一种基于用户偏好相似度加权的协同过滤推荐方法与流程
本发明涉及推荐算法技术领域,尤其涉及一种基于用户偏好相似度加权的协同过滤推荐方法。
背景技术:
从目前的研究情况来看,很多学者在推荐系统中都考虑到用户偏好的影响,大部分情况都是在计算用户相似度时加权,修正用户与用户的相似度,并且取得了较大的成果。用户基于用户偏好加权的推荐算法,其基本思想是利用数据挖掘等技术对用户属性及历史偏好进行深入挖掘和分析,获取用户的偏好知识;利用获取的数据建立相应的偏好矩阵,然后根据偏好矩阵计算用户之间的相似度,最后和协同过滤的用户相似度加权从而修正用户偏好对最后推荐结果的影响,提高推荐算法的精确度。
基于用户偏好相似度加权的推荐算法在实验中相比于传统的协同过滤有一定的优化,但优化的程度有限,经过思考发现抑制其优化结果的条件有两点,偏好矩阵的构建和加权后的相似度值的修正,因此对这两点提出相应的改进,建立偏好矩阵时,不应该只统计用户评分过标签出现的次数,应该进一步考虑用户对项目的评分,因此计算标签权重是需要融入评分的影响,这样更能反映用户的偏好程度;另外一点是用户与用户之间的相似度虽然通过偏好加权的方式来修正,但是相似度只是一个中间量,后续还会根据相似度来选择近邻以及计算预测评分等,在经过一系列运算后,相似度的修正值影响度会随之下降,因此可以放弃在计算相似度的时候进项偏好加权,借鉴基于用户和项目加权的推荐算法,在最后预测评分进行加权。
技术实现要素:
本发明的目的是针对上述现有技术的不足,提供一种基于用户偏好相似度加权的协同过滤方法,将用户评分融入偏好模型,使得偏好矩阵更加具有说服力,能够扩大用户偏好对最终推荐结果的影响,从而提升推荐结果的准确性,提升系统的可信度。本发明的技术方案是:
一种基于用户偏好相似度加权的协同过滤推荐方法,具体步骤如下:
步骤1:建立用户与项目之间的评分矩阵r,从评分矩阵r中统计出用户集合,记为u={u1,u2,...,um},m表示用户集合中用户的数量,项目集合i={i1,i2,...,in},其中n表示项目数量,根据项目信息统计出所有出现过的标签集合,记为l={l1,l2,...,lg},其中g表示标签数量,用户评分为给定的一个评分区间,且满足用户评分越高,表示用户越喜欢;
步骤2:根据评分矩阵r通过标签权重计算公式计算出每一个用户u中所有项目标签l所占的权重wul,然后通过权重wul构建用户标签偏好矩阵w;
用户u喜欢的项目标签l所占的权重wul计算公式如下:
其中j表示用户u评价过的项目集合,l表示所有出现过的标签集合,cil表示在项目i中标签l出现的次数,rui表示用户u对项目i的评分,ci表示项目i中标签的总数量,tu为用户u评价过的项目总评分;
步骤3:1)对于评分矩阵r,采用余弦相似度来遍历计算评分矩阵r中每一个用户与其余用户的评分相似度,然后将遍历计算得到的所有评分相似度存入评分相似矩阵a中,评分相似度计算公式如下:
其中,s(u,v)表示用户u与用户v之间的评分相似度,(u,v)∈u且
2)对于用户标签偏好矩阵w,也采用余弦相似度来遍历计算用户标签偏好矩阵w中每一个用户与其余用户的偏好相似度,然后将遍历计算得到的所有偏好相似度存入偏好相似矩阵b中,偏好相似度计算公式如下:
其中,q(u,v)表示用户u与用户v之间的偏好相似度,(u,v)∈u且
步骤4:方法一,将评分相似矩阵a中每一行的所有评分相似度按照从大到小排序,然后取前k个用户作为用户u的近邻用户集合,记为nu,其中0<k<m,m表示用户集合u中用户的数量,所述的通过评分相似矩阵a计算得到的近邻用户集合nu中的评分相似度满足s(u,u1)≥s(u,u2)≥...≥s(u,uσ)...≥s(u,uk),其中uσ∈nu,0<σ<k;方法二,将偏好相似矩阵b中每一行的所有偏好相似度按照从大到小排序,然后取前k个用户作为用户u的近邻用户集合,记为pnu,其中0<k<m,m表示用户集合u中用户的数量,所述的通过偏好相似矩阵b计算得到的近邻用户集合pnu中的偏好相似度满足q(u,u1)≥q(u,u2)≥...≥q(u,uσ)...≥q(u,uk),其中uσ∈pnu,0<σ<k;通过所述两种方法计算之后,最后每一个用户都会存在一个通过评分相似矩阵a计算得到的近邻用户集合nu和通过偏好相似矩阵b计算得到的近邻用户集合pnu;
步骤5:首先通过评分相似矩阵a计算得到的近邻用户集合nu来计算基于用户的协同过滤预测评分pr(u,i),其中u∈u,i∈i,u表示所有用户的集合,i表示项目集合,通过偏好相似矩阵b计算得到的近邻用户集合pnu来计算基于用户偏好的预测评分pp(u,i),其中u∈u,i∈i,u表示所有用户的集合,i表示项目集合,然后将通过评分相似矩阵a计算得到的近邻用户集合nu计算求得的协同过滤预测评分pr(u,i)与通过偏好相似矩阵b计算得到的近邻用户集合pnu计算求得的基于用户偏好的预测评分pp(u,i)采用线性加权的方式计算,最后得出用户u对项目i的最终预测评分p(u,i)。
