出评价结果的准确性较高。
3.本发明中向量自回归模型善于挖掘多口井之间的数据关系,善于从多个时间序列中提取出相互作用规律,模型适应性强,与现有渗流场评价方法相比,不仅计算成本较低,而且预测精度较高。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图,其中:
图1是一种基于向量自回归模型的水驱油藏渗流场评价方法的流程图;
图2是本发明实施例一的注采井间的协相关矩阵图;
图3是本发明实施例一的为相关性最高的两对注采井;
图4是本发明实施例一的不同采出井的预测验证结果图;
图5是本发明实施例一的验证集内在产的采出井预测误差情况;
图6是本发明实施例一的对验证集预测结果进行不确定性分析的结果图;
图7是本发明实施例一的不同注入井对全体采出井采油量单一时间步长影响折线图;
图8是本发明实施例一的不同注入井对全体采出井采油量累积时间步长影响折线图;
图9是本发明实施例一的注入井的评价结果图;
图10是本发明实施例一的机器学习模块用于采出井产量预测及渗流场评价的应用界面;
图11是本发明实施例一的滞后阶数分析模块界面;
图12是本发明实施例一的预测结果绘制模块界面和脉冲响应模块界面。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明,即所描述的实施例只是本发明的一部分实施例,而不是全部的实施例。通常在此处描述和附图中示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明的实施例,本领域技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
需要说明的是,术语“第一”和“第二”等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
一种基于向量自回归模型的水驱油藏渗流场评价方法,解决了现有渗流场评价方法存在计算成本较高和准确性较低,以及复杂地质条件下存在收敛性较差的问题。
一种基于向量自回归模型的水驱油藏渗流场评价方法,包括以下步骤:
步骤1:收集目标油藏的历史生产数据和/或历史注水数据;
步骤2:对历史生产数据和/或历史注水数据进行预处理;
步骤3:根据预处理后的历史生产数据和/或历史注水数据拟合模型;
步骤4:依据拟合后的模型预测采出井未来的采出量,并对模型的预测结果进行不确定性分析,同时依据拟合后的模型参数评价注入井的采油贡献量。
本发明通过拟合采出井历史生产数据,建立机器学习模型,捕捉可能存在的任意采出井采油量同历史数据的关系,可对复杂数据关系建模,精度高,计算时间短,并可通过模型模拟注入井增注效果评价注入井采油贡献量,有效地避免了复杂地质条件下数值模拟拟合存在收敛性较差的问题。与现有渗流场评价方法相比,本发明涉及的方法主观性较少,无需依靠专家经验即可进行评价,且精确度较高,且预测可进行不确定性分析,确保预测结果的安全性与准确性。
下面结合实施例对本发明的特征和性能作进一步的详细描述。
实施例一
本发明的较佳实施例,以m油田x区断块油藏为例,提供了一种基于向量自回归模型的水驱油藏渗流场评价方法,如图1所示;
向量自回归(var)是一种随机过程模型,用于捕获多个时间序列数据之间的相互线性依赖关系。模型中任意变量均可通过其自身与其他变量的滞后值、确定性变量及误差项组成的方程表示,并对其未来值进行推演。模型不需要使用数值模拟方式,通过联立方程的结构模型并需要变量在渗流过程中具体作用的方式。var方法所需的唯一先验知识是可以假设在跨期上相互影响的变量列表,即给出目标变量的可选的影响因素,因此需观察变量间的相关性,即注入井和采出井(简称注采井)间的相关性
如图2所示为注采井间的协相关矩阵,横坐标为注入井,纵坐标为采出井,图中颜色较浅代表相关性较高,颜色较深则相反,从该图可观察出采出井的采油量和注入井的注入量间的相关性,从该协相关矩阵可看出,大部分注采井间的流量并不相关,然而少部分注采井间的相关性较强;如图3所示为相关性最高的两对注采井,由图可知,部分注采井呈现出同增同减的情况,进而可假设注采井流量可通过线性关系表征,进而可针对性地对注采井网系统建模,因此本发明将不同采出井产量及注入井注入量作为彼此相关的时间序列过程,建立向量自回归(var)模型,捕捉井间产量依赖关系,模拟未来产量,并对注入井局部渗流场进行评价;
