一种基于OpenACC的归一化植被指数并行提取方法与流程
本发明涉及遥感应用加速领域,具体涉及一种基于openacc的归一化植被指数并行提取方法。
背景技术:
归一化植被指数(ndvi)在农业遥感中起到了至关重要的作用,适用于植被的动态监测与城市植被覆盖的时空变化监测。目前我国已建立了30个高分辨率对地观测系统数据与应用中心,每年有海量的遥感卫星数据亟待处理。加速对遥感大数据的处理已成为遥感应用过程中的重大课题。
基于大规模集群的遥感影像处理是目前主流的处理模式,然而如何挖掘集群中单个节点内部的数据计算能力已成为遥感影像计算中不可忽视的问题。左宪禹等提出一种基于openmp和opencv的归一化植被指数并行计算方法(基于openmp和opencv的归一化植被指数并行计算研究[j].遥感科学.2017:33-40.),该算法主要基于多核cpu,仅考虑了单节点内部的多核cpu的计算资源,而未考虑计算能力更强的gpu计算资源,而传统的gpu编程标准较高,开发难度较大,开发周期较长,且对植被指数提取的加速流程未能提出一种规范的并行模型。
技术实现要素:
针对传统的遥感影像处理算法在提取归一化植被指数时,对植被指数提取的加速流程未能提出一种规范的并行模型的问题,本发明提供一种基于openacc的归一化植被指数并行提取方法,能够结合植被指数提取流程串并行操作分离的特点,快速且规范的并行提取归一化植被指数。
本发明提供一种基于openacc的归一化植被指数并行提取方法,该方法包括:
步骤1:将mat矩阵存储结构的影像数据转换为顺序存储结构的影像数据;
步骤2:读取影像数据,并将影像数据复制至加速设备;
步骤3:将归一化植被指数提取算法的所有操作分为并行操作和非并行操作,利用加速设备基于openacc对并行操作进行并行处理,采用主机对非并行操作进行处理;其中,所述并行操作包括:直方图计算操作、图像拉伸操作、直方图均衡化操作、归一化植被指数计算操作和图像二值化操作。
进一步地,所述非并行操作包括:影像数据最大最小值统计操作、cdf计算操作和影像数据阈值计算操作。
进一步地,步骤1包括:
步骤1.1:读取mat矩阵的宽度和高度;
步骤1.2:根据mat矩阵的宽度和高度确定数组的长度,所述数组用于顺序存储影像数据;
步骤1.3:循环遍历获取mat矩阵中的各影像数据值,并将各影像数据值按照遍历顺序存储至所述数组中。
进一步地,所述并行处理包括:粗粒度并行处理和细粒度并行处理。
进一步地,所述图像拉伸操作、直方图均衡化操作、归一化植被指数计算操作和图像二值化操作均采用粗粒度并行处理;所述直方图计算操作采用细粒度并行处理。
本发明的有益效果:
本发明提供的一种基于openacc的归一化植被指数并行提取方法,第一方面,在实现并行化植被指数提取的基础上将植被指数提取流程进行了规范化设计,经过图像拉伸、图像均衡化等操作有效提升了结果影像的生成质量。第二方面,openacc加速归一化植被指数提取,利用主机指导加速设备的运行,在执行设备上的函数时需要将主机内存中的数据拷贝至设备内存,加速处理遥感影像需要借助opencv对影像进行读取识别,然而openacc无法处理opencv中存储影像的mat矩阵,因而在本发明中将opencv读入的mat矩阵转化成易于被openacc加速的顺序存储结构来存储遥感影像信息数据,解决了openacc不支持并行opencv中mat类型矩阵的问题,在算法中将mat类型转化为适合openacc操作的数据结构,数据结构转换后的算法采用openacc的指令可以快速并行化,并行结果在没有降低实验精度的同时能够达到较好的加速效果。