一种多云环境下低成本高可用性的数据优化存储方法与流程
本发明涉及数据存储优化方案选择和多目标求解领域,特别是涉及一种多云环境下低成本高可用性的数据优化存储方法。
背景技术:
随着互联网、物联网、社交网络等相关技术的快速发展,“大数据”时代已经到来。数据量的爆炸性增长和用户对数据安全要求的不断提高让如何建立安全、高可用性的数据存储成为业界亟需解决的问题。相比于传统的数据存储模式,云存储减少了用户的硬件维护成本和人力投入,而且云存储具有易扩容、易管理、价格低等优点,随着云计算的蓬勃发展,许多云服务商纷纷推出了自己的云存储服务,比如amazons3、microsoftazurestorage、googlecloudstorage以及aliyunoss等。
然而不同地区的同一个云服务商提供的同一功能云存储服务的价格存在异质性,提供相同功能的云存储服务在不同服务商之间也是不同的。例如,microsoftazurecloudstorage在澳大利亚东部地区的存储价格比usa东部地区和欧洲北部的低,但是澳大利亚东部地区的带宽价格比其它两个地区都要高;amazons3在usaoregon的相比于usa东部的centurylinkcloud有较低的存储成本,但是get操作成本较高。针对多云环境下的数据优化存储问题,用户最为关心的两个指标是成本和可用性,然而成本和可用性之间存在相互制约,用户想要从庞杂的云市场中选择满足自己需求的云存储服务面临着严峻的挑战。
技术实现要素:
本发明的目的是:帮助用户从云市场中选择满足自己需求的云存储服务。
为了达到上述目的,本发明的技术方案是提供了一种多云环境下低成本高可用性的数据优化存储方法,其特征在于,包括以下步骤:
步骤1、定义用户在数据文件的存储过程所要支付的总成本,具体包括存储成本pstor、get操作成本pop以及带宽成本pnet;
步骤2、多云环境下数据存储方案选择问题是一个较为典型的多目标优化问题,其优化目标是在满足用户最低可用性约束的前提下最大化所选方案的数据可用性,同时最小化总成本,最终得到由一系列pareto等级为1的个体组成的pareto非劣解集p,再利用熵权法确定成本和可用性权重计算pareto非劣解集p中各个解决方案的qos,进而向用户推荐最优解决方案。其中,pareto非劣解集p的求解过程包括以下步骤:
步骤201、从cloudharmony上收集各云服务商所提供的数据存储服务的相关信息,并对收集到的信息进行初步的预处理和筛选;
步骤202、考虑到数据分存的erasurecoding参数,分别使用控制染色体数量遍历各个erasurecoding参数取值的方法以及通过分治法多次运行ndp算法,每次选取不同的erasurecoding参数的方法初始化种群,并基于nsga-ii算法执行选择、交叉、变异、非支配排序,得到一系列pareto等级为1的个体组成的pareto非劣解集p。
基于步骤2的优选结果,利用熵权法确定成本和可用性权重计算pareto非劣解集p中各个解决方案的qos,进而向用户推荐最优解决方案,具体包括以下步骤:
对得到pareto非劣解集p进行归一化处理,将所有非支配解归一化后的成本和可用性转化为一个大小为m×2的矩阵a,并计算各个目标所占的比重,并转换为各指标的信息熵权值,更进一步根据各项指标的权重计算每个非支配解对应的数据存储方案的qos值,从中选出具有最大qos值的数据存储方案作为向用户推荐的最优解决方案。