所述的协同过滤预测评分pr(u,i)的计算公式如下:
其中,
所述的基于用户偏好的预测评分pp(u,i)的计算公式如下:
其中,
所述的线性加权计算公式如下:
p(u,i)=wppp(u,i)+(1-wp)pr(u,i)
其中,wp表示用户可结合自己需要调整的权重因子,pr(u,i)表示所述的协同过滤预测评分,pp(u,i)表示所述的基于用户偏好的预测评分。
附图说明
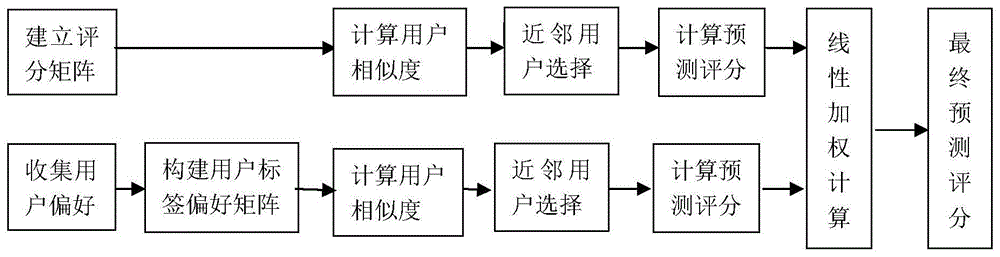
图1为基于用户偏好相似度加权的协同过滤推荐方法示意图。
图2为本发明实施例提供的计算用户标签偏好矩阵的原理图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
如图1基于用户偏好相似度加权的协同过滤推荐方法示意图所示,一种基于用户偏好相似度加权的协同过滤推荐方法,具体步骤如下:
步骤1:建立用户与项目之间的评分矩阵r,从评分矩阵r中统计出用户集合u={u1,u2,...,um},u表示目标用户,m表示用户集合中用户的数量,项目集合i={i1,i2,...,in},其中n表示项目数量。根据项目信息可以统计出所有出现过的标签集合,记为l={l1,l2,...,lg},其中g表示标签数量,用户评分为1-5分,分值代表用户对项目的喜欢程度,分值越高用户越喜欢这个项目;
步骤2:根据评分矩阵r通过标签权重计算公式计算出每一个用户中所有项目标签所占的权重wul,然后通过所述权重wul构建用户标签偏好矩阵w,其中用户u喜欢的项目标签l所占的权重wul为:
式中j表示用户u评价过的项目集合,l表示所有出现过的标签集合,cil表示在项目i中标签l出现的次数,rui表示用户u对项目i的评分,ci表示项目i中标签的总数量,tu为用户u评价过的项目总评分,如图2本发明实施例提供的计算用户标签偏好矩阵的原理图所示,假设用户对项目i1,i2,i3有过评分,分别为5分,4分,3分,而项目i1有一个标签,项目i2有两个标签,项目i3有三个标签,由此可知将项目评分平均分配到所属标签,然后就可以统计出每一个标签所占的权重,其中标签l1所占比重为0.5,标签l2所占比重为0.25,以此类推可以计算所有标签,根据所占权重的大小可以得知用户比较喜欢标签l2类型的项目。
步骤3:1)首先采用余弦相似度来遍历计算评分矩阵r中的每一个用户与其余用户的评分相似度,然后将遍历计算得到的所有评分相似度存入评分相似矩阵a中,例如评分相似矩阵a中用户u与用户v之间的评分相似度为:
其中(u,v)∈u且
2)然后采用余弦相似度来遍历计算偏好相似矩阵w中每一个用户与其余用户的偏好相似度,然后将遍历计算得到的所有偏好相似度存入偏好相似矩阵b中,例如偏好相似矩阵b中用户u与用户v之间的偏好相似度为:
其中(u,v)∈u且
步骤4:通过下面的两种方法来建立每个用户的近邻用户集合:方法一,将评分相似矩阵a中每一行的所有评分相似度按照从大到小排序,然后取前k个用户作为用户u的近邻用户集合,记为nu,其中0<k<m,m表示用户集合u中用户的数量,所述的通过评分相似矩阵a计算得到的近邻用户集合nu中的评分相似度满足s(u,u1)≥s(u,u2)≥...≥s(u,uσ)...≥s(u,uk),其中uσ∈nu,0<σ<k;方法二,将偏好相似矩阵b中每一行的所有偏好相似度按照从大到小排序,然后取前k个用户作为用户u的近邻用户集合,记为pnu,其中0<k<m,m表示用户集合u中用户的数量,所述的通过偏好相似矩阵b计算得到的近邻用户集合pnu中的偏好相似度满足q(u,u1)≥q(u,u2)≥...≥q(u,uσ)...≥q(u,uk),其中uσ∈pnu,0<σ<k;通过所述两种方法计算之后,最后每一个用户都会存在一个通过评分相似矩阵a计算得到的近邻用户集合nu和通过偏好相似矩阵b计算得到的近邻用户集合pnu;
步骤5:首先利用公式(1)计算基于用户的协同过滤预测评分pr(u,i),利用公式(2)计算基于用户偏好的预测评分pp(u,i),然后将协同过滤预测评分pr(u,i)与基于用户偏好的预测评分pp(u,i)采用公式(3)计算得出用户u对项目i的最终预测评分p(u,i)。
其中,
其中,
p(u,i)=wppp(u,i)+(1-wp)pr(u,i)(3)
其中,wp表示用户可结合自己需要调整的权重因子。
- 还没有人留言评论。精彩留言会获得点赞!