第三方面,随着数据规模的增大,openacc的加速策略具有优异的加速性能、高效的开发流程、较高的计算精度;经多组实验验证,当影像的数据规模达到10000*10000时,本发明提供的基于openacc的归一化植被指数提取方法对比串行提取算法,前者速度比后者提升了5倍多。此外,本发明适宜遥感植被指数相关算法的快速并行开发,在达到较好加速效果的同时能够快速对植被指数专题算法并行化,提升了并行编程效率,加速了并行程序开发,非常适合工程化应用方面的推广。
附图说明
图1为本发明实施例提供的一种基于openacc的归一化植被指数并行提取方法的流程示意图之一;
图2为本发明实施例提供的一种基于openacc的归一化植被指数并行提取方法的流程示意图之二;
图3为本发明实施例提供的openacc并行设计的流程示意图;
图4为本发明实施例提供的开封市归一化植被指数提取结果示意图;
图5为本发明实施例提供的基于openacc的归一化植被指数并行提取方法的性能分析图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
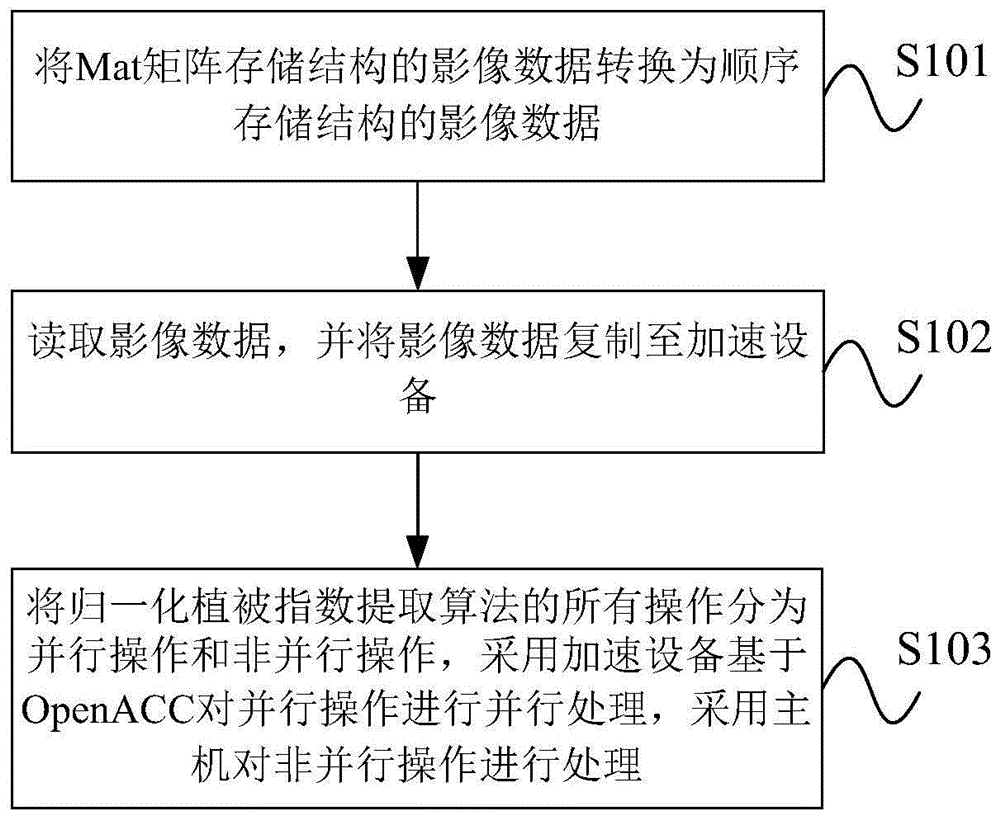
如图1所示,本发明实施例提供的一种基于openacc的归一化植被指数并行提取方法,包括以下步骤:
s101:将mat矩阵存储结构的影像数据转换为顺序存储结构的影像数据;
具体地,一般在加速处理遥感影像需要借助opencv对影像进行读取识别,然而openacc无法处理opencv中存储影像的mat矩阵,因而需要将opencv读入的影像数据由mat类型转化为可适应加速计算的顺序存储结构,包括以下步骤:
s1011:读取mat矩阵的宽度和高度;
s1012:根据mat矩阵的宽度和高度确定数组的长度,所述数组用于顺序存储影像数据;
s1013:循环遍历获取mat矩阵中的各影像数据值,并将各影像数据值按照遍历顺序存储至所述数组中。
该转化算法可用以下程序进行实现:
s102:读取影像数据,并将影像数据复制至加速设备;
具体地,主机端读取顺序存储结构的影像数据,并将该影响数据从主机复制至加速设备(gpu)。
s103:将归一化植被指数提取算法的所有操作分为并行操作和非并行操作,采用加速设备基于openacc对并行操作进行并行处理,采用主机对非并行操作进行处理;其中,所述并行操作包括:直方图计算操作、图像拉伸操作、直方图均衡化操作、归一化植被指数计算操作和图像二值化操作;所述非并行操作包括:影像数据最大最小值统计操作、cdf计算操作和影像数据阈值计算操作。
具体地,如图2所示的归一化植被指数提取算法的处理流程,在分析归一化植被指数提取算法的处理流程后,归一化植被指数提取算法中的图像拉伸操作、直方图计算操作、直方图均衡化操作、归一化植被指数计算操作、图像二值化操作等5个操作的计算密度较大,适宜从主机迁移至加速设备中进行并行计算,从而提升计算效率。如图2所示,灰色填充部分的操作为并行操作,均在加速设备端进行并行处理,白色填充部分为非并行操作,均在主机端进行处理,本发明实施例中的归一化植被指数提取算法的流程包括如下步骤:
s201:直方图计算操作,具体为:选取影像数据中的近红外和红外波段数据进行直方图计算,即在数组中对影像的像素信息作统计。影像的直方图能够反映影像像素点的概率分布。
s202:影像数据最大最小值统计操作,具体为:根据直方图计算结果选取波段数据的最大值和最小值。