由于采用了上述的技术方案,本发明与现有技术相比,具有以下的优点和积极效果:本发明采用了pareto最优解集的思想求解最小化成本同时最大化可用性的多目标优化模型,得到的结果比智能优化算法更完整,并且不会有多余的劣质解出现在最后的集合中。更进一步,通过信息熵的方法为用户推荐一个最优的数据存储方案,以帮助用户做出更加合理准确的决策。本发明具有快速高效,并且从成本、可用性等目标出发紧贴用户需求,对于在多云环境下确定适合的数据存储方案以及解决类似的多目标优化问题具有普遍适用性。可在企业中进行推广和应用,具有较强的社会及商业价值。
附图说明
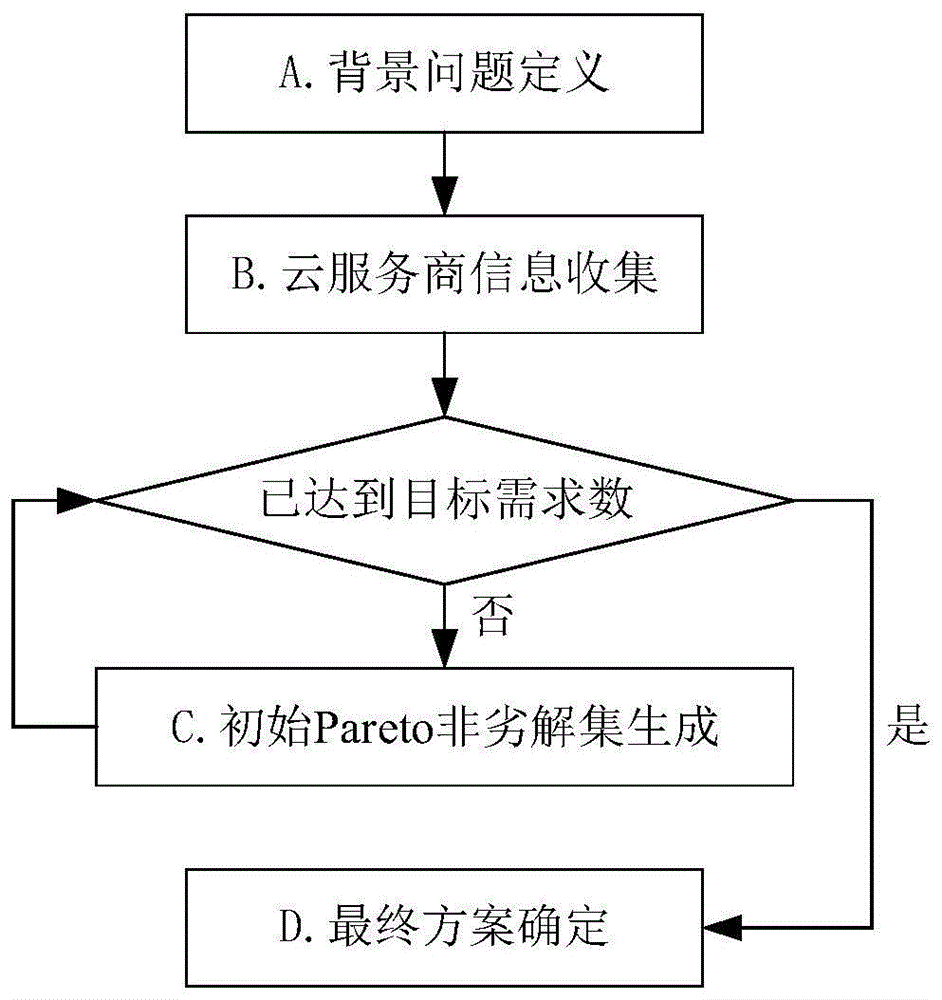
图1是本发明的整体流程图;
图2是本发明中初始pareto非劣集合生成算法流程图。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。
本发明的实施方式涉及一种多云环境下低成本高可用性的数据优化存储方法,如图1所示,包括以下步骤:a.背景问题定义;b.云服务商信息收集;c.初始pareto非劣解集生成;d.最优方案确定。
其中,步骤a具体包括:
a1.定义用户在数据文件的存储过程所要支付的总成本,具体包括存储成本pstor、get操作成本pop以及带宽成本pnet;
a2.定义数据存储方案选择的多目标优化问题,多云环境下的数据存储方案选择问题是一个较为典型的多目标优化问题,用户所关心的数据可用性和总成本是一对相互制约的因素。因此对于该问题,目标是最大化所选方案的数据可用性,同时在满足用户最低可用性约束的前提下最小化总成本,最终得到由一系列pareto等级为1的个体组成的pareto非劣解集p。再利用熵权法确定成本和可用性权重计算各个解决方案的qos,进而向用户推荐最优解决方案。
步骤b具体包括:从cloudharmony上收集各云服务商所提供的数据存储服务的相关信息,包括存储、带宽以及各种操作的价格等内容,并对收集到的原始数据进行初步的预处理和筛选,以方便后续操作。
本发明使用的部分云服务商所提供的数据存储服务的信息如下表所示:
步骤c具体包括:考虑到数据分存的erasurecoding参数,分别使用控制染色体数量遍历各个erasurecoding参数取值的方法以及通过分治法多次运行ndp算法,每次选取不同的erasurecoding参数的方法初始化种群,并基于nsga-ii算法执行选择、交叉、变异、非支配排序等操作,得到一系列pareto等级为1的个体组成的pareto非劣解集p。
步骤d具体包括:对步骤c中得到pareto解集进行归一化处理,将所有非支配解归一化后的成本和可用性转化为一个大小为m×2的矩阵a,并计算各个目标所占的比重,并转换为各指标的信息熵权值,更进一步即可根据各项指标的权重计算每个非支配解对应的数据存储方案的qos值,从中选出具有最大qos值的数据存储方案。
不难发现,本发明采用了pareto最优解集的思想求解最小化成本同时最大化可用性的多目标优化模型,得到的结果比智能优化算法更完整,并且不会有多余的劣质解出现在最后的集合中。更进一步,通过信息熵的方法为用户推荐一个最优的数据存储方案,以帮助用户做出更加合理准确的决策。本发明具有快速高效,并且从成本、可用性等目标出发紧贴用户需求,对于在多云环境下确定适合的数据存储方案以及解决类似的多目标优化问题具有普遍适用性。可在企业中进行推广和应用,具有较强的社会及商业价值。
- 还没有人留言评论。精彩留言会获得点赞!