一种对抗性环境中最优攻击样本获取方法与流程
本发明涉及一种病毒样本获取方法,具体的说是一种病毒攻击样本获取方法,属于人工智能技术领域。
背景技术:
对抗机器学习技术可以简单理解为用机器学习技术“对抗”机器学习技术,是让攻击者利用机器学习技术不断包装攻击样本,以达到在样本仍具攻击性的情况下通过检测的结果,进而从另一方面促进机器的防御性能的提高。这项技术是机器学习的一个全新角度,是一种开创性的方法,各项研究还处于较为初始的阶段,但仍被证明具有较为广阔的应用前景与利用价值,非常值得研究。
现今机器学习行业十分火热,机器学习技术的应用已遍及人工智能的各个领域,例如:数据挖掘、计算机视觉、自然语言处理、生物特征识别、搜索引擎、医学诊断、检测信用卡欺诈、证券市场分析、dna序列测序、语音和手写识别、战略游戏和机器人运用等。
目前,在机器学习的大规模应用中,往往是从“需求”出发,探究在一个特定的环境或场景下,通过机器学习改善具体算法的性能,使得计算机具有“自主学习”或“自我优化”的能力。
但是,机器学习也同样可以从相反方向进行应用,从而检测具体算法的性能与安全性,达到对算法进行优化的作用与目的。这方面的研究与专利都不多,各项研究都刚刚开始,所以一个在对抗机器学习方向上的对抗性攻击方法的提出是有必要的。
针对现今已有一些pdf恶意软件检验器,如pdfrate和hidost等,存在着一些分类器(恶意文件)的逃避方法。但是,因为这些逃避方法只能按照设定完成程序所有内容判断是否能产生“逃逸成功”的样本,而无法在程序结束后将“毒性”最强的病毒样本挑选出来,同时,它们对于恶意pdf的检测率也较低,很多恶意pdf仍然能够逃脱它们的检测,所以它们对于安全方面的贡献仍然不够。
因此,为方便提高基于学习的系统的安全性能,一种挑选最优攻击样本的方法有待提出。
现有技术一
申请号cn201780041400公开了一种对抗性环境分类器训练系统,用于识别包括在多个样本的初始数据集中的每个样本相关联的多个特征。
现有技术一的缺点:现有技术一仅考虑到了与所需特征信息相互冲突或相互影响的信息,并未考虑信息本身在接收时的文件安全性以及对接收设备可能造成的影响。同时,现有技术一采用机器学习电路进行控制耦合,在实际生产应用在造价与便捷程度上会受到一定的制约。本发明从文档自身的安全性角度出发,通过程序设计与自动控制实现整个检测流程的自动化,并通过各个独立项目上云或联网处理,极大地加快了检验速度,缩短了应用时间,降低了应用的设备需求。
技术实现要素:
本发明的目的是提供一种对抗性环境中最优攻击样本获取方法,通过存储生成的所有符合条件的样本,并根据样本的恶意程度的不同通过回溯法进行横向比较,挑选出恶意程度值最高的样本作为最终的目标样本。
本发明的目的是这样实现的:一种对抗性环境中最优攻击样本获取方法,包括以下步骤:
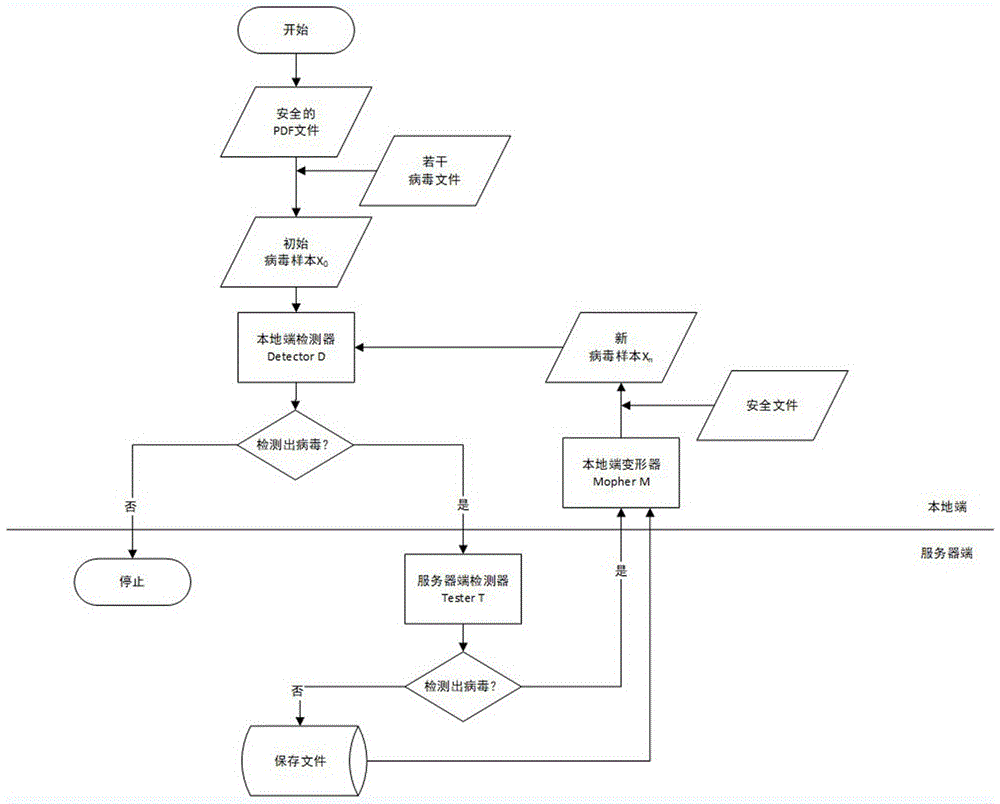
步骤一:将一个安全的pdf文件与若干病毒文件合成为一个新的pdf文件作为初始的病毒样本;
步骤二:将病毒样本送入本地端检测器检测;
步骤三:若本地端检测器检测出病毒,则将该病毒样本送入服务器端检测器检测,若检测不出病毒,则结束整个流程;
步骤四:若服务器端没有检测出病毒,则将该病毒样本保存,若服务器端检测器检测出病毒,则直接进行步骤五;
步骤五:将该病毒样本送入本地端的变形器进行变形,生成新病毒样本,并将其送入步骤二再次进行循环;
步骤六:在整个流程结束时,若服务器端没有保存病毒样本,则说明该过程并未得到最优攻击样本,若服务器端有保存病毒样本,则选择步骤三结束前服务器端最后一次保存的病毒样本作为最优攻击样本。