s203:图像拉伸操作,具体为:利用最大最小值拉伸的方法对图像进行拉伸,增强图像对比度,加大反差度从而解决由于遥感影像没有经过精确校正等预处理所存在的地物模糊问题。
s204:直方图计算操作,具体为:对拉伸后的近红外与红外波段数据进行直方图计算;
s205:cdf计算操作,具体为:根据步骤s104中得到的直方图计算累积分布函数中的最小值;
s206:直方图均衡化操作,具体为:将波段数据进行函数变换;该步骤使得图像的直方图能够分布更均衡,从而使得图像的对比度最大化,广泛地应用在图像增强处理中。
s207:归一化植被指数计算操作,具体为:利用均衡化后的近红外和红外波段数据计算ndvi的值,
s208:直方图计算,具体为:将步骤s107计算得到的波段进行直方图计算;
s209:影像数据阈值计算操作,具体为:遥感领域中不同的地物都具体特定的灰度域范围,在信息特征变化的影像中确定影像的阈值,根据步骤s108的计算结果,利用最大类间方差法计算影像的阈值;
s210:图像二值化操作,具体为:将图像中所有的像素点与阈值比较,小于阈值的部分置为黑色,大于阈值的部分置为白色。图像的二值化适宜影像计算结果的展示。
在上述实施例的基础上,所述并行处理包括:粗粒度并行处理和细粒度并行处理。如图3所示,在采用加速设备对预设操作进行并行处理之前,需对预设操作进行判断,确定预设操作适合粗粒度并行处理还是细粒度并行处理,判断规则是:分析循环是否存在竞争或依赖,是则进行粗粒度并行,否则进行细粒度并行。
图像的直方图计算操作存在多个迭代需同时访问内存中某个地址,会产生数据竞争。换言之有两次迭代试图同时访问同一个位置上的数据进行修改就会产生数据计算错误,如多次累加或者内积运算,因而需要作原子操作。作为一种可实施方式,所述图像拉伸操作、直方图均衡化操作、归一化植被指数计算操作和图像二值化操作均采用粗粒度并行处理;所述直方图计算操作采用细粒度并行处理。
下面对本发明实施例提供的基于openacc的归一化植被指数并行提取方法的有效性进行如下测试实验:
实验环境:加速设备参数:quardom4000;主机设备参数:intelxeon(r)cpue5-1603;软件平台:ubuntu16.04lts、cuda10.0、pgi17.4(社区版)、opencv3.3.0。
从性能分析、加速比统计、实验精度三个方面归纳分析基于openacc的归一化植被指数并行提取方法的性能。
pgi编译器编译基于openacc的算法文件生成可执行文件,使用pgprof性能分析工具对结果进行分析,可以发现:由于需要原子操作的原因,直方图计算时较为耗时,且需要多次计算,忽视主机和设备频繁通信过程,其加速效果较好,如图5所示。
实验对包含开封市在内的五景影像作七次实验,记录归一化植被指数提取算法的串行时间,并行时间和加速比,时间记录范围不包含影像的读入,如表1所示。
表1
基于openacc的并行算法在加速性能上相对于串行算法有大幅提升,当数据规格足够大的时候加速效果尤其明显,具有较好的并行可扩展性,当计算的数据规模达到10000*10000时,基于openacc的单gpu加速比达到了5.3倍。
误差分析是对并行算法实验精度的验证,使用下式:
式中,
对串行和并行算出来的结果影像验证精度。结果影像位深均为8位,遍历生成的结果影像上的像素点,统计对应位置上的数值是否一致,经计算error为0,说明基于openacc的归一化植被指数并行提取方法在提升计算效率的同时,又保证了计算的精度。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!