一种基于深度学习的信息技术数据实体属性抽取方法与流程
本发明涉及实体数据抽取技术领域,尤其涉及一种基于深度学习的信息技术数据实体属性抽取方法。
背景技术:
在信息研究领域,信息抽取技术是一项必不可少的关键技术。面对如此海量的信息空间,如何更快更准确地抽取出用户感兴趣的内容是一个迫切需要解决的问题,也是信息挖掘技术的一个重要研究方向。信息抽取不同于信息检索等信息处理技术,它需要对文本进行命名实体的识别,并抽取出实体之间的关系,而中文文本中词语的灵活多变、构词复杂且没有明显的标志,使得对中文命名实体的识别及关系的抽取就显得更加困难。目前,信息抽取的主要方法有是基于知识库算法,这种方法需要建立一些规则,虽然这种方法的准确率较高,但是这种规则的确定是比较困难的,对编写者有较高的要求,且移植性不高。
为解决上述问题,本申请中提出一种基于深度学习的信息技术数据实体属性抽取方法。
技术实现要素:
(一)发明目的
为解决背景技术中存在的信息抽取的主要方法有是基于知识库算法,这种方法需要建立一些规则,虽然这种方法的准确率较高,但是这种规则的确定是比较困难的,对编写者有较高的要求,且移植性不高的技术问题,本发明提出一种基于深度学习的信息技术数据实体属性抽取方法,通过计算机算法无需建立规则,通过对同一实体与属性赋予不同的权重,计算实体与属性之间的关联度,取关联度最高的实体属性输出。
(二)技术方案
为解决上述问题,本发明提供了一种基于深度学习的信息技术数据实体属性抽取方法,包括以下具体步骤;
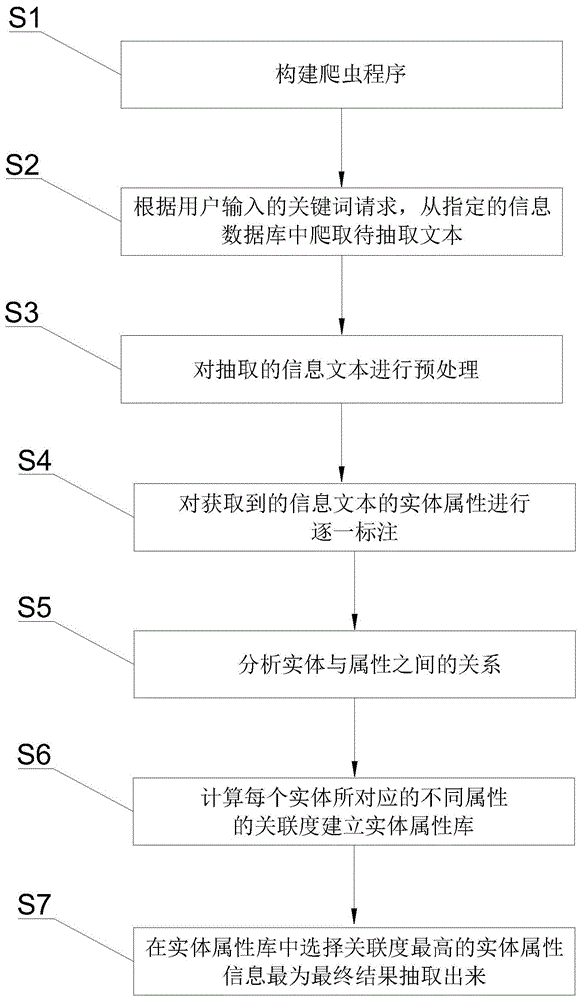
s1、构建爬虫程序;并将爬虫程序驻留在数据库服务器上;
s2、根据用户输入的关键词请求,从指定的数据库中爬取待抽取文本;
s3、对抽取的信息文本进行预处理;
s4、对获取到的信息文本的实体属性进行逐一标注;
s5、分析实体与属性之间的关系;
s6、计算每个实体所对应的不同属性的关联度,并建立实体属性库;
s7、在实体属性库中选择关联度最高的实体属性信息作为最终结果抽取出来。
优选的,根据用户输入的关键词请求,发送至数据库服务器上的爬虫程序,爬虫程序对关键词进行提取分析,选择与关键词匹配的文本。
优选的,对抽取的信息文本进行预处理包括去除所有的空格和ref标签中的内容。
优选的,对抽取的信息文本进行预处理包括去除所有的无效图片。
优选的,对抽取的信息文本进行预处理包括去除所有的重复数据。
优选的,对抽取的信息文本进行预处理包括提取信息文本中的动词,并对动词进行标注。
优选的,对信息中的动词采用向量的方式进行标注。
优选的,对实体以及与实体所对应的属性分别赋予不同的权重,根据权重的不同计算同一个实体与不同属性之间的关联度。
本发明的上述技术方案具有如下有益的技术效果:首先构建爬虫程序;并将爬虫程序驻留在数据库服务器上;用户输入关键词请求,并将请求信息发送至数据库服务器上的爬虫程序,爬虫程序对关键词进行提取分析,选择与关键词匹配的文本;之后对抽取的信息文本进行预处理,预处理过程包括去除所有的空格和ref标签中的内容、去除所有的无效图片、去除所有的重复数据和提取信息文本中的动词,并对动词进行标注;之后对获取到的信息文本的实体属性进行逐一标注,并对实体以及与实体所对应的属性分别赋予不同的权重,根据权重的不同计算同一个实体与不同属性之间的关联度;并建立实体属性库,更具实体属性关联度的高低确定优先级,选择关联度最高的实体属性信息作为最终结果抽取出来;在实际使用的过程中,用户可对抽取结果进行评分,通过用户使用频次的增加,累积不同的分值以及不同实体所对应的不同属性信息,深度学习并优化权重的赋值,实时调整通一实体与不同属性之间的关联度,并根据用户输入的关键词,抽取不同的实体属性。