所述方法包括以下步骤:
步骤1:收集目标油藏的历史生产数据和/或历史注水数据,具体为收集采出井的历史生产数据和/或注入井的历史注水数据,整理为“*.xlsx”或“*.csv”格式的文件,表格中每行至少包含年月、井号、日产油量数据和/或日注水量数据;
步骤2:对历史生产数据和/或历史注水数据进行预处理,具体对日产油量数据和/或日注水量数据进行滑窗平滑化处理及归一化处理,可增加数据的平稳程度,减少拟合难度;
步骤3:根据预处理后的历史生产数据和/或历史注水数据拟合模型,并验证模型;
步骤3.1:将预处理后的日产油量数据和/或日注水量数据构造成时间序列格式,即每列数据表示不同井,每行数据表示不同时刻的数据;
步骤3.2:通过向量自回归方法依据历史生产数据和/或历史注水数据,拟合历史生产数据,并通过滞后阶数选取的方法为模型选取合理的滞后阶数;
构造向量为:
其中,yi,t为t时刻第i口采出井采出量,单位是m3/月;ei,t为t时刻第i口注入井注入量,单位是m3/月;kp为采出井总数;ki为注入井总数;yt为t时刻采出井采出量向量,
通过井间流量的相互关系建立采出井流量预测模型如下:
其中,ai为第i阶采出井参数矩阵,用于描述采出井之间的流量关系,
模型以当月及以往p月采出井日产油量作为yt+…+yt-p+1,并以未来1个月及其前p-1月的日注入量作为输入
其中,带上三角的符号如估计参数矩阵
y=dz+u,
u=[u1,u2,...,un],
其中,y为总因变量矩阵,z为总自变量矩阵,u为总残差矩阵,d为总参数矩阵;
再通过最小二乘法求解:
因为当井数量过多或滞后阶数过大时,得到的结果可能产生过拟合,因此需在方程组添加正则化项;
本实施例中,依据滞后阶数选择方法选取目标数据集的滞后阶数为6;
步骤3.3:选取历史数据末尾几个月的数据作为验证集,以其之前的数据作为训练集训练模型,若数据的最长的时间为2018年,则设置以2017年以前的数据为训练集,2017年以后数据为验证集;
本实施例中选取m油田x区历史生产数据中2017年5月以前的数据作为训练集,2017年5月及之后的数据作为验证集,对模型预测结果进行验证;
如图4所示为本实施例的不同采出井的预测验证结果,图4(a)为西43-6-4和西44-5-2的训练集数据,图4(b)为西44-8-2和西46-5-1的训练集数据,图4(c)为西1-9-2和西42-8-1的训练集数据,图4(d)为西49-5-3和西50-5-1的训练集数据,图中点线表示训练集数据,差标记代表验证集数据,实线代表预测的验证集数据,可见,原始训练集数据波动较大,给预测带来了一定挑战,进一步分析验证集内产量大于0的采出井预测情况;
步骤3.4:通过训练后的模型对验证集进行预测效果,再对预测的效果进行评价,若验证集的预测效果越好,表明对未来时刻采出井产量的预测效果越好,且对注入井采油贡献量预测精度更高;
通过参数对注入井进行评价,评价依据是将任意注入井流量增加固定数值(通常为1),若是评价采出井则是增加固定数值的采出井流量,观察其对整体系统影响,进一步即可对注入井或采出井进行评价,注入井评价公式为:
其中,
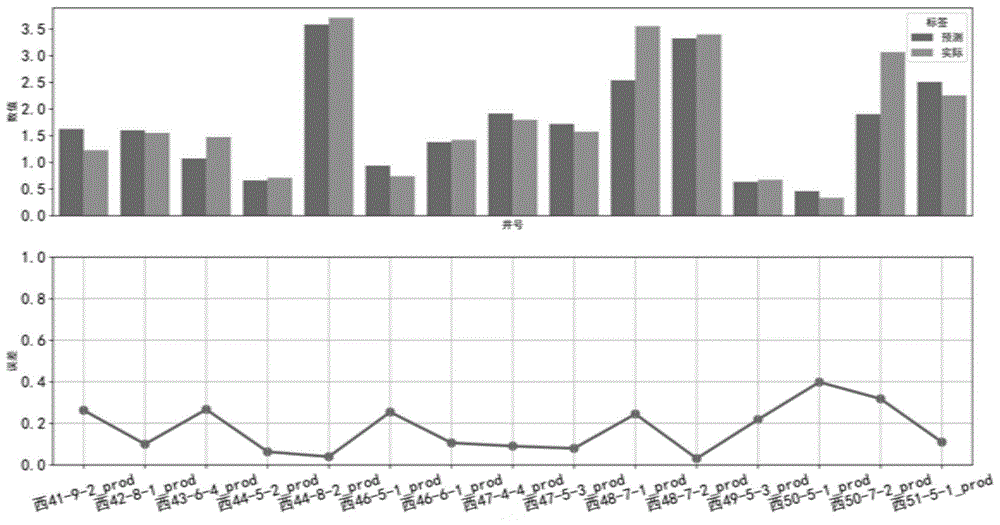
如图5所示为验证集内在产的采出井预测误差情况,柱状图中黄色为柱状图为验证集内实际平均产量,蓝色为预测平均产量,下方线性图为预测相对误差值,可见,除少部分采出井由于近期实施了增产措施,因此预测结果较实际结果偏低,其他采出井均拟合较好,其中验证集中在产的采出井平均绝对误差值为0.513392,平均相对误差为0.130811,表明拟合效果较好;
步骤4:依据拟合后的模型预测采出井未来的采出量,并对模型的预测结果进行不确定性分析,同时依据拟合后的模型参数评价注入井的采油贡献量;
由于给定的数据量较小,预测结果仍具有一定误差,而不确定分析可给出因以往数据导致的模型误差大小,并给出模型对于预测的把握性大小,进行更为安全的预测,即在预测不确定性较大时谨慎决策,因此,对模型预测及评价结果进行不确定性分析是必要的,对预测不确定性大小的推导主要基于将原本的时间序列过程考虑为随机过程,其简洁的矩阵表示如下:
其中,
考虑参数的持续影响:
其中,