pdfpdf在整个流程结束时,若服务器端没有保存病毒样本作为本发明的进一步限定,所述步骤一还包括:初始病毒样本合成时,病毒文件会插入到pdf文件的任意位置;初始的病毒样本中所含有的病毒文件数量是随机的,且数量不为零。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:本发明解决了在对抗机器学习领域对于样本本身的安全性的判定,提出了对于“毒性最强”的样本的选取方法:通过存储生成的所有符合条件的样本,并根据样本的恶意程度的不同通过回溯法进行横向比较,挑选出恶意程度值最高的样本作为最终的目标样本。
附图说明
图1为本发明流程图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
如图1所示,一种对抗性环境中最优攻击样本获取方法,包括以下步骤:
步骤一:将一个安全的pdf文件与若干病毒文件合成为一个新的pdf文件作为初始的病毒样本x0,初始病毒样本合成时,病毒文件会插入到pdf文件的任意位置,初始的病毒样本中所含有的病毒文件数量是随机的,且数量不为零;
初始样本x0的合成是变形与生成目标样本的前提,本发明使用解析器,生成一个携带病毒文件的初始样本,如pdfrw等;
pdfrw是一个用来读取和写入pdf文件的python库和工具,可进行包括裁剪、合并、旋转、修改元数据在内的多项操作,是一种可用的快速纯pythonpdf解析器;基于此工具,我们制作了一个插件morpherm,来解析一些非正确格式的pdf文件,尤其是恶意文件。
步骤二:将病毒样本送入本地端检测器检测;
mimicus-master是我们制作的一款基于最新结构特征的pdf检测工具,相较于常用的两款现有的检测工具pdfrate与hidost,它对于目前的数据集具有最好的通过率,我们将这个工具作为本地端检测器detectord,将上述文件送入所述pdf检测工具进行检测。
步骤三:若本地端检测器检测出病毒,则将该病毒样本送入服务器端检测器检测,若本地端检测器检测不出病毒,则结束整个流程。
步骤四:若服务器端没有检测出病毒,则将该病毒样本保存,若服务器端检测器检测出病毒,则直接进行步骤五;
在此步骤中,我们利用服务器端检测器testert来判定样本x是否具有恶意功能,以及它的危害性大小。服务器端检测器testert是用开源程序cuckoosandbox(杜鹃沙箱)等进行改造的;
cuckoosandbox(杜鹃沙箱)是一款完全开源的自动恶意软件分析工具,它可在独立、真实的环境下自动分析windows、osx、linux和android下的任何恶意文件,并在几分钟内对给出的文件提供详细的报告,用以概述文件的行为。
步骤五:将该病毒样本送入本地端的变形器morpherm进行变形,生成新病毒样本xn,并将其重新送入步骤二再次进行整个循环;
在此步骤中,我们利用morpherm作为本地端变形器对文件进行变形操作,向其中随机插入安全文件,进而生成一个新的样本文件xn,插入安全文件的位置也同样是随机的。
步骤六:在整个流程结束时,在整个流程结束时,若服务器端没有保存病毒样本,则说明该过程并未得到最优攻击样本,若服务器端有保存病毒样本,则选择步骤三结束前服务器端最后一次保存的病毒样本作为最优攻击样本。
在整个流程结束时,若服务器端没有保存病毒样本以上所述,仅为本发明中的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉该技术的人在本发明所揭露的技术范围内,可理解想到的变换或替换,都应涵盖在本发明的包含范围之内,因此,本发明的保护范围应该以权利要求书的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!