通过计算机算法无需建立规则,通过对同一实体与属性赋予不同的权重,计算实体与属性之间的关联度,取关联度最高的实体属性输出。
附图说明
图1为本发明提出的基于深度学习的信息技术数据实体属性抽取方法的结构示意图。
图2为本发明提出的基于深度学习的信息技术数据实体属性抽取方法中预处理方法的结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
如图1-2所示,本发明提出的一种基于深度学习的信息技术数据实体属性抽取方法,包括以下具体步骤;
s1、构建爬虫程序;并将爬虫程序驻留在数据库服务器上;
s2、根据用户输入的关键词请求,从指定的数据库中爬取待抽取文本;
s3、对抽取的信息文本进行预处理;
s4、对获取到的信息文本的实体属性进行逐一标注;
s5、分析实体与属性之间的关系;
s6、计算每个实体所对应的不同属性的关联度,并建立实体属性库;
s7、在实体属性库中选择关联度最高的实体属性信息作为最终结果抽取出来。
本发明中,首先构建爬虫程序;并将爬虫程序驻留在数据库服务器上;用户输入关键词请求,并将请求信息发送至数据库服务器上的爬虫程序,爬虫程序对关键词进行提取分析,选择与关键词匹配的文本;之后对抽取的信息文本进行预处理,预处理过程包括去除所有的空格和ref标签中的内容、去除所有的无效图片、去除所有的重复数据和提取信息文本中的动词,并对动词进行标注;之后对获取到的信息文本的实体属性进行逐一标注,并对实体以及与实体所对应的属性分别赋予不同的权重,根据权重的不同计算同一个实体与不同属性之间的关联度;并建立实体属性库,更具实体属性关联度的高低确定优先级,选择关联度最高的实体属性信息作为最终结果抽取出来;在实际使用的过程中,用户可对抽取结果进行评分,通过用户使用频次的增加,累积不同的分值以及不同实体所对应的不同属性信息,深度学习并优化权重的赋值,实时调整通一实体与不同属性之间的关联度,并根据用户输入的关键词,抽取不同的实体属性。
在一个可选的实施例中,根据用户输入的关键词请求,发送至数据库服务器上的爬虫程序,爬虫程序对关键词进行提取分析,选择与关键词匹配的文本。
在一个可选的实施例中,对抽取的信息文本进行预处理包括去除所有的空格和ref标签中的内容。
在一个可选的实施例中,对抽取的信息文本进行预处理包括去除所有的无效图片。
在一个可选的实施例中,对抽取的信息文本进行预处理包括去除所有的重复数据。
在一个可选的实施例中,对抽取的信息文本进行预处理包括提取信息文本中的动词,并对动词进行标注。
在一个可选的实施例中,对信息中的动词采用向量的方式进行标注。
在一个可选的实施例中,对实体以及与实体所对应的属性分别赋予不同的权重,根据权重的不同计算同一个实体与不同属性之间的关联度。
应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。
- 还没有人留言评论。精彩留言会获得点赞!