对于var模型而言,其中重要的超参数为最大滞后值p,其代表了假设最多yt-p及et-p+1的值的大小将影响yt,该值的选择通过信息准则完成,首先,计算模型在滞后值p时的似然估计值l,并通过考虑似然函数值及模型参数的大小,给出信息准则,公式如下:
aic=-2ln(l)+2k,
bic=-2ln(l)+ln(n)k,
hq=-2ln(l)+ln(ln(n))k,
其中,l为似然估计值,aic为aic信息准则评价值,bic为bic信息准则评价值,hq为hq信息准则评价值,fpe为fpe信息准则评价值,k为模型参数个数,通过综合考虑以上四个信息准则,选取使以上准则值均较小的滞后阶数即为合适的滞后阶数p;
如图6所示为对验证集预测结果进行不确定性分析结果图,点为训练数据,叉为验证集数据,实线为对验证集数据的预测结果,面积为不确定性范围,可见不同采出井的预测不确定性范围基本包含了实际的情况;同时,由不确定性公式提到的,预测不确定性大小主要由训练集预测误差及参数决定,因此当训练集预测误差较大时预测不确定性较大,如图6(c)和(d)所示。
基于机器学习方法的渗流场评价则是通过假设某注入井当月平均日注量增加1m3,观察其对其他采出井影响,进一步地,通过该方法计算出不同注入井对整体油藏产量影响,如图7、图8所示为不同注入井对全体采出井采油量影响折线图,图7为单一时间步长影响,图8为累积时间步长影响,图中,纵坐标为影响,单位是m3/d,若为1则代表增加了全体采出井日采油量共1m3/d,,横坐标为时间,单位是月,可见单一时间步长影响随时间的增加在逐渐减少。图8标为2的图给出了不同采出井的累积影响,可见,当步长为10时,大部分注入井的影响均收敛至0左右,因此本文根据步长为10时的累积影响对注入井的价值进行评价,如图9所示为注入井的评价结果,表示模型预测的对不同注入井注入1m3注入水所带来的采油贡献量,依据该结果即可为渗流场调整方案提供依据。
将本发明的方法通过python编程语言实现机器学习模块功能,保证算法的实用性与便捷性,通过软件的评价结果可为渗流场综合调整提供理论支撑,并进一步提升复杂高含水油藏水驱效率与动用程度;
将机器学习模块用于采出井产量预测及渗流场评价的应用,其界面如图10所示,该应用通过读取油田的采出井周报或月报数据,同时可选择机器学习模型中是否考虑注入井影响,若不考虑则是假设目标油藏没有注入井。在本文中考虑了注入井影响。进一步地,需要对模型选取合适的滞后阶数,如图11所示为对滞后阶数分析的模块界面,展示了目标油藏数据对应四个信息准则,可见当滞后阶数为6时其中三个信息准则值均为最小值,因此选取滞后阶数为6较为合理,进一步地,选取m油田x区油藏2017年5月以前的生产及注水数据作为训练集,2017年5月及之后的数据作为验证集,对模型预测结果进行验证,该模块如图12所示。
本发明创新性地使用了向量自回归方法对采出井采油量进行预测,并可对预测结果进行不确定性分析,提高了方法预测的准确性与收敛性。同时方法可计算注入1m3注入水时不同注入井采油贡献量,从而评价注入井控制区域的开发潜能,为渗流场调整提供依据。通过拟合采出井历史生产数据,建立机器学习模型,捕捉可能存在的任意采出井采油量同历史数据的关系,可对复杂数据关系建模,精度高,计算时间短,并可通过模型模拟注入井增注效果评价注入井采油贡献量,有效地避免了复杂地质条件下数值模拟拟合存在收敛性较差的问题。与现有渗流场评价方法相比,本发明涉及的方法主观性较少,无需依靠专家经验即可进行评价,且精确度较高,且预测可进行不确定性分析,确保预测结果的安全性与准确性。以本发明对m油田x区油藏2017年5月以前的数据预测2017年5月至2018年3月采出井采油量,预测精度可达86.92%,且以本发明对m油田x区数值油藏模型依据注入井评价结果进行注水调整,数值模拟采收率在2年内提升0.3112%,产油量多出34770m3,实践表明以本发明得出评价结果的准确性较高。
需要说明的是,由于说明书附图不得着色和涂改,所以本发明中部分区别明显的地方比较难以显示,若有必要,可提供彩色图片。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明的保护范围,任何熟悉本领域的技术人